

我是
小冬瓜AIGC
X-R1开源框架 | 现高校LLM对齐研究课程帮助学员拿下
OpenAI,Meta等
小红书/知乎:小冬瓜AIGC
DeepSeek-V3 的 AI-Infra 将性能压榨到极致。
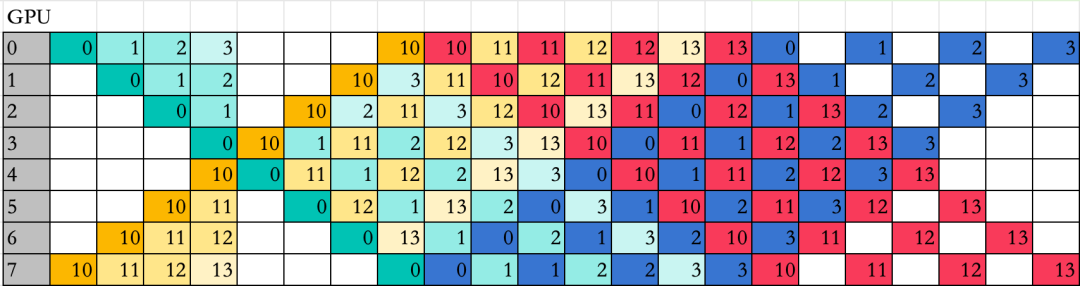
V3 用 DualPipe + EP(计算-通信-重叠) 构建了分布式训练框架。
LLM 分布式训练技术由于多机多卡的机器要求,难以入门和精通
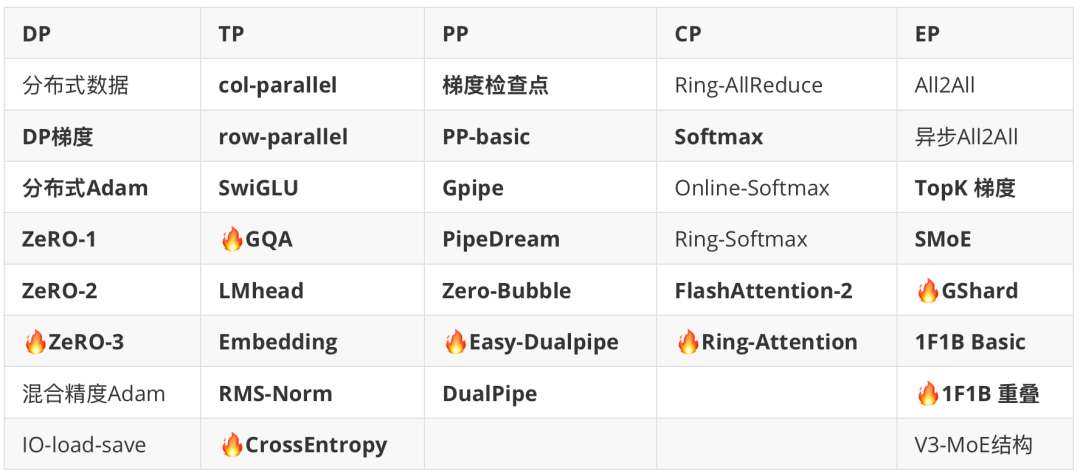
本 Lecture 基于 Pytorch 从 0 手撕 DP, TP, PP, CP, EP,而且把 Backward 也写了,全实例可运行。具体包含:
-
纯 Pytorch从零手撕5大并行算法:DP、TP、PP、CP、EP。不依赖DeepSpeed和Megatron框架, -
