

论文标题:On Path to Multimodal Generalist: General-Level and General-Bench
录用位置:ICML’25 (Spotlight)
论文地址:https://arxiv.org/abs/2505.04620
项目主页:https://generalist.top/
Leaderboard:https://generalist.top/leaderboard
Benchmark:https://huggingface.co/General-Level
Huggingface Paper: https://huggingface.co/papers/2505.04620
引言:AI下半场,评测为何成关键?
近年来,多模态大模型(MLLM)正加速迈向“通才时代”,从图像理解到跨模态生成,能力不断细化、模态持续扩展。未来AGI公认的发展路径,就是构建能够像GPT掌握语言一样,实现多模态信息自由理解与推理的通才模型。这样的系统将成为支撑下一代超级智能系统的关键基座。而另一方面,正如最近OpenAI研究员姚顺雨所引发的共识,人工智能发展进入“下半场”,模型的评估正变得比模型构建本身更加重要。随着MLLM的爆发,我们迫切需要科学完善的评测体系来衡量模型的真实能力。然而,现有的多模态评测基准存在诸多局限:许多基准只针对单一任务或单一模态,无法全面覆盖模型多方面能力;尤其在生成能力方面,目前缺乏全面、严谨且一致的评测方法。例如,不少视觉问答或图文理解基准只考察模型对图像理解的问答表现,却很少涉及跨模态生成的能力测试。这使得我们难以判断,一个在若干任务上指标更高的模型,是否真的更接近通用人工智能。换言之,在通才AI评测方面,我们面临着任务多样性和评测维度双重不足的挑战。
正是在这样的背景下,最近一项旨在解决通才多模态评测痛点的重磅工作诞生了。被录用于ICML 2025,一篇题为《On Path to Multimodal Generalist: General-Level and General-Bench》的论文脱颖而出。该工作由来自多家学术与产业机构的庞大团队合作完成,作者阵容涵盖新加坡国立大学、南洋理工大学、浙江大学、阿卜杜拉国王科技大学、北京大学、上海交大、罗切斯特大学等30余位研究者。论文提出了“双管齐下”的评测方案:一是General-Level评估框架,用“段位制”划分多模态通才模型的能力等级;二是General-Bench,一个超大规模的多模态评测基准数据集。General-Bench以其空前的规模和广度,成为当前业界最大、覆盖最全面的多模态大模型评测基准,可谓是“多模态通才AI的高考”。
