
多模态大模型

35%准确率蒸发!字节&华科WildDoc揭示多模态文档理解鲁棒性短板

多模态大模型在文档理解领域的性能显著,但现有基准存在真实场景挑战。字节跳动联合华中科技大学发布首个真实世界文档理解基准数据集WildDoc,揭示了当前模型的不足,并提出改进策略。
上海AI实验室造出首个「通才」机器人大脑:看懂世界+空间推理+精准操控全拿下

上海人工智能实验室联合多家单位提出了一种名为VeBrain的新模型,该模型通过统一感知、推理和控制建模方式实现了多模态大模型对物理实体的直接操控。它在视觉感知、空间推理和机器人控制方面均表现卓越,并且与现有模型相比,在多个基准测试中表现出最佳性能。
全面评估多模态模型视频OCR能力,Gemini 准确率仅73.7%

MME-VideoOCR团队评估MLLM在视频OCR中的能力,构建精细任务体系和高质量数据集,揭示了当前模型的局限性,并提出了优化建议。


字节开源了一款多模态神器!BAGEL上线,超越Qwen2.5-VL,媲美SD3!
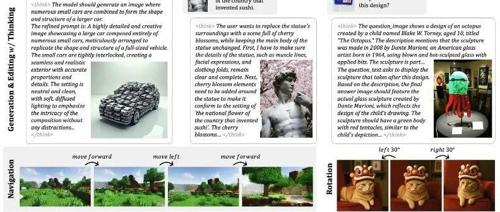
字节跳动发布的BAGEL是首个支持多模态输入输出、思维链推理和MOT架构优化的跨模态超级AI模型,性能超越Qwen2.5-VL、InternVL-2.5。它能理解图像更准确,生成图像媲美Stable Diffusion 3,并在10+基准测试中表现优异。
75万元奖金池+心动offer,启元实验室2025重磅赛事来袭,三大赛道,等你来战!

启元实验室启动”启智杯”算法大赛,聚焦卫星遥感图像、无人机目标检测和多模态大模型对抗三大方向。大赛设立75万元奖金池,面向研究机构、企事业单位等开放参赛。
ICML 2025 长视频理解新SOTA!蚂蚁&人大开源ViLAMP-7B,单卡可处理3小时视频
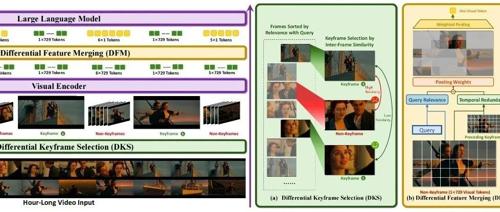
蚂蚁和中国人民大学的研究团队提出ViLAMP模型,实现对超长视频的高效处理。ViLAMP通过混合精度策略,在关键帧上保持高精度分析,大幅提升了视频理解效率,并在多个基准测试中超越现有方案。