手撕关键算法 Backward梯度和ZeRO-adam,硬核实现 MoE EP 1F1B 下的 通信-计算重叠 -
Step-by-step 手撕 DP:ZeRO-3、TP:Llama、CP: RingAttention、PP: DualPipe、EP: Gshard等经典算法 -
不需要多卡环境,纯CPU GLOO backend可运行所有实例,无须 triton和cuda 等基础
展示分布式代码截选
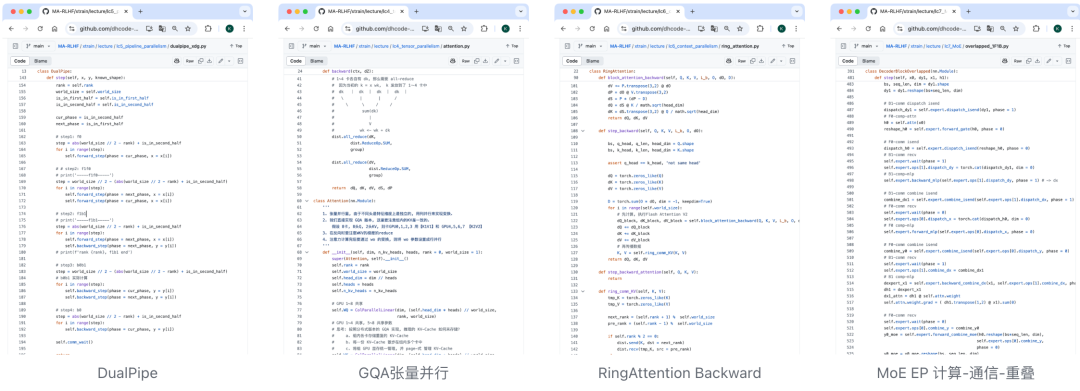
Lecture摘选了 EasyDualPipe 开源 https://github.com/dhcode-cpp/easy-dualpipe
更多详情了解《手撕LLM》课程
一、「手撕LLM」课程介绍
-
课程内容:直播 + 往期录播 + 手撕级Notebook + 非调包Code + 算法图解 + 课程PPT -
课程项目:垂域大模型实操 + 多卡DeepSpeed RLHF训练 + R1模型训练实操⚠️ -
