


邮箱|wangzhaoyang@pingwest.com
姜大昕和阶跃星辰也是有野心的。
只不过这些野望藏在姜大昕习惯性追求“逻辑严谨”的表述里,不易察觉。而阶跃星辰追求各个模态各种模型都不能错过的技术布局,更让这家公司此前在外界看来有点若隐若现。
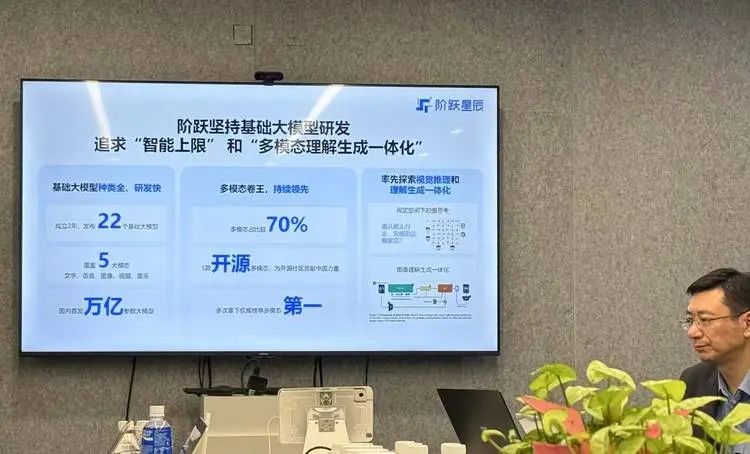
事实上这家刚刚成立两年的大模型公司,已发布了22款自研基座模型,从文字、图像、到视频、语音,以及音乐和推理等,且大多数为多模态模型。
5月8日,阶跃星辰创始人和CEO姜大昕在阶跃星辰北京办公室分享了他最近的思考和阶跃的研发更新。在他的PPT里,他把阶跃的模型分成两类,语言&推理,以及多模态。他称其为阶跃的Step系列模型矩阵。

