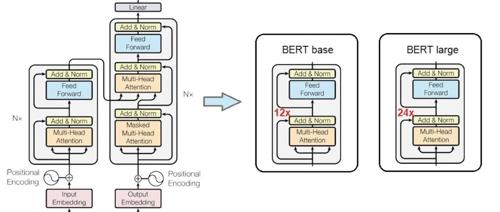
Transformer八周年!Attention Is All You Need被引破18万封神

新智元报道
编辑:定慧
【新智元导读】
Transformer已满8岁,革命性论文《Attention Is All You Need》被引超18万次,掀起生成式AI革命。
Transformer催生了ChatGPT、Gemini、Claude等诸多前沿产品。它让人类真正跨入了生成式AI时代。
这篇论文的被引次数已经达到了184376!
尽管当年未获「Attention」,但如今Transformer影响仍在继续。
谷歌开始收回对大模型开放使用的「善意」。
人人都爱Transformer,成为严肃学界乐此不疲的玩梗素材。