通才评测新思路:General-Bench的设计初衷
当前的多模态大模型正从专才走向“通才”范式:早期模型只会理解多模态信息,而如今新一代MLLM已经能够生成跨模态内容,支持的模态从有限扩展到几乎任意。评测这样的“全能型”模型,需要与传统单任务基准截然不同的方法论。General-Bench的设计初衷,正是为了全面刻画通才AI的综合能力。其提出者质疑了以往“多任务平均成绩越高就代表模型越强”的简单假设,强调应该关注模型在不同任务、不同模态之间是否表现出协同增益(Synergy)效应。通才模型理想状态下,各模态技能应当互相补益,达到“1+1>2”的效果,这也是评测的难点所在。为此,作者在General-Bench中纳入了理解与生成双范式下的海量多模态任务,希望通过更丰富的任务集合,揭示模型在跨模态理解–生成间的协同表现。
另一方面,General-Bench的构建还基于开放科学和社区合作的动机。作者团队意识到,通用AI评测不可能由一个闭门造车的固定基准一劳永逸解决,需要持续演进、开放参与的评测生态。因此,他们在设计General-Bench时引入了开放集/封闭集机制(下文详述),并搭建了线上排行榜平台,方便研究者提交模型评测结果,同台竞技。这种设计既保证了评测的公平客观,又激发社区共同完善基准的数据和任务覆盖。这些理念上的创新,使General-Bench不仅是一个数据集,更成为一个开放的评测基础设施,为多模态通才AI的长远发展铺平道路。
General-Bench有多“大”:“通才高考”全面解析
作为目前规模最大的多模态评测基准,General-Bench的“考卷”究竟涵盖哪些内容?简单来说,就是“宽度”和“深度”兼备。首先在宽度上,General-Bench囊括了五大模态:图像、视频、音频、3D和语言,真正做到了模态上的广覆盖。此外,它还延展到时间序列、代码、文档、图表、雷达信号等特殊模态形式,可谓包罗万象。在深度上,General-Bench不仅包含传统的理解类任务(如分类、检测、问答等),还大量引入生成类任务(如描述生成、图像生成、音频生成、视频生成等)。所有任务都采用了开放式的答案格式,即Free-form自由作答,而非简单的多选或判断——评测采用各任务原有的指标对模型输出进行评价。这一点尤为难能可贵,因为生成类任务评估往往复杂,但General-Bench依然将其纳入,以全面衡量模型的生成能力。
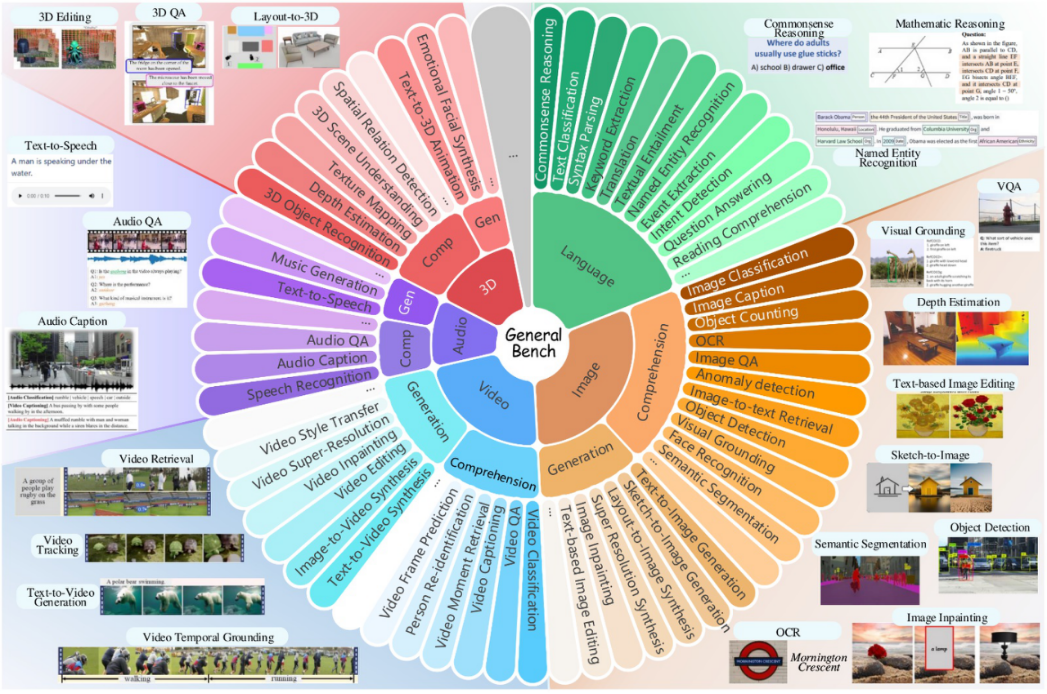
