
谷歌再次创造历史:Gemini 2.5 Pro 通关《宝可梦:蓝》!

谷歌Gemini 2.5 Pro模型成功通关经典游戏《宝可梦:蓝》。软件工程师Joel Z搭建系统连接模拟器,通过分析内存信息自主决策玩游戏。项目强调不是基准测试,而是展示不同AI的思考方式差异。
谷歌Gemini 2.5 Pro模型成功通关经典游戏《宝可梦:蓝》。软件工程师Joel Z搭建系统连接模拟器,通过分析内存信息自主决策玩游戏。项目强调不是基准测试,而是展示不同AI的思考方式差异。
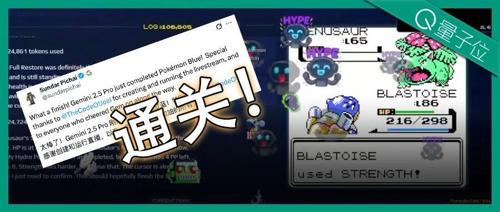
谷歌CEO劈柴哥宣布大模型Gemini成功通关《宝可梦蓝》,成为首个登顶的大型语言模型。Gemini在游戏过程中详细思考每个步骤,展示了其理解游戏的能力和局限性。

北大联合人工智能研究院等推出全新物理评测基准PHYBench,包含500道高质量物理题目,旨在评估大模型在物理感知与推理方面的表现,并通过创新的EED评分机制揭示前沿模型与人类专家之间的差距。

近日,谷歌Gemini 2.5 Pro在PDF文档解析方面取得突破,能够全面理解其布局,引发人机协作模式和生产关系变革。这将催生新型出版、教育和司法系统应用,但也带来格式依赖风险、视觉霸权隐患及元数据黑洞等问题。
Cursor 0.49 版本发布,新增智能规则生成、聊天历史访问优化、代码审查改进等新功能。支持图片上下文传递及终端控制增强,全局忽略文件和多模型支持升级。

谷歌新模型Gemini 2.5 Flash在高尔顿板测试中表现出色,击败多个AI模型。其性能超越Gemini 2.5 Pro,并被认为是对AI编码的重大突破。

谷歌Gemini 2.5 Pro在多语言编程基准测试中表现优异,性价比最优,引发广泛关注。近期又曝光了更强的模型Dragontail,在Web开发领域表现出色,有望进一步提升谷歌在AI领域的领先地位。

谷歌Deep Research搭载Gemini 2.5 Pro模型升级,显著提升分析、推理和报告生成能力。仅需19.99美元即可体验新功能。4分钟内完成46页学术论文和10分钟播客的转换。性能超OpenAI DR40%,价格仅为其十分之一。

本周,多个顶级语言模型被测试用于生成前端开发的优秀页面。最终结果显示,DeepSeek V3-0324的表现最为出色,虽然Claude 3.7 Sonnet在代码质量方面表现出色,但DeepSeek V3-0324在全面性方面更胜一筹。
