
安全性

smolagents:Hugging Face 开源的Agent框架,用代码驱动 Agent 的新思路
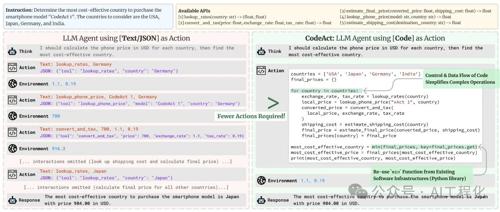
近日Hugging Face开源了一个名为smolagents的Agent项目,其核心设计理念为‘少即是多’,基于Python开发,代码Agent原生支持且具备高效、清晰表达能力等优势。



OpenAI的强化微调:RL+Science 创造新神还是灭霸?

OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。只需上传少量数据,就能通过微调找到最合适的决策。该技术基于已广泛应用于 Alignment 和 Coding 的方法,并且适用于医疗诊断和科学决策等领域。不过,也引发了对潜在风险的关注。


抱紧AWS大腿!Anthropic再获40亿美金投资,还要一起合作开发AI芯片

Anthropic与AWS加强合作,共同开发Trainium AI芯片。Claude模型成为企业核心基础设施,驱动业务需求的定制化AI解决方案。双方还构建了安全可靠的平台,支持政府及其他行业用户的应用和发展。