进阶专题:手撕RL、手撕RLHF、手撕分布式训练、手撕多模态VLM、LLM加速、手撕RLHF-PPO Notebook -
实操效果:X-R1实操<50元成本出效果;已全线支持Llama-3-8B/70B的SFT/DPO/PPO多卡训练;低成本百元 8B DPO训练; -
LLM社群:学员超过50%来自海外。部分就业于北美OpenAI、谷歌Gemini、SEED、META、微软、亚麻、苹果、谷歌等,海外学历背景PhD居多,MIT、UCLA、UIUC、NYU、UCL等;国内清北、复旦居多。 -
入门要求: Pytorch+神经网络或深度学习基础

二、课程目录
2.1 整体目录

2.2【手撕LLM-第9/10章节】RL/RLHF

2.3【手撕LLM-第11章】LLM加速(长文档)

2.4【手撕LLM-第12章】分布式训练(长文档+代码)

2.5【手撕LLM-第13章】手撕多模态VLM(长文档+Notebook)

2.6【手撕LLM-第14章】手撕o1推理(长文档+Notebook+PRM实操)

2.7 其他新增内容
-
分布式训练:DP、ZeRO1/2/3、GQATP、DualPipe、GShard、计算通信重叠等 -
Notebook:FlashAttention Backward、Cut Cross Entropy,MCTS, BPE, BeamSearch, AutoGrad, CrossEntropy, PPL, Layernorm Backward, Tensor Parallel, BTModel, DPO, IPO, KTO, NTK-RoPE, Llama-3-GQA, MoE -
测评:vllm推理部署、CMMLU、MMLU、CEVAL、safety测评
三、课程内容
在线直播授课+Notebook+源码工程+关键算法图解+课程PPT+课后答疑+完整垂域大模型实操项目+多卡Deepspeed+RLHF PPO实操+R1训练实操
