
FlashMLA,这是DeepSeek专为英伟达Hopper GPU打造的高效MLA解码内核,特别针对变长序列进行了优化,目前已正式投产使用。
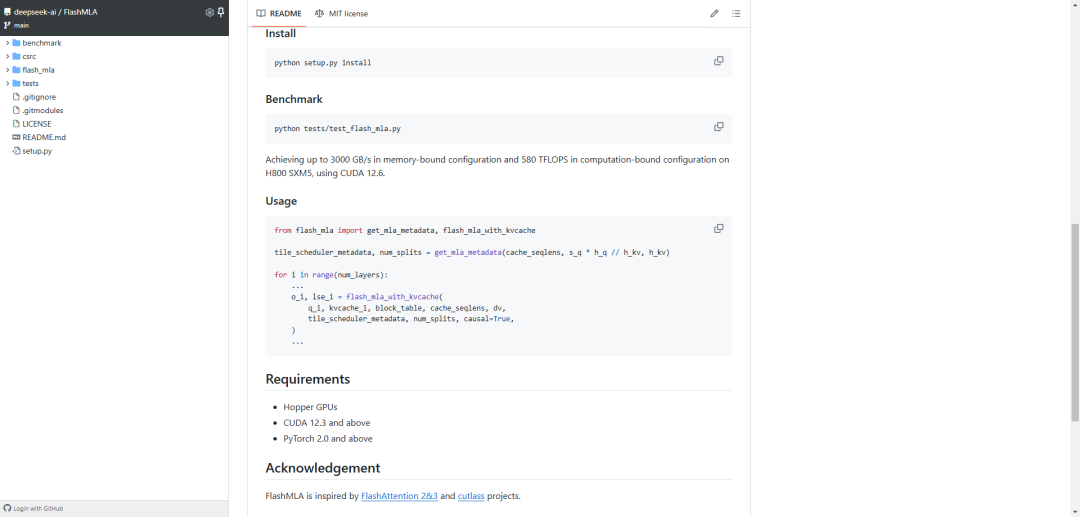
经实测,FlashMLA在H800 SXM5平台上(CUDA 12.6),在内存受限配置下可达最高3000GB/s,在计算受限配置下可达峰值580 TFLOPS。
当前已经发布的内容为:对BF16精度的支持,块大小为64的分页KV缓存
团队在致谢部分表示,FlashMLA的设计参考了FlashAttention-2、FlashAttention-3以及CUTLASS的技术实现。
参考文献:
[1] https://github.com/deepseek-ai/FlashMLA
(文:NLP工程化)