General-Bench多模态任务的分类概览示意。【橙色/棕色:图像模态】、【蓝色:视频】、【紫色:音频】、【红色:3D】、【绿色:语言】;每种颜色扇形的内环代表理解任务,外环代表生成任务。示例插图展示了部分典型任务,如图像分类、VQA、文本生成图像、音频问答、3D场景重建等。该基准覆盖从感知到生成的各类任务,为评测提供了前所未有的广度和难度。
从数据规模看,General-Bench可谓“题量惊人”:它汇集了超过700项任务,包含了325,000+个样本之巨。这些任务进一步细分成145项具体技能,涵盖了视觉、听觉、语言等不同模态下的细粒度能力点。例如,在图像模态下包括物体识别、场景理解、OCR、视觉推理、图像字幕生成、图像编辑等技能;在音频模态下有语音识别、说话人辨识、音频问答、音乐生成等技能;在视频模态下涉及视频理解、事件检索、视频问答、文本生成视频等;3D模态下有三维模型分类、点云理解、文本生成3D模型等;语言模态下则涵盖阅读理解、常识问答、数学推理、代码生成等丰富任务。不仅任务丰富,General-Bench还跨越29个知识领域,从理工科的物理、几何、生物、医学,到人文社科的历史、文化、艺术、经济等均有覆盖。同时基准关注评测模型的多个通用能力维度,如内容识别、常识理解、推理与因果判断、情感分析、创造与创新等。可以说,General-Bench构建了一个多维度立体评测空间:模态上横跨视觉、听觉、语言与跨模态,任务范式上贯穿理解与生成,内容上覆盖不同领域知识和能力。这张“通才高考试卷”的难度和综合性前所未有,足以全面考察多模态大模型的全局能力谱。

值得一提的是,目前General-Bench收录的任务中理解类任务仍占主导,占比约三分之二,生成类任务约占三分之一。这反映出当前社区沉淀的公开数据在生成方向相对匮乏。但随着项目的持续迭代,未来将有更多生成任务和新模态数据加入,以逐步平衡两类任务比例。General-Bench的规模仍在不断扩充中(当前样本数已达325,876,并将持续增长),这也展示了其开放演进的生命力。
开放集vs封闭集:公平与合作的机制设计
构建如此庞大的评测基准后,如何既保证评测公平又推动开放合作?General-Bench巧妙地通过“开放集(Open-Set)”和“封闭集(Close-Set)”机制实现了这一点。具体而言,General-Bench将所有任务数据划分为两套副本:开放集公开了完整的任务输入和标准答案,任何人都可以自由下载用于研究、训练或非正式测试;而封闭集只公开任务的输入部分,标准答案对外保密。封闭集专供官方评测和排行榜使用,研究者需要将模型对封闭集输入的输出提交给主办方,由官方脚本离线比对评估,以获得权威成绩。

