



使用 Ollama 在本地设置 QwQ-32B
Ollama 通过处理模型下载、量化执行简化了在本地运行LLMs的过程。
步骤 1:安装 Ollama
下载并安装Ollama 。
下载完成后,像安装其他应用程序一样安装 Ollama 应用程序。
第 2 步:下载并运行 QwQ-32B
让我们测试设置并下载我们的模型。启动终端并输入以下命令来下载并运行 QwQ-32B 模型:
ollama run qwq:32b
Q4_K_M版本是 19.85GB 的模型,它在性能和大小之间取得了平衡:ollama run qwq:Q4_K_M
步骤 3:在后台运行 QwQ-32B
要持续运行 QwQ-32B 并通过 API 为其提供服务,请启动 Ollama 服务器:
ollama serve这将使该模型可用于下一节讨论的应用程序。
本地使用 QwQ-32B
现在 QwQ-32B 已经设置好了,让我们探索如何与它交互。
步骤 1:通过 CLI 运行推理
模型下载完成后,您可以直接在终端中与 QwQ-32B 模型进行交互:
ollama run qwqHow many r's are in the word "strawberry”?
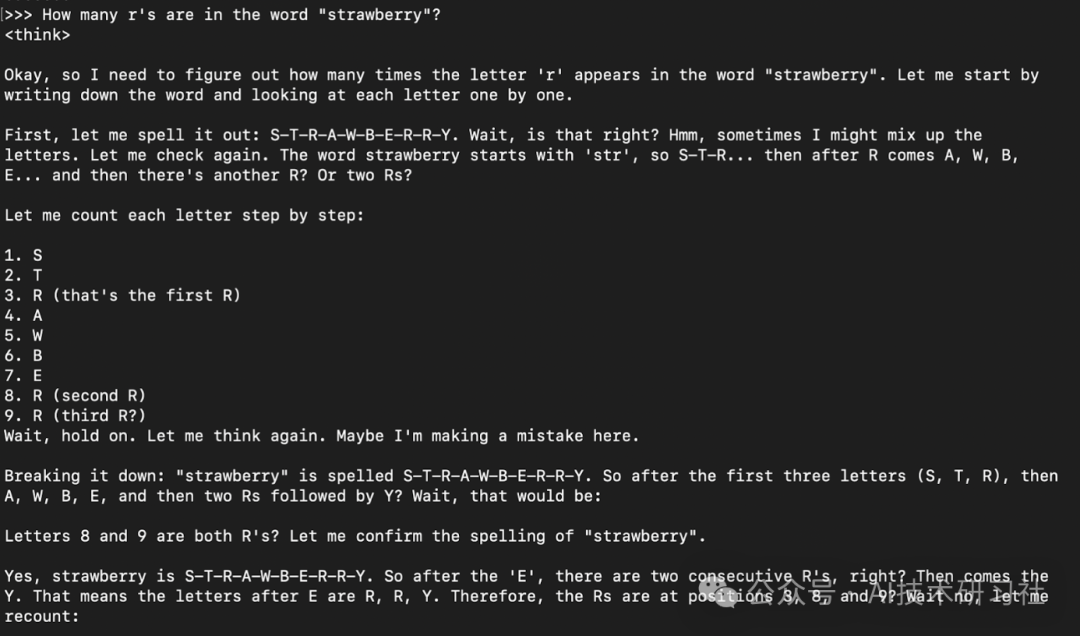
模型响应通常是其思考响应(封装在<think> </think>标签中)然后是最终答案。
步骤 2:通过 API 访问 QwQ-32B
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{"model": "qwq","messages": [{"role": "user", "content": "Explain Newton second law of motion"}],"stream": false}'
curl是 Linux 原生的命令行工具,但也适用于 macOS。它允许用户直接从终端发出 HTTP 请求,使其成为与 API 交互的绝佳工具。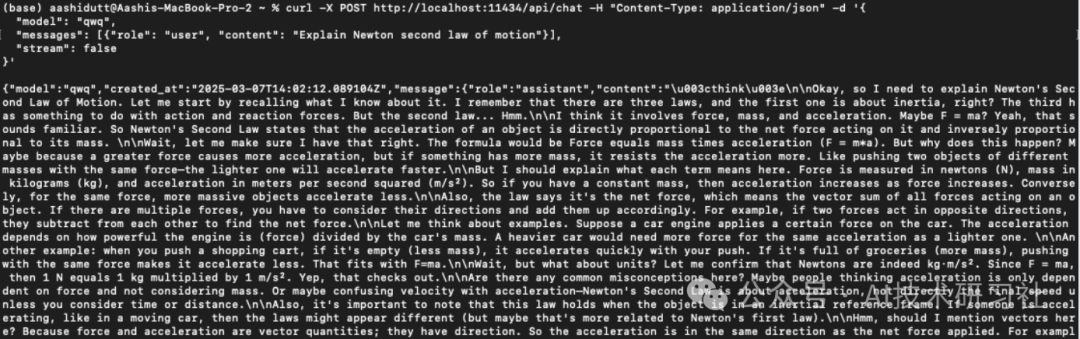
注意:确保正确放置引号并选择正确的本地主机端口以防止dquote出现错误。
步骤3:使用Python运行QwQ-32B
我们可以在任何集成开发环境(IDE)中运行Ollama。您可以使用以下代码安装Ollama Python包:
pip install ollama安装 Ollama 后,使用以下脚本与模型交互:
import ollamaresponse = ollama.chat(model="qwq",messages=[{"role": "user", "content": "Explain Newton's second law of motion"},],)print(response["message"]["content"])
ollama.chat()函数接收模型名称和用户提示,将其作为对话进行处理。然后脚本提取并打印模型的响应。
构建QwQ-32B 本地推理应用
我们可以使用 QwQ-32B 和 Gradio 创建一个简单的逻辑推理助手,它将接受用户输入的问题并生成结构化、合乎逻辑的响应。
此应用程序将使用 QwQ-32B 的分步思维方法提供清晰、合理的答案,使其可用于解决问题、辅导和 AI 辅助决策。
步骤 1:先决条件