“国内的大模型公司里面,像我们这样重视模态的全覆盖并且坚持原生多模理念的公司并不多,但阶跃从一开始就始终认为多模态对通用人工智能非常重要。有一句话我也在很多场合不停的重复:我们认为多模态是实现 AGI 的必经之路。”
但这样的全面有时候对围观者来说意味着重点模糊。在一个所有人为AI 焦虑的时期,缺少某一个“爆款”的模型,会让围观的人们无法集中注意力。在姜大昕和阶跃内部的判断,这是他们从技术路线发展和行业现状出发从第一天主动选择的路线。在DeepSeek前后,许多AI公司大幅度掉头,有的从应用转回预训练,然后在“预训练撞墙”论流行后,许多公司又纷纷放弃预训练,而阶跃则基本上一直在把重心放在基础模型侧。
“追求智能的上限,我们认为这仍然是当下最重要的一件事。我们还是坚持基础大模型的研发。”他说。阶跃在最近还调整了此前推出的类ChatGPT的产品,姜大昕认为,这些是过渡期的一些尝试,而“DeepSeek给我们的经验就是,投流的逻辑实际上(对AI的c端产品来说)是不成立的”。
听姜大昕分享,你会感觉即便是今天教授创业成风的AI领域,他也比其他人更像一个教授,追求一环又一环的逻辑推演。这种思考方式的一个典型表现是,他习惯于向AI的历史演变里找答案,非常在意做一件事背后路线的判断,会花很多时间寻找“主流的技术脉络和共性的规律”。
在他看来,“模型的发展是沿着这样一条智能演进的路线往前进化的:模拟世界、探索世界、归纳世界。”
他认为今天正在发生的“大势”有两个,一个已经完成,就是“推理模型从一个趋势变成了一个范式,现在语言模型基本上是推理模型一统天下。”
而另一个还没有统一答案的重要课题,则是多模态理解生成的一体化。其实更具体来说,在这个阶段就是视觉领域的理解生成一体化。
“什么叫做理解生成一体化,它的定义是理解和生成是用一个模型来完成。”他说。文本模型诸如ChatGPT已经完成理解生成一体化,但视觉领域没有。
“即使是对图片,我们理解的时候用的是 GPT-4o 这样的模型,或者是在阶跃是用的 Step-1o。那么生成又换了其他的模型,比如说用 Flux、用 Stable Diffusion,阶跃是用 Step image 这样的模型。它是分开的。”
为什么一定要做理解生成一体化?姜大昕认为,简单说就是“生成需要理解来控制,理解需要生成来监督”。
但与语言模型不同,多模态的复杂度要高出很多。
“所以在视觉领域我们还没有一个很好的、很高效地表达这么一个连续的高维的连续空间的生成问题,所以我们只好理解的时候用了一个 auto-regression Model 是自回归模型,生成的时候还得依赖 diffusion Model。”
为了解决这个视觉领域的“灵魂拷问”,目前有两种主要方法,一是尝试把这些高维的连续分布变成一个离散的像语言token的东西,但这个过程信息就丢失了,“从来没有成功过”。第二种就是把auto-regression 的架构和 diffusion 的架构合在一起,但“也没有做得很成功”。姜大昕认为这个问题目前还在探索的阶段。
“你们的路线是什么?”我在交流现场问姜大昕。
“我可以说内部有多条技术路线,因为确实是不知道(哪个是最终的)。不谦虚地说,我们的技术人才储备是很雄厚的,可以说大家是各执己见,我的意思就是你做出来才算,谁都可以做,所以是有多条路线在并发。”
这很容易让人想到互联网公司常用的赛马机制,而这种机制背后某种程度往往也是人才的积累之争。
这名前微软全球副总裁创业后,ResNet作者之一的张祥雨、AI Infra专家朱亦博也先后加入阶跃。去年12月,阶跃星辰再次完成B轮数亿美元融资。多个开源模型在开源社区获得了不错的反响。
这些是姜大昕的底气。
而在他看来,视觉模型的一体化目前甚至还没有到“Transformer 时刻”,今天依然没有这个最合适的能规模化的架构,他形容目前很多方案是“胶水模型”,把多个模型拼凑起来的思路不会是最终的形态。而阶跃希望自己能成为创造出视频的Transformer 的那一个,要做到这一点,他给阶跃设计的路线,就是成为多模态的卷王。

“我认同多模态卷王这个名字。”他认为理解和生成一体化是个非常综合素质的一个考验。“不是我们不够focus,而是要做这件事就是需要非常综合的才能做的出来。所以这也是我们的一个长项,因为我们所有的线能力都非常强,可以组合起来去探索。”姜大昕说。在交流中他也透露,阶跃内部此前划分的生成和理解两个不同“部门”已经整合为一个“生成理解”团队。
而在和大家聊了两个小时后,姜大昕终于难得地透露出了野心。
“我们强调技术领先性,探索的是下一代领先的一体化模型,我们试图在基础模型上有代际的(领先),是代际的往前走。”
以下为姜大昕对话实录,经简单编辑。