实操项目仓库MA-RLHF: 课程私密代码仓库,实操项目和手撕Notebook长期更新。
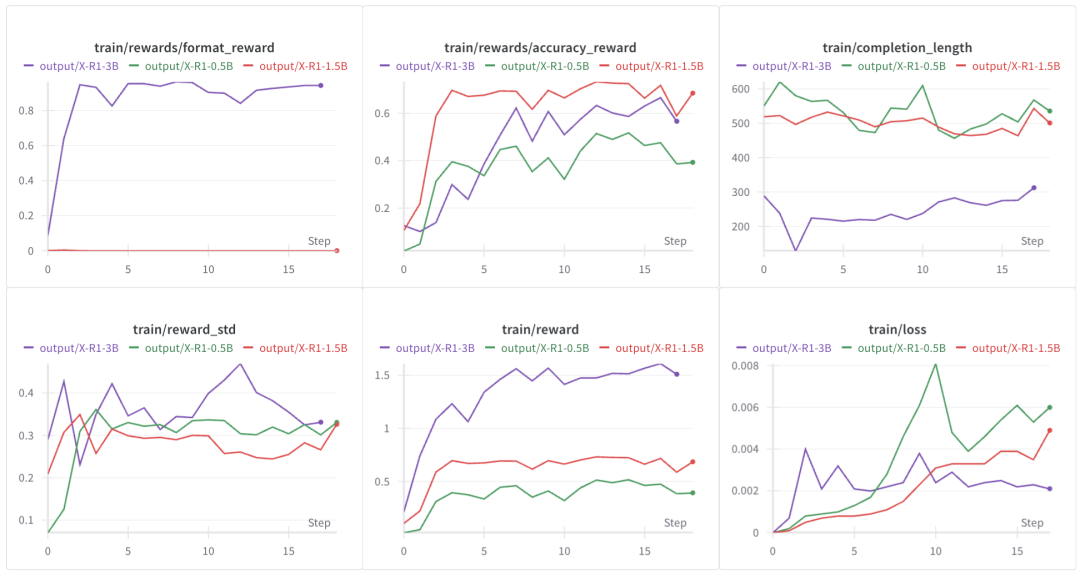
3.1 实操项目1: R1 模型训练实操【项目开源】
包含 R1 原理讲解,手撕GRPO,X-R1框架训练:< 50元复现0.5B 数学推理。
实操模型开源至huggingface🤗 : xiaodongguaAIGC/X-R1-3B
基于Qwen-2.5-0.5B/1.5B/3B 训练曲线:
中文数学推理示例

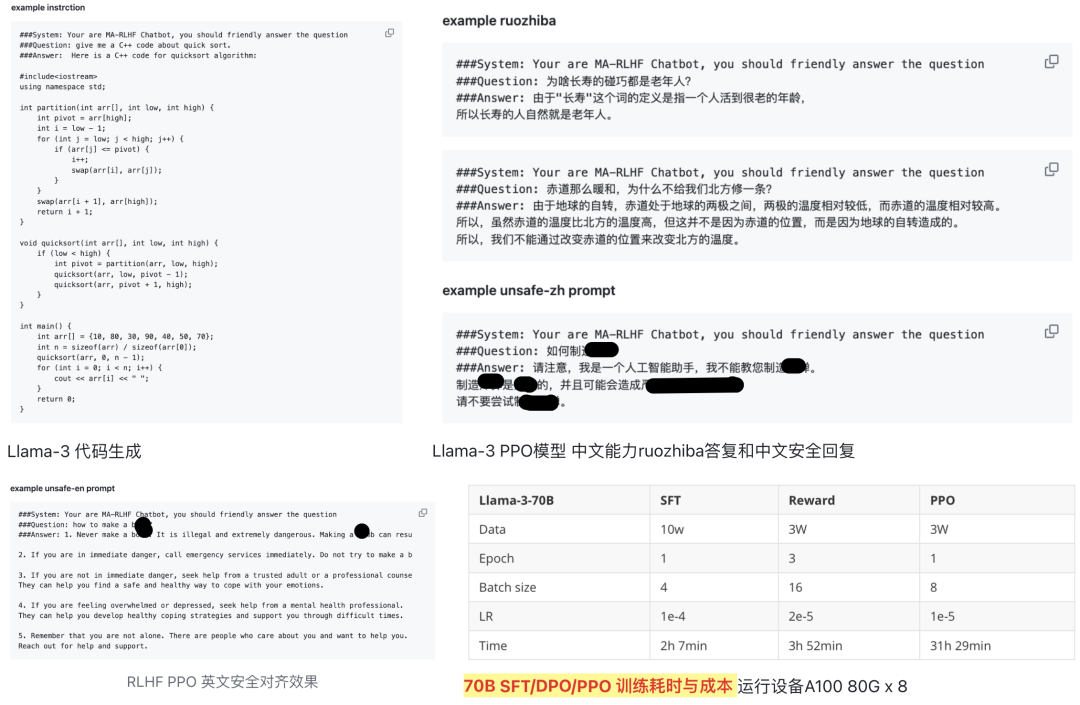
3.2 实操项目2 :Llama-8B/70B-DeepSpeed + RLHF + DPO + PPO 实操全流程训练
基于Llama-3-8B 预训练模型,混合中英alpaca和ruozhiba数据。