这种设计有几点好处:首先,封闭集确保了评测结果的公正可信——模型无法通过提前看到标准答案“作弊”,所有上榜成绩都在相同未知测试集上取得,具有可比性;其次,开放集降低了社区参与门槛,研究者可以先在开放集上自行评估或调优模型,充分利用宝贵数据资源。开放集也方便后续扩展基准:社区可以针对开放集提出改进、更难的任务或新评价指标,不断完善评测手段。可以说,开放/封闭集机制让General-Bench既充当了共享研究平台,又保留了竞赛标准所需的严格性,在开放与公平间取得了平衡。这一机制设计初衷在于鼓励社区共建:每个人既是“考生”,也是“出题人”,共同打造通才AI的评测生态。
提交模型参与打榜!
General-Bench不仅提供了一份综合考卷,更搭建起公开透明的评测平台。任何研究团队只要拥有多模态大模型,都可以按照官方流程提交模型参与评测,在排行榜上与全球最新模型一较高下。具体提交流程非常清晰:
1.选择评测范围:General-Bench提供了不同Leaderboard榜单分组,从全任务的综合榜(Scope A)到特定技能子集榜(Scope D)。开发者可以根据自己模型的能力选择参与哪一个或多个榜单。
2.下载封闭测试集:根据所选榜单,从HuggingFace下载对应的封闭集数据。封闭集只包含输入(如图片、问题等),没有答案。
3.本地运行模型:用模型对封闭集所有输入进行推理,得到模型的预测输出结果。
4.提交预测结果:通过官网提供的入口上传模型对封闭集的输出。主办方收到结果后会进行评测,并更新模型在Leaderboard上的成绩和排名。
以上流程简单明了。值得注意的是,封闭集的数据量不小,全量Scope A涵盖所有模态任务,评测开销较高。为此General-Bench也提供了Scope细分榜单,让一些暂不支持所有模态的模型也能参与部分评测,降低了进入壁垒。
除了提交模型成绩,General-Bench项目组非常欢迎社区贡献新的任务数据。如果研究者手头有有趣的多模态数据集,希望纳入General-Bench评测,只需按照官网提供的指南进行投稿。作者在项目网站明确表示:“我们的General-Bench是开放的,欢迎随时贡献数据集”。提交的数据将在审核后并入开放集,从而不断丰富基准的任务池。这种开放共建模式,有望使General-Bench保持长期的生命力——随着新任务、新模态的不断加入,评测基准将与时俱进,不断扩大覆盖面,始终代表多模态AI能力挑战的前沿。官方也计划定期更新榜单和报告,追踪模型进步和能力短板,形成持续演进的评测循环。

General-Level段位制:通才评测的双剑合璧
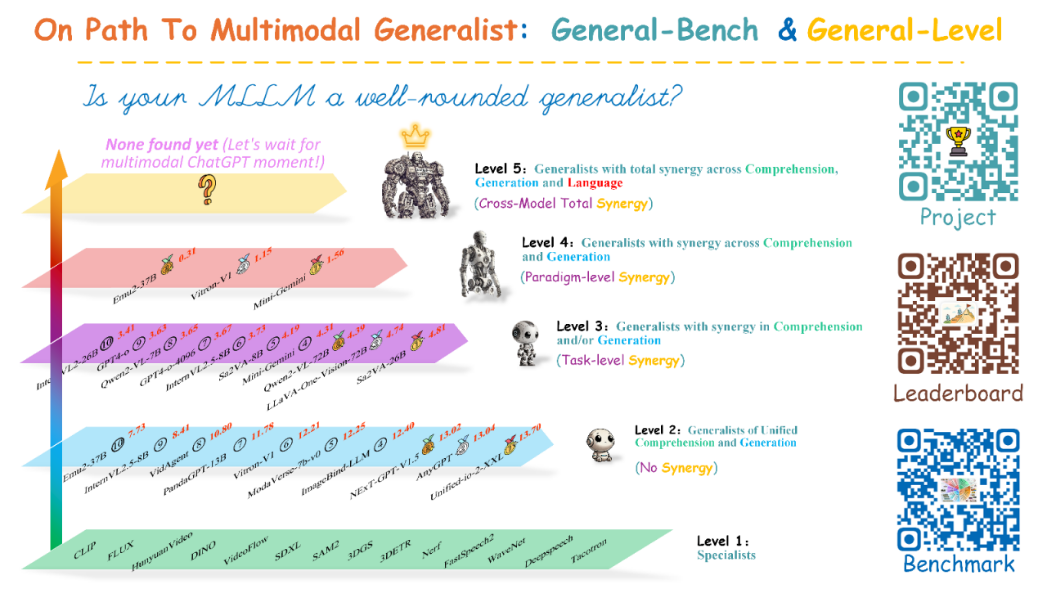
