
OCR推理大模型全军覆没?OCR-Reasoning基准揭示多模态大模型推理短板

近期多模态推理模型在数学题、学科题上表现出色,但OCR相关复杂任务的评测标准缺失。填补这一空白的是OCR-Reasoning基准,首次系统性检验了MLLMs在复杂文本图像推理中的能力。
近期多模态推理模型在数学题、学科题上表现出色,但OCR相关复杂任务的评测标准缺失。填补这一空白的是OCR-Reasoning基准,首次系统性检验了MLLMs在复杂文本图像推理中的能力。
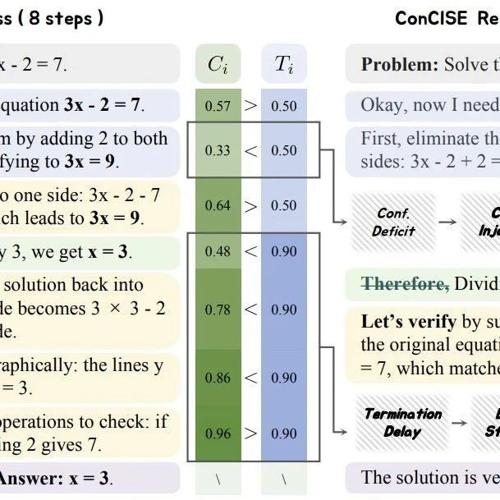
MLNLP社区是国内外知名的机器学习与自然语言处理社区。该社区致力于促进学术界、产业界和爱好者的交流与进步,特别是初学者的成长。最新研究表明,通过信心注入和早停机制,可以显著减少模型的冗余推理步骤,提高准确性而不影响性能。

斯坦福大学研究表明,在更换数学题变量名称后,大模型的准确率直线下降。即使是表现最好的o1-preview模型,其准确率也从50%降至33.96%,表明它们可能更多依赖已存储的答案而非推理能力。团队提出Putnam-AXIOM。该基准解决了现有评估基准数据污染和饱和的问题,为自动化评估提供方法并生成变体数据集。