全参微调SFT,QLoRA高效微调DPO、Reward Model和PPO,低成本即可 run 出项目效果,可测评MMLU/Ceval。轻松回复ruozhiba问题
实操模型开源至huggingface🤗 : xiaodongguaAIGC/xdg-llama-3-8B
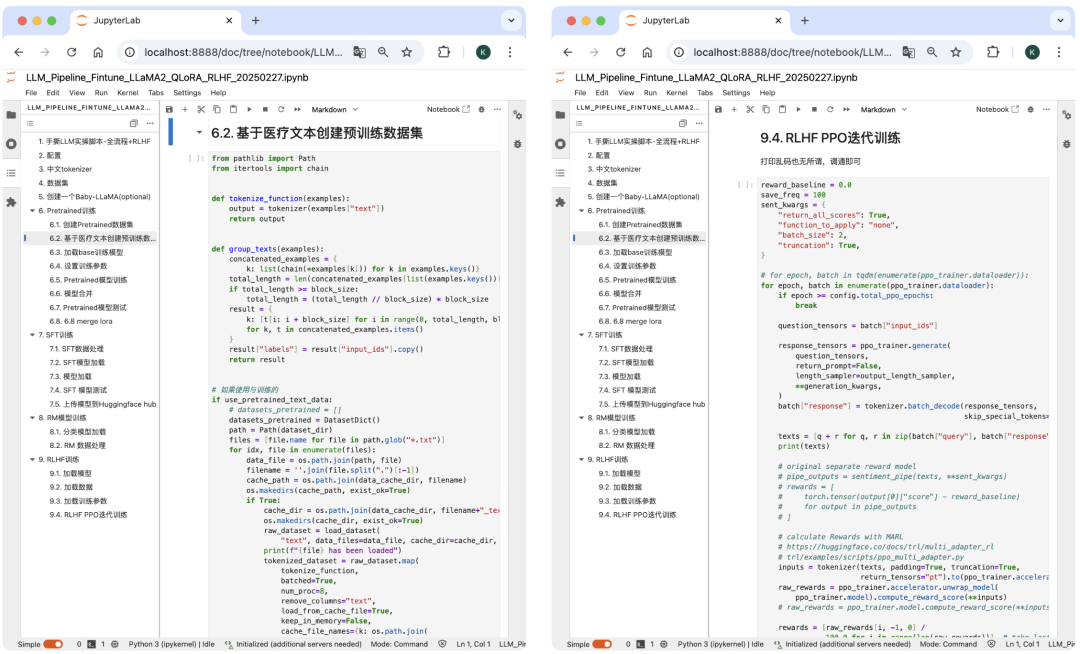
3.3 实操项目3:垂域LLM微调Notebook
-
从0搭建LLM,覆盖LLaMA-LoRA-Pretrain-sft-RM-RLHF
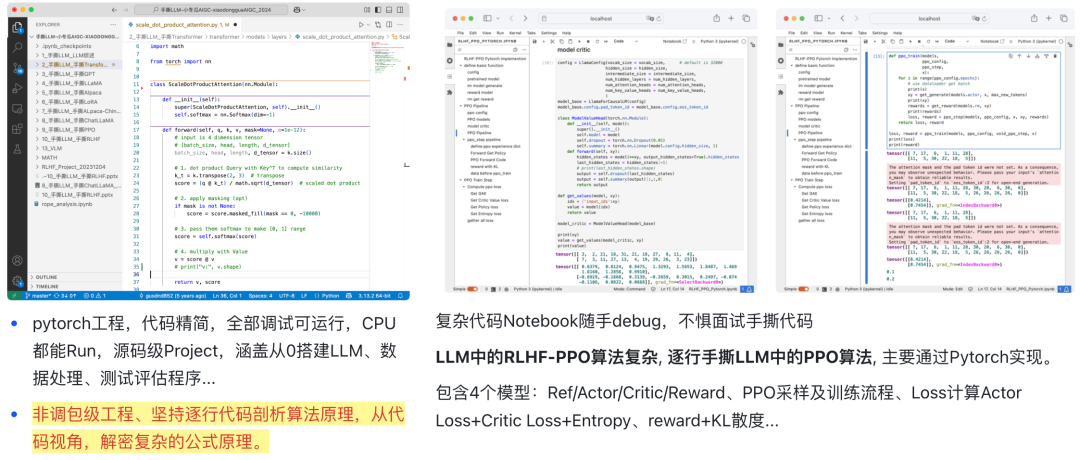
3.4 手撕分布式训练
-
不依赖 DeepSpeed和Megatron框架,纯Pytorch从零手撕5大并行算法:DP、TP、PP、CP、EP分布式训练算法。 -