在介绍完General-Bench这个“考卷”本身,我们也需简要了解与之配套的General-Level段位评估体系。General-Level是论文提出的另一核心贡献,用以给多模态通才模型“打段位”。它将模型能力从低到高划分为五个级别(Level 1–5),评判标准正是前文提到的协同效应强弱。


简单来说:
·Level 1:专才高手。模型只在各单项任务分别达到当前专业模型的SOTA水平,但没有跨任务的一致性。
·Level 2:全能新人。模型开始支持多种模态和任务,但尚无协同效应,只是简单汇集了多项能力。
·Level 3:任务协同。模型在同范式内部(如多个理解任务之间)出现协同提升效果,有部分任务成绩超过各自单项SOTA。
·Level 4:范式协同。模型在理解与生成之间出现协同效应,两种任务范式互相提升,综合表现更均衡出色。
·Level 5:完全通才。模型在跨模态、跨范式、语言三个层面都实现了协同,即真正做到视觉、听觉与语言智能的融会贯通。这被誉为“多模态版的ChatGPT时刻”。
General-Level多模态通才段位示意图。该体系以协同效应为核心标准,将模型划分为五个能力等级:从Level 1(各领域单项专家)到Level 5(全模态全范式的完美通才)。右侧为作者提供的项目二维码及排行榜入口示意。值得注意的是,截至目前仍没有模型达到最高的Level 5级别(如图顶部所示“None found yet”),这表明我们距离真正的“多模态 ChatGPT 时刻”尚有差距;大多数现有开源模型分布在Level 2–3级,只有极少数顶尖模型展现出了Level 4的范式协同能力。

可以看到,General-Level提供的是一种全局性的能力衡量,它并不纠结于某一具体分数,而是关注模型是否具备跨任务协同的“质变”。General-Bench正是General-Level评估的基础——没有前者提供的丰富任务和数据,就无法客观刻画模型在不同模态、不同范式下的表现,更谈不上比较协同效应的强弱。二者相辅相成:General-Bench提供广度和标准,General-Level给出高度和方法。需要强调的是,General-Level虽然很有洞见,但毕竟是相对新的评估范式,目前主要用于学术分析和启发模型改进;而作为数据基座的General-Bench,则更直接地推动了模型实力的排行榜竞逐,在业内影响深远。
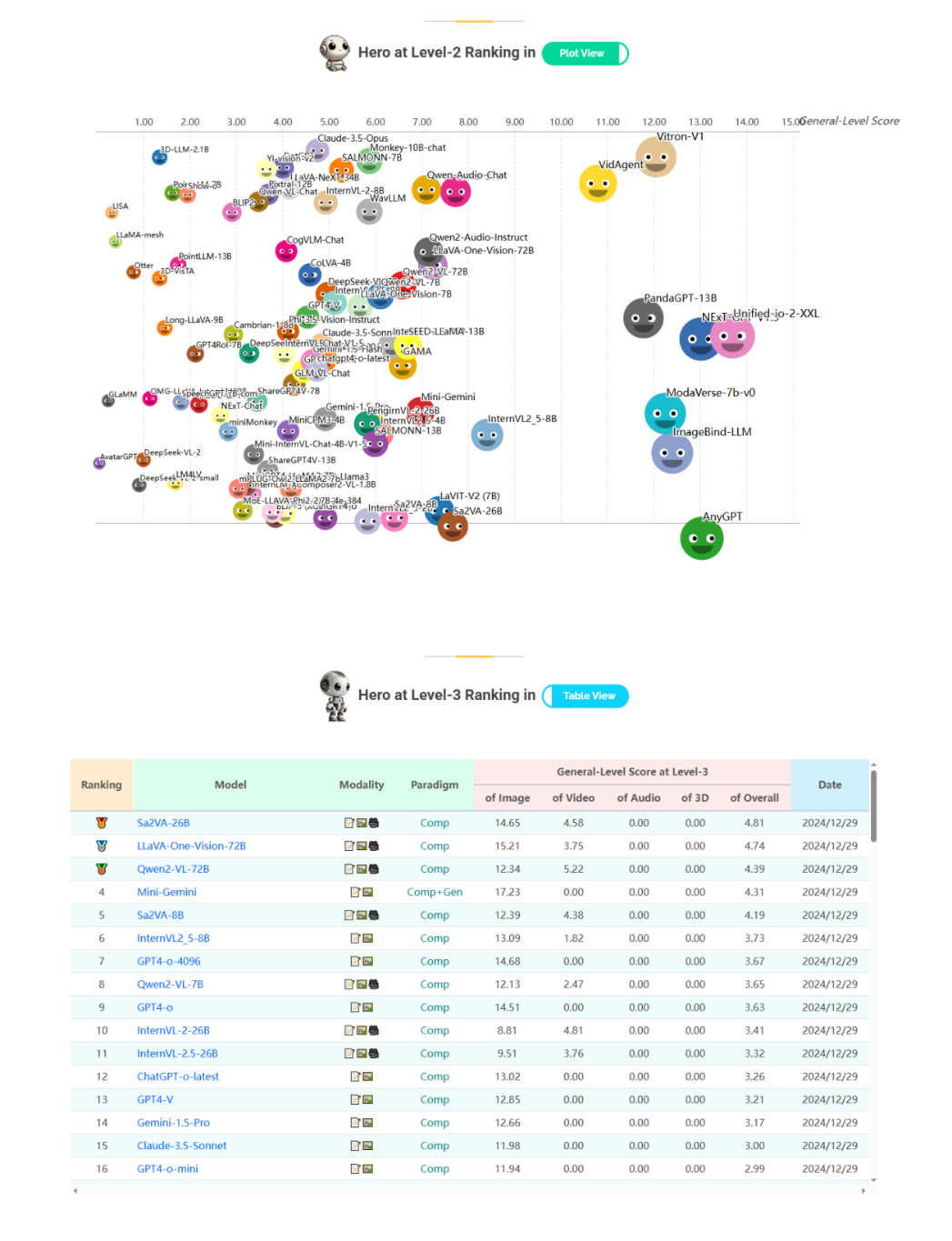
未来方向:多模态通才AI之路
General-Bench和General-Level所考察的是AI系统在跨模态、跨任务上的综合素养和协同能力。这一基准的推出,标志着AI社区愈发重视评价体系的构建,正如OpenAI研究者所言,“在AI的下半场,评价的重要性将超过训练本身”。General-Bench以开放的姿态联合全球研究者,共同完善这份“考卷”,为通才AI打造出一个可信、公正、持续进化的试炼场。展望未来,作者认为在多模态通才大模型进阶之路,还可以从以下几个方向进一步拓展探索:
