
Llama 是曾经,Qwen 是现在和未来。
全球科技圈最近热闹非凡。
热闹到连造“铲子”的芯片霸主英伟达都开始发布 AI 模型了。
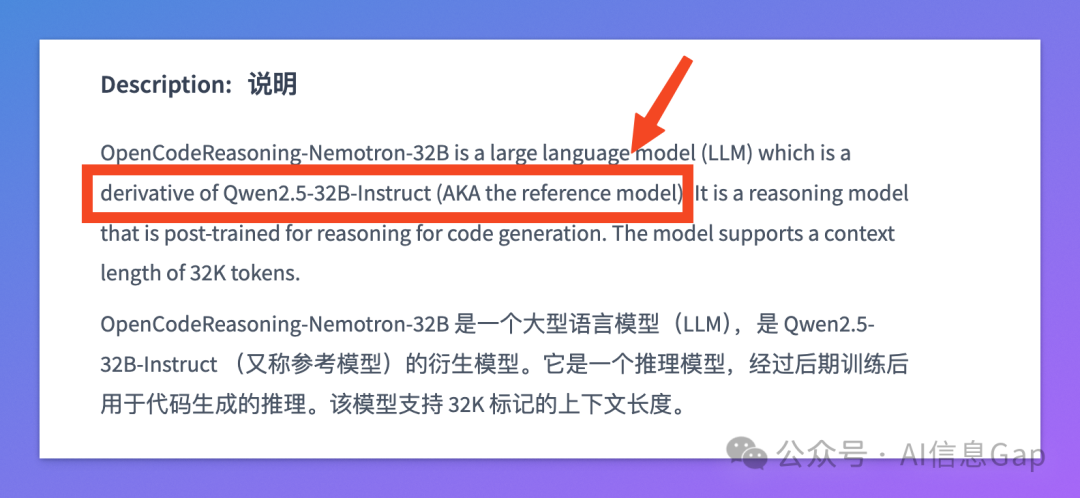
你可能已经听说:5 月初,英伟达正式推出并开源了名为 OpenCodeReasoning 的系列模型,其中最强的 32B 参数版本在 LiveCodeBench 测试中一鸣惊人,pass@1 得分高达 61.8%,超越了 OpenAI 的 o3-mini和 o1-low 等商业化私有模型。
然而,你可能还不知道:英伟达这款模型背后的“基底”,竟然是来自 阿里的通义千问模型!
英伟达官方模型卡片明确标注 —— 基于 Qwen2.5-32B-Instruct 微调而来。
这并不是“一个大厂选了另一个大厂的技术”这么简单。
更准确地说,英伟达只是 Qwen 朋友圈最新的加入者。
再往前,李飞飞团队同样以 Qwen 为基座模型,只用 16 块 H100 GPU,26 分钟就训练出了性能媲美顶级模型的 s1-32B;DeepSeek 也公开承认,它的 R1 蒸馏的 6 个模型中,有 4 个直接来自 Qwen。
那么,从 Llama 到 Qwen:为什么全球顶级玩家的选择在悄然变化?