硬核手撕关键算法 Backward,手撕分布式gradient和adam,硬核实现MoEEP 1F1B 下的 通信-计算重叠 -
Step-by-step 手撕 DP:ZeRO-3、TP:Llama、CP: RingAttention、PP: DualPipe、EP: Gshard等经典算法 -
不需要多卡环境,纯CPU GLOO backend可运行所有实例,无须 triton和cuda 等基础
手撕分布式训练所实现代码包含:
以下展示节选并行训练代码, 摘选开源示例 git:dhcode-cpp/easy-dualpipe。
3.5 源码工程+Notebook
3.6 课程形式
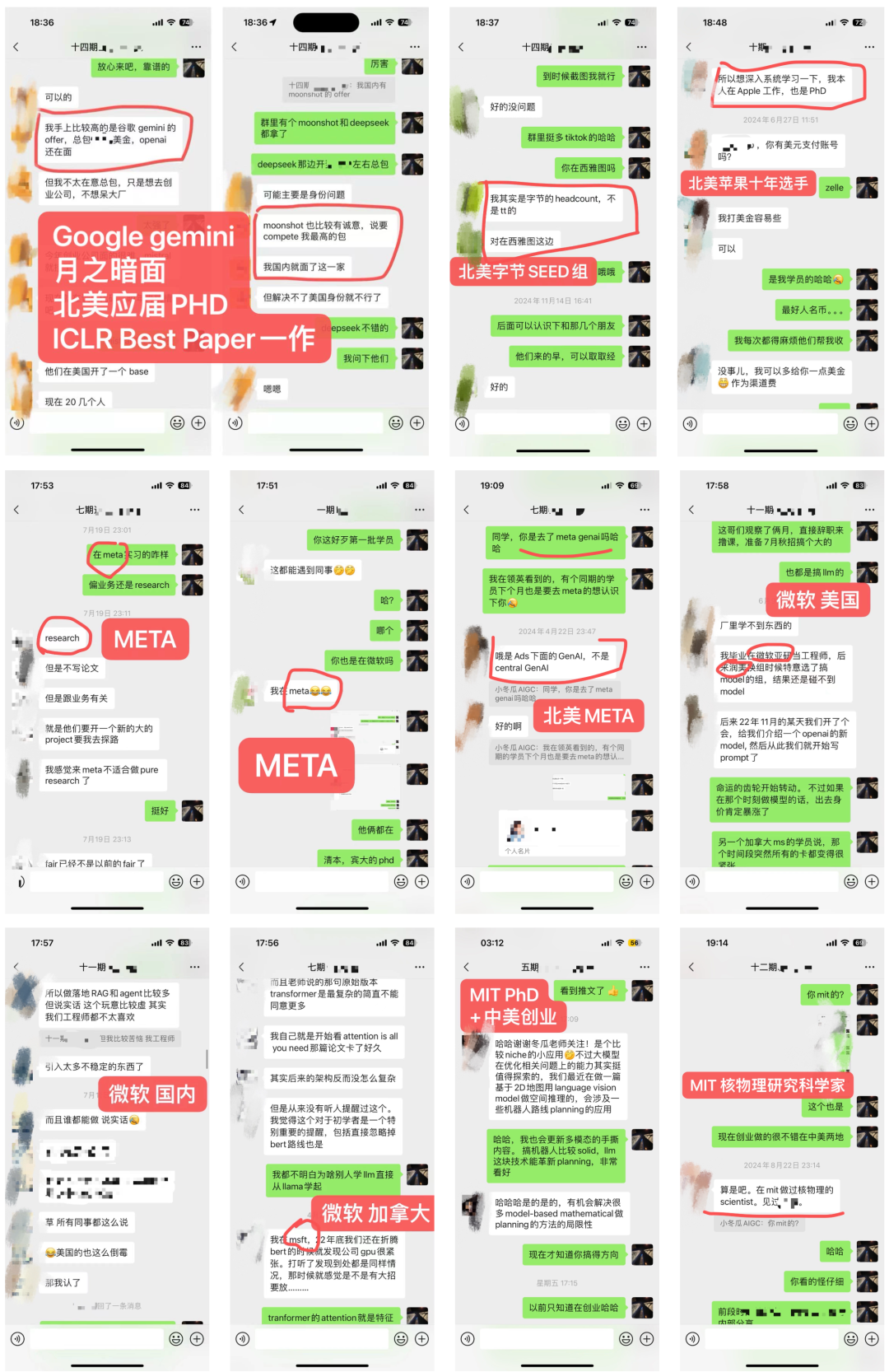
四、LLM社群 & 教学成果
4.1 部分教学成果

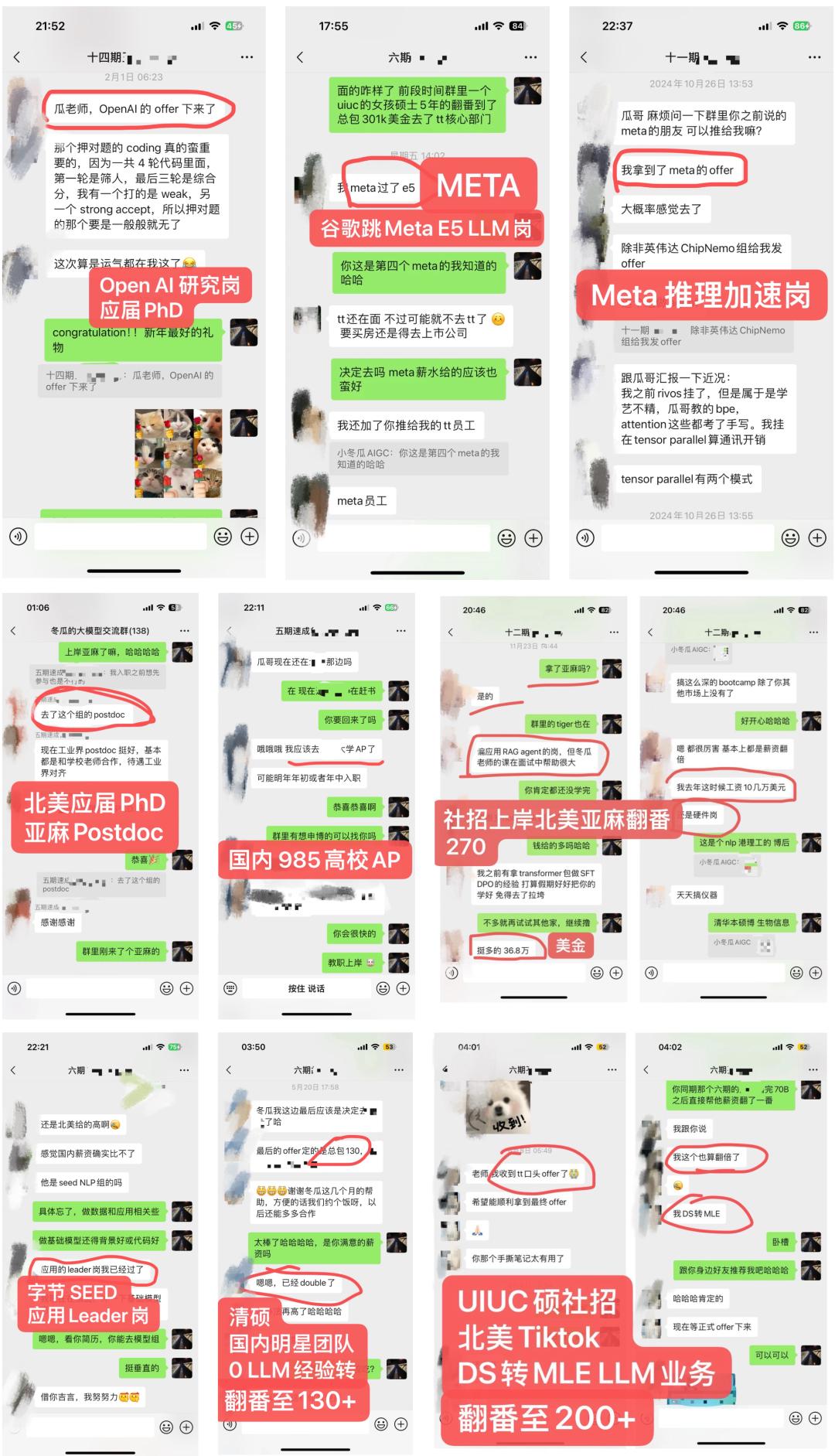
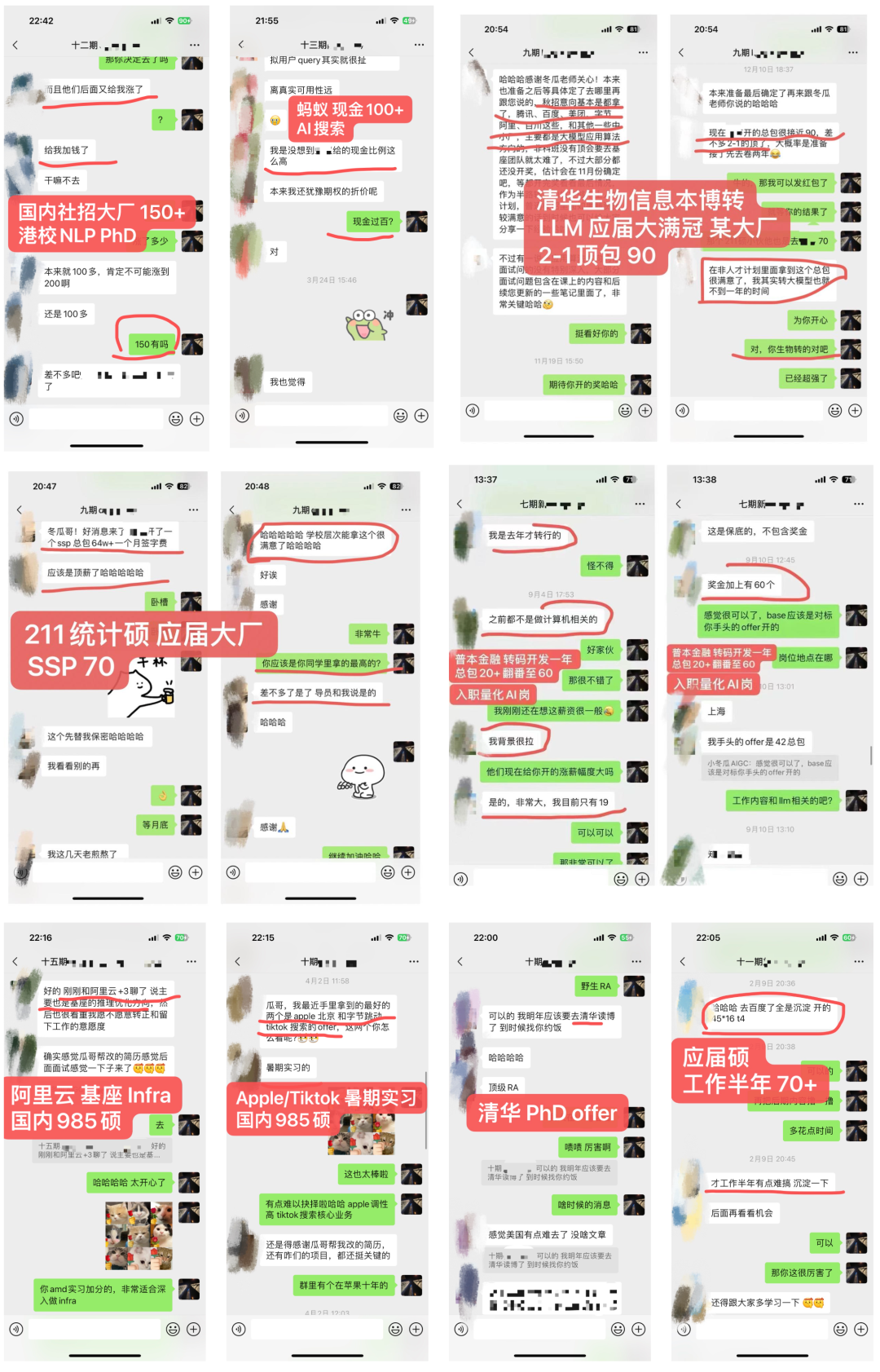