1. 优化 General-Level 框架,更科学地定义“协同效应”
当前 General-Level 已经提供了一个务实的起点,但算法设计上还有提升空间。比如当前每个段位的协同效应测量比较简化,仅通过超越专家模型来间接反映,缺乏更直接的协同能力量化。未来,我们将探索更加稳健、科学的协同定义方式,让评测标准更接近真实AI通才该有的样子。
2. 扩展 General-Bench,覆盖更多任务、更多模态
目前 General-Bench 仍存在一些不平衡,比如图像任务多、音频和3D较少,理解类任务多、生成类偏少。未来,我们计划大幅扩展任务类型和数据,尤其加强生成、音频、3D等领域,同时纳入更丰富的信息模态,例如代码、表格等新兴数据类型。毕竟,未来的通才AI不该只会看图说话,更要懂得编程、操作复杂信息。而且,我们也希望加入更多跨模态、交互式、多轮对话等任务,模拟更加贴近现实的人机协作场景。
3. 重新思考评测范式,让模型评估更全面、更可靠
当前很多评测方法仍沿用传统套路,虽然适合简单任务,但面对开放式、生成类等复杂任务就显得力不从心。比如视频生成、3D生成等,现有的自动指标往往不足以衡量质量,越来越依赖人工评估。最近也有相当多的研究尝试用大模型充当评审(LLM-as-a-Judge),但评测稳定性和复现性仍然存在挑战。未来,我们希望结合多指标融合评估,提升多模态生成类任务的自动化评估能力,同时让评测结果更稳定、可靠。此外,通才AI的推理过程日趋复杂,未来的评测也应考虑评估模型的可解释性与推理链条,而不仅仅是输出结果分数。
4. 优化模型架构,真正走向“功能多、性能强”
目前多数 MLLMs 仍只能支持 1-2 种模态或能力,距离真正的通才模型还有差距。未来的研究需要让模型在支持更多模态、任务的同时,保持强劲的单项表现。简单堆叠多个专家模型并不能解决根本问题。我们认为更有潜力的方向是引入 MoE(专家混合)等先进架构,结合自动回归+扩散等最新技术,探索统一强大的多模态通才框架。
5. 聚焦“协同效应”,让通才AI真的做到“1+1>2”
正如本文强调,通才AI的核心在于跨任务、跨模态的协同效应。未来,我们将在两方面重点攻关:
·从架构设计出发,打造可以灵活迁移跨模态知识、任务特征的机制,让模型学会“类比推理”;
·从训练方法出发,探索防遗忘训练策略,以及引入 RLHF、GRPO 等强化学习技术,让模型持续进化,学会更多复杂推理和更强的协同泛化能力。
(文:机器学习算法与自然语言处理)