
FlashMLA,这是DeepSeek专为英伟达Hopper GPU打造的高效MLA解码内核
FlashMLA是DeepSeek专为英伟达Hopper GPU打造的高效MLA解码内核,已在多个配置下实现高吞吐量和峰值性能。
FlashMLA是DeepSeek专为英伟达Hopper GPU打造的高效MLA解码内核,已在多个配置下实现高吞吐量和峰值性能。

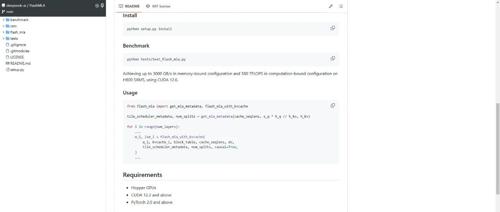
DeepSeek开源了FlashMLA,这是一个为Hopper GPU开发的高效MLA解码内核,已投入生产使用,支持BF16和分页KV缓存(块大小64),在H800上可实现高达580 TFLOPS的计算性能。

首个开源代码库FlashMLA针对英伟达Hopper架构GPU优化,支持BF16数据类型和分页KV缓存,提供高性能计算与内存吞吐,在内存限制配置下推理性能提升2-3倍,计算限制配置下提升约2倍。
DeepSeek本周开源了一款用于Hopper GPU的高效MLA解码内核FlashMLA,主要用于减少推理过程中的KV Cache成本。该项目上线45分钟后收获超过400星,并且得到了广泛好评。

DeepSeek开源首个项目FlashMLA,针对英伟达Hopper GPU优化MLA解码内核,提升LLM模型在H800上的性能。

DeepSeek推出FlashMLA开源项目,专为Hopper架构GPU设计的超高效MLA解码内核现已正式开源。它优化了变长序列场景下的效率,并已在生产环境中使用。亮点包括BF16精度支持、Paged KV Cache以及极高的性能表现。

专注AIGC领域的专业社区分享了DeepSeek开源的FlashMLA内核,该内核针对Hopper GPU进行了优化,实现了3000 GB/s内存带宽和580 TFLOPS计算性能,支持BF16并采用分页KV缓存技术。