真正意义的开源AI浏览器,打开的100个标签页终于有救了。

Nxtscape是一个开源的智能浏览器,提供本地运行AI代理、隐私保护和广告拦截等功能。界面类似Google Chrome且兼容所有扩展程序。
Nxtscape是一个开源的智能浏览器,提供本地运行AI代理、隐私保护和广告拦截等功能。界面类似Google Chrome且兼容所有扩展程序。
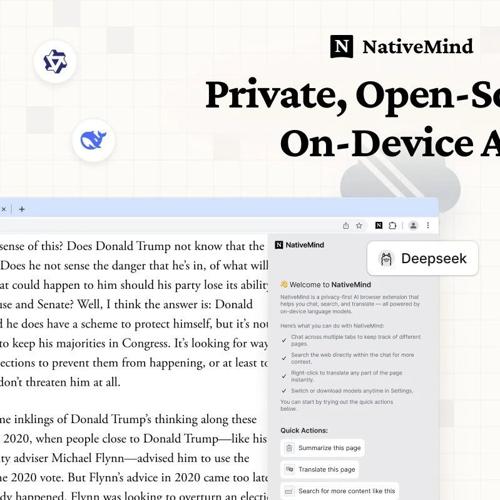
GitHub 上推出的 NativeMind 浏览器插件支持 Ollama 和 WebLLM 模型调用,实现本地化运行和数据隐私保护,提供智能对话、内容分析等多款功能。
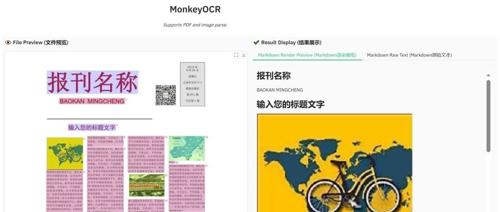
MonkeyOCR采用结构-识别-关系(SRR)范式提升文档解析性能,相比MinerU和端到端模型,在九种文档上的表现均有提升。它支持快速开始安装、推理等步骤,并提供了多种示例文档展示效果。

Ollama 是一个简便的工具,通过经典的客户端-服务器架构实现快速运行大语言模型。其核心组件包括 ollama-http-server 和 llama.cpp,后者负责加载并运行大语言模型。用户通过命令行与 Ollama 进行对话,处理流程涉及准备阶段和交互式对话阶段。

本文介绍了如何使用LangGraph、MCP和Ollama构建一个多智能体聊天机器人,并详细解释了函数调用和MCP的区别及其应用场景。

构建 RAG 系统利用 DeepSeek R1 和 Ollama 提升知识问答、信息检索和内容创作能力,涵盖环境设置、核心流程、优化策略和最佳实践。

通过Ollama在本地安装、设置并运行QwQ-32B模型,学习如何使用Gradio创建一个逻辑推理助手。QwQ-32B具有高效运行和隐私保护等优势。