
DeepSeek-R1解读:纯强化学习,模型推理能力提升的新范式?

LLM模型通过纯强化学习提升推理能力,并提出无需监督数据的新方法。端侧模型性能提升主要依赖蒸馏而非强化学习,DeepSeek-R1-Zero展示了自我进化能力及语言一致性奖励的应用。
LLM模型通过纯强化学习提升推理能力,并提出无需监督数据的新方法。端侧模型性能提升主要依赖蒸馏而非强化学习,DeepSeek-R1-Zero展示了自我进化能力及语言一致性奖励的应用。

几天内DeepSeek用户量激增,登顶中国和美国苹果应用商店免费榜单。该开源大模型R1效果媲美顶尖闭源模型且价格便宜,已成Hugging Face下载量最高的大模型之一。公司开出百万年薪招聘人才,强调核心岗位多由应届生担任,团队成员来自国内顶级高校,拥有年轻活力标签。

Deepseek公司仅用2048块显卡训练出媲美顶级模型的Deepseek-V3,打破美国资源限制并选择开源路线。这改变了AI竞争规则,推动中美在AI研发开放性和技术效率上的不同方向发展。

阿里开源Android应用MnnLlmApp支持多种LLM在手机上离线运行,包括Qwen、Gemma等。CPU性能优秀,预填充速度和解码速度快出数倍。
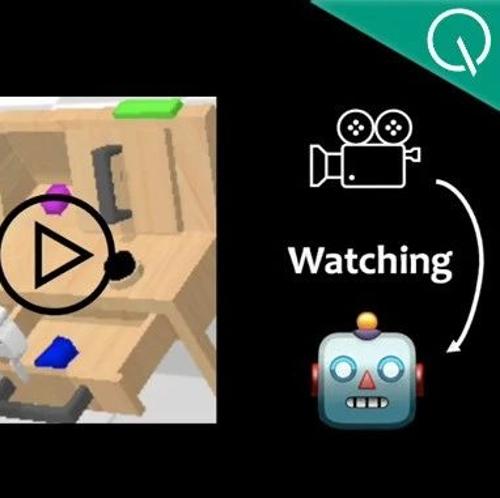
一种名为VideoWorld的模型无需依赖语言模型,仅通过视觉信号学习知识、认知世界,并能执行复杂任务。它利用潜在动态模型高效压缩视频帧间的视觉变化信息,显著提升知识学习效率和效果。

2025 GDC全球开发者先锋大会即将在上海举办,涵盖大模型、元宇宙、机器人等应用场景。大会将发布多项重要成果,吸引科技界大神和重量级嘉宾参与,提供产业合作、融资对接及社区活动机会。

DeepSeek R1因其透明化推理功能在社交媒体上引发广泛关注,并迅速登上中国和美国AppStore免费榜第一。其深度思考模式不仅提供答案还揭示了AI的思维过程,使用户能够学习如何拆解复杂问题。同时接入联网搜索功能增强了分析能力,展示了AI系统的强大潜力及其对人类认知边界的挑战。
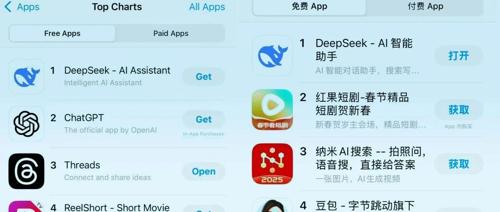
DeepSeek在美区和中国区App Store免费榜上超越ChatGPT并获得好评。其模型在多项测试中表现优异,特别适合教育领域使用。DeepSeek-R1具有高性价比、技术创新及开源特性,能够提供深度思考过程的细致回答,并且能辅助教师或家长出题,但识别能力有待提升。

阿里云Qwen模型首次将上下文扩展至1M长度,实现了长文本任务的稳定超越GPT-4o-mini,并提升了推理速度7倍。该模型分为长上下文训练、长度外推和稀疏注意力机制三大步骤。