硅星人:你刚才提到了视觉的理解生成一体化的两种路线,而且效果似乎都不太好,阶跃的路线是什么?
姜大昕:我可以说内部有多条技术路线,因为确实是不知道(哪个是最终的)。不谦虚地说,我们的技术人才储备是很雄厚的,可以说大家是各执己见,我的意思就是你做出来才算,谁都可以做,所以是有多条路线在并发。
硅星人:你提到现在还没到GPT-4的时刻,还是等待Transformer 的阶段,那么你们是要做发明Transformer 的,还是等其他人发明后,你是做那个GPT4和ChatGPT的。
姜大昕:那肯定是做出Transformer 。
硅星人:那今天回头看OpenAI,大家会感叹Ilya像天才一样早早认定了一个路线,但听你的分享,目前视觉还不是这样,还是多条路线。
姜大昕:我觉得OpenAI当时在 Transformer 出来之前肯定是有多条路线的。核心就是怎么把language model 做成scalable的架构。当时包括LSTM,GRU,各种各样的架构,直到最后 Transformer 出来是大家认了,现在就相当于有人在探索LSTM,有人探索GRU,最后要出来一个大家都认的路线。
硅星人:继续问的话,当初Transformer出来后,“认”它就是最终路线的人,决策的快慢也是不同的,最后也影响今天的格局,这还会再来一次么?
姜大昕:非常有意思,就是 17 年出来之后 ,Transformer 一统天下的不是GPT,是Bert。如果大家都在关注也知道,那时候的标题都是什么霸榜横扫,当时做自然语言处理的话,就是 Bert 是吊打GPT的,而且GPT比Bert早出来几个月。但Ilya有执念,他坚决认为没有生成谈不上理解,理解能力都是fake 的,只是一种模式的translation。但是从实际效果来说,我当时在做搜索,Bert确实好很多,甚至GPT3出来我们很佩服,但效果还是不好。直到ChatGPT出来,大家知道原来可以这样做。
但这些语言模型发生过一遍的事情,整个逻辑的推进不用在视觉再来一遍。大家轻车熟路,就等着那个Transformer 什么时候出来,只要这一关突破了,后面就顺利很多,不需要像语言模型那样再从Bert到GPT到ChatGPT探索一次。
提问:人们此前在视觉领域最关注Sora,现在看起来它不是Transformer 级别的,那我们要怎么判断OpenAI或者谁做到了。
姜大昕:有一天我看到它能predict the next frame,如果哪天OpenAI说推出了不叫Sora的一个视频生成模型(就有希望)。
其实去年大家对Sora感到兴奋的时候,我们非常失望。我们认为主线是理解生成一体化,但Sora没有在这个路线走,走弯了。不过后来我们去想也有道理,一步走到太难了,所以要两个独立往前走,互相铺垫,左脚踩右脚,比如Sora提到用GPT4o给数据打标,可能迭代几轮会有不同。但总的路线是一体化,这个不解决,后面都不行。
硅星人:这比较抽象,有什么样具体的任务可以用来判断这个视觉的Transformer已经出现?
姜大昕:我觉得首先就是它能够无限地去生成,比如给它一个电影的开头,它能够一直往下编编编编编,而且大家觉得还挺有道理的。如果他能一直这样做下去,而且consistent,要符合逻辑,符合物理规律。比如10分钟的影片,它能一直往下走,而且合情合理,那我觉得就做到了。
问:阶跃被称为多模态卷王,不停发布模型,这背后是因为到了能发布的阶段,还是因为有KPI?
姜大昕:首先我认同多模态卷王这个名字。
那么为什么在外界看来我们是一个月就会发布一个模型?其实你如果仔细看那些模型,它是在不同线上,因为我们的布局特别完整,有声音、有图像,音乐模型,还包括语言,推理。其实每条战线都是经过了几个月甚至半年这样一个积累,但如果你同时看众多战线的话,你就觉得一两个月就有一个。
问:那如果说我们希望最终做出理解生成一体化的话,为什么我们不把所有的力量都集中去做它?
姜大昕:非常好的问题。我们也想这样做,但是不行。它是一个非常综合素质的一个考验。首先你要有一个非常Solid的语言模型,它现在已经进化到推理模型。然后要有视觉推理,是视觉理解的升级。然后还有生成端。
所以不是我们不够focus,而是要做这件事就是需要非常综合的才能做的出来。所以这也是我们的一个长项,因为我们所有的线能力都非常强,可以组合起来去探索。
提问:行业各种转变,你们为什么一直坚持预训练自研模型?
姜大昕:我觉得现在行业趋势还是一个技术路线非常陡峭的趋势。曾经震撼大家的GPT4,已经要下架了,Sora大家今天觉得有什么神奇,o3现在做的事情,可能明年又觉得没什么。技术发展还是非常非常快,我们不愿意在这个过程缺席,放弃这个技术增长的机会。我们会坚持基础模型的研发。
今天的格局里,我们是综合型的,不是专注在AIGC这种的,我们不太一样,不是专门做一个模态或者生成。我们强调技术领先性,探索的是下一代领先的一体化模型,我们试图在基础模型上有代际的(领先),是代际的往前走。


(文:硅星人Pro)