01|Qwen 模型的成长:从 0 到开源之王
我应该是最早给粉丝小可爱们推荐通义千问的那一批了。
早在一年多前,我就在“AI,一个就够了”系列文章里对国内的几个 AI 产品进行了横向测评,其中就包括通义千问。
彼时通义的当家模型还是 通义千问2.0,一个千亿参数的闭源模型。
直到后来真正意义上追平了 GPT-4 级别性能的 通义千问2.5,以及 1100 亿参数的开源模型 Qwen1.5-110B,这应该算是国产模型第一次进入了全球玩家的视野。
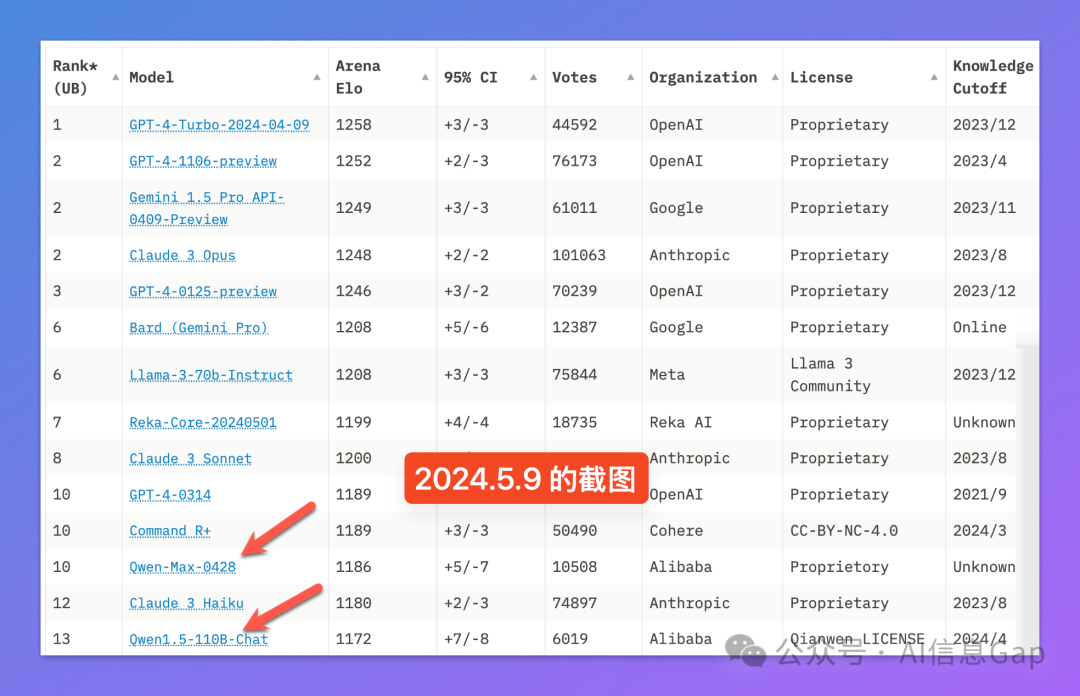
附一张一年前的 LMSYS 大模型排行榜“远古”截图。
第一次有国产模型跻身进入前十名。
再后来的故事大家就更为“耳熟能详”了。
从大年初一的比 DeepSeek-V3 还猛的 Qwen2.5-Max,到今年五一假期发布并开源的 Qwen3:至此,Qwen 坐上了开源模型实至名归的头把交椅。
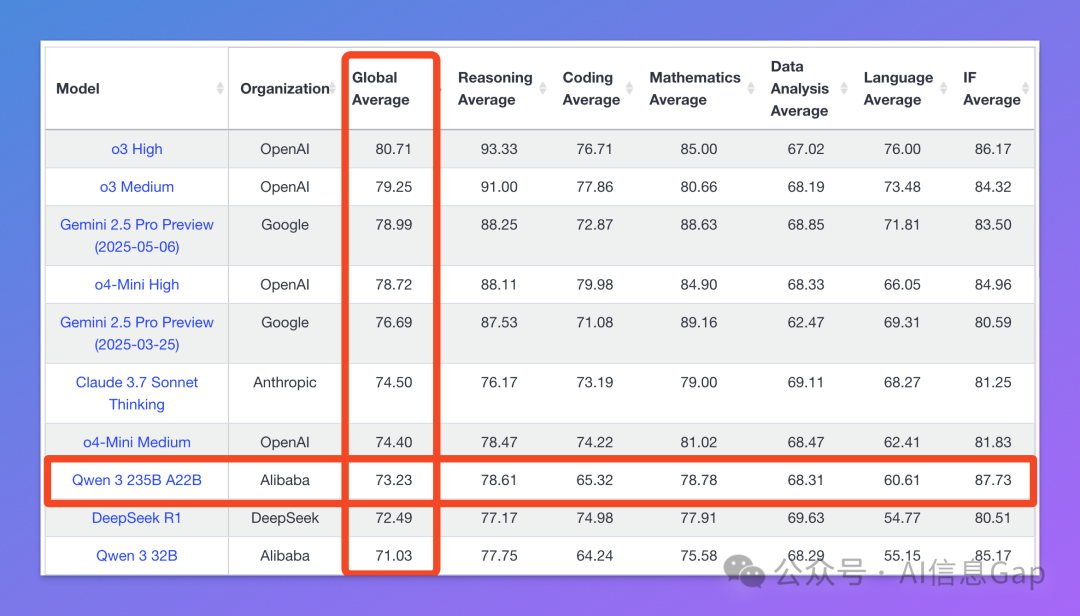
作为一个开源模型,Qwen3 在 LiveBench 榜单上的排名仅次于北美“御三家”最顶级模型。
所以我说:这样的通义千问,尊称一句 “国产之光” 不过分吧。
但问题来了,Qwen3 凭什么能够在众强林立的 LiveBench 排行榜脱颖而出?