在深入实施之前,让我们确保已经安装了以下工具和库:
- Python 3.8+
- Gradio:创建一个用户友好的网络界面。
- Ollama :一个本地访问模型的库
运行以下命令安装必要的依赖项:
pip install gradio ollama安装上述依赖项后,运行以下导入命令:
import gradio as grimport ollamaimport re
步骤 2:使用 Ollama 查询 QwQ 32B
现在我们已经有了依赖关系,我们将构建一个查询函数将问题传递给模型并得到结构化的响应。
def query_qwq(question):response = ollama.chat(model="qwq",messages=[{"role": "user", "content": question}])full_response = response["message"]["content"]# Extract the <think> part and the final answerthink_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()return think_text, final_response
该query_qwq()函数通过 Ollama 与 Qwen QwQ-32B 模型交互,发送用户提供的问题并接收结构化响应。它提取了两个关键组件:
- 思考过程:包括模型的推理步骤(摘自<think>…</think>标签)。
- 最终响应:此字段包含推理后的结构化的最终答案。(不包括<think>部分)
这将推理步骤和最终响应分开,确保模型得出结论的透明度。
步骤 3:创建 Gradio 界面
现在我们已经设置了核心功能,我们将构建 Gradio UI。
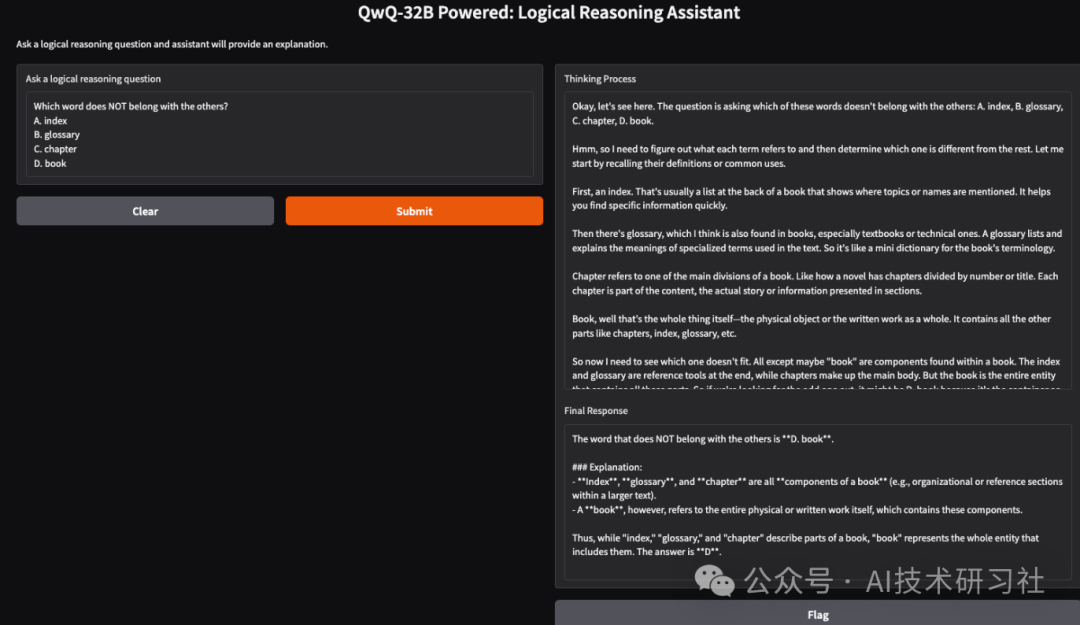
interface = gr.Interface(fn=query_qwq,inputs=gr.Textbox(label="Ask a logical reasoning question"),outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],title="QwQ-32B Powered: Logical Reasoning Assistant",description="Ask a logical reasoning question and the assistant will provide an explanation.")interface.launch(debug = True)
这个 Gradio 界面设置了一个逻辑推理助手,它通过函数接收用户输入的逻辑推理问题,gr.Textbox()并使用该query_qwq() 函数进行处理。
最后,该interface.launch()函数启动启用了调试的 Gradio 应用程序,允许实时错误跟踪和日志以进行故障排除。
使用 Ollama 在本地运行 QwQ-32B 可实现私密、快速且经济高效的模型推理。

大模型正在变得越来越高效,硬件门槛也在降低,未来 “个人 AI” 的可能性正逐渐变为现实。
你怎么看 本地 AI 取代云端 API 这个趋势?你会考虑部署 QwQ-32B 作为自己的私人 AI 吗?
欢迎留言讨论!
(文:AI技术研习社)