一周1.2k星!兼具质量与效率的OCR模型MonkeyOCR,支持多样化的中英文PDF
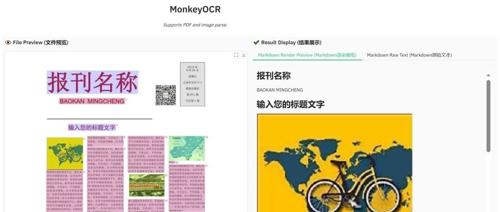
MonkeyOCR采用结构-识别-关系(SRR)范式提升文档解析性能,相比MinerU和端到端模型,在九种文档上的表现均有提升。它支持快速开始安装、推理等步骤,并提供了多种示例文档展示效果。
MonkeyOCR采用结构-识别-关系(SRR)范式提升文档解析性能,相比MinerU和端到端模型,在九种文档上的表现均有提升。它支持快速开始安装、推理等步骤,并提供了多种示例文档展示效果。
BilldDesk 支持多设备远程控制及屏幕墙功能,画质限制最高1080p,30帧。ToDesk免费版月使用时长和控制次数有限制。
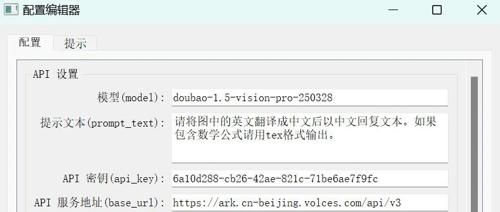
通过截图操作发送图片至AI模型进行文本识别和翻译,支持自定义快捷键、多窗口结果管理及系统托盘运行。极大提升日常翻译效率,解决文档臃肿、公式复制问题等痛点。

Lemon 是一款开源通用智能体,能够自动化完成市场调研、金融分析等复杂任务。它具备自主性,可根据目标独立执行任务,并实时监控进度。支持自定义模型接入和在线模型接入。

自动化 MCP 是一个模型上下文协议服务器,为AI模型提供完整的 macOS 桌面自动化能力,包括控制鼠标、输入键盘指令、截取屏幕截图及分析内容等。

语义搜索
和
亚秒级检索速度
。与传统向量数据库消耗大量内存和存储不同,Memvid将知识库压缩为紧