02|混合推理:快慢思考,一个模型搞定
从技术角度看,Qwen3 最令人瞩目的亮点之一是其混合推理能力。
2024 年下半年起,大模型的发展方向开始分为两个流派:不会思考的“通用模型”和内置了思维链的“推理模型”。
前者响应快速但逻辑推理差,后者逻辑严密但速度慢。
然而,模型太多就会导致用户的“选择困难”。
合二为一,势在必行。
Qwen3 就是这样一个整合了“非思考模型”和“推理模型”两家之长的模型:混合推理。
需要注意的是,混合推理模式指的是在同一个模型内实现“快思考”和“慢思考”双模态,目前全球范围内仅有 Claude 3.7 Sonnet、Gemini 2.5 Flash 和 Qwen3 能够做到。
简单来说,这种设计架构就是在一个模型里安装两个大脑。
遇到简单问题,模型能够不假思索地回答(快思考);但面对复杂难题时,模型会慢慢分析、逐步推理(慢思考)。
“快思考”模式,适用于一般对话、日常任务,能够快速响应;而“慢思考”模式,则更适合逻辑推理、数学计算、编写代码等需要分解、推理、验证的复杂任务。
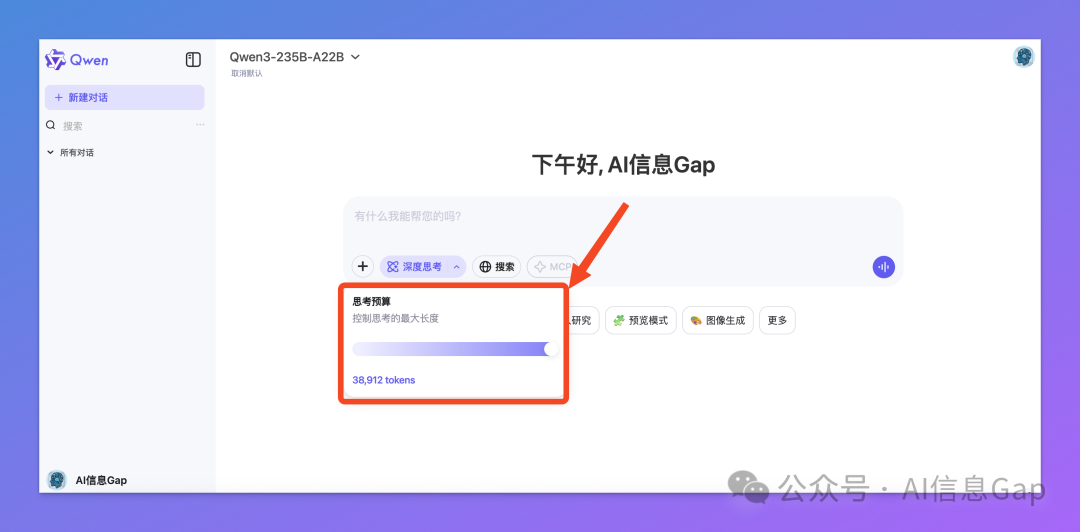
另外值得一提的是,Qwen3 还支持自行设定“思考预算”,从 1024 到 38912 tokens,模型思考多深你说了算。可玩性拉满。
03|顶级玩家都在选,Qwen3 凭什么?
英伟达 CEO 黄仁勋在一次采访中表示:“中国在 AI 领域并不落后于美国,两国间的差距很小。”
这话放到一年前,可能会被当做一句客套话;而现在,则已是一个冷冰冰的事实。
无论是性能、开源生态,还是全球适配性,Qwen3 都已跻身进入 AI 模型第一梯队。
性能自不必多说。
Qwen3 系列的混合专家模型 Qwen3-235B-A22B,拥有高达 2350 亿总参数,但实际激活的只有 220 亿,这意味着能够凭借最少算力,完成最复杂任务。在最新的基准测试中,Qwen3-235B-A22B 凭借 95.6% 准确率的 ArenaHard、85.7% 的 AIME24、70.7% 的 LiveCodeBench 和 2056 分的 CodeForces Elo 评分,以“出道即巅峰”的姿态横扫所有开源模型。
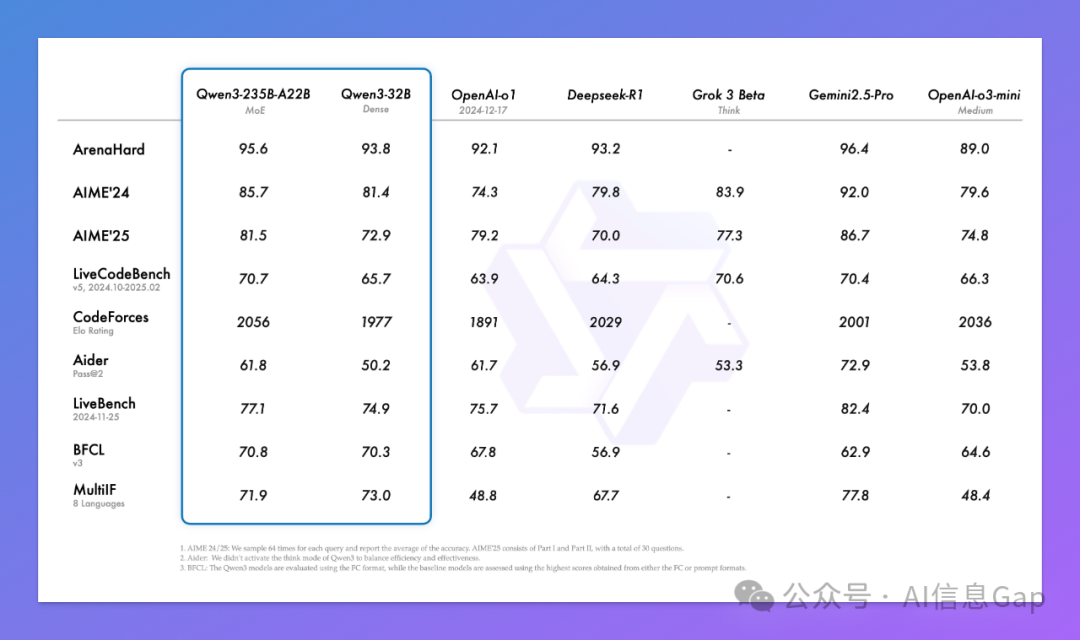
此外,除了上面的 LiveBench 榜单,在 Artificial Analysis 排行榜,Qwen3 也依然是开源第一,综合排名第五名。

04|Qwen3 的生态:不仅是模型,更是生态
“
Qwen3给闭源路线敲响警钟,巨额资源换来的闭源模型只比开源略好,模式不可持续。” —— 李开复
Qwen3 的成功离不开阿里千问对“开源”的极致友好态度。
自 2023 年开源以来,阿里的 Qwen 系列已经成长为全球下载量超 3 亿的超级生态,衍生模型数量突破 10 万,超过了 Meta 的 Llama,成为全球最受欢迎且最具影响力的开源大模型。
但这不仅仅是一个“开源模型”这么简单。
Qwen 已经成为一个“开源生态”:从文本、代码、图片生成,到多模态推理,Qwen 系列模型都能胜任。并且,相比 Meta 的 Llama 采用特殊的非商用许可证,Qwen 系列模型一直坚持使用完全商业友好的 Apache 2.0 协议。这意味着企业可以零成本集成和二次开发,无需担心版权限制。
正因如此,Qwen3 不仅仅是阿里的技术“产品”,更是一种“全球共享的基础设施”。
而这些也正是英伟达、李飞飞团队、DeepSeek、苹果、Manus 等整个产业链都在拥抱 Qwen 的真正原因:他们看中的,不只是一个“模型”,而是一整套“开源 AI 生态”。
结语
过去,Llama 是全球开源大模型的代表。
而现在,Qwen 正在成为越来越多顶级玩家的标准答案。
未来,全球开源 AI 生态中,每一次创新的背后,或许都有中国力量的身影,都有 Qwen 的智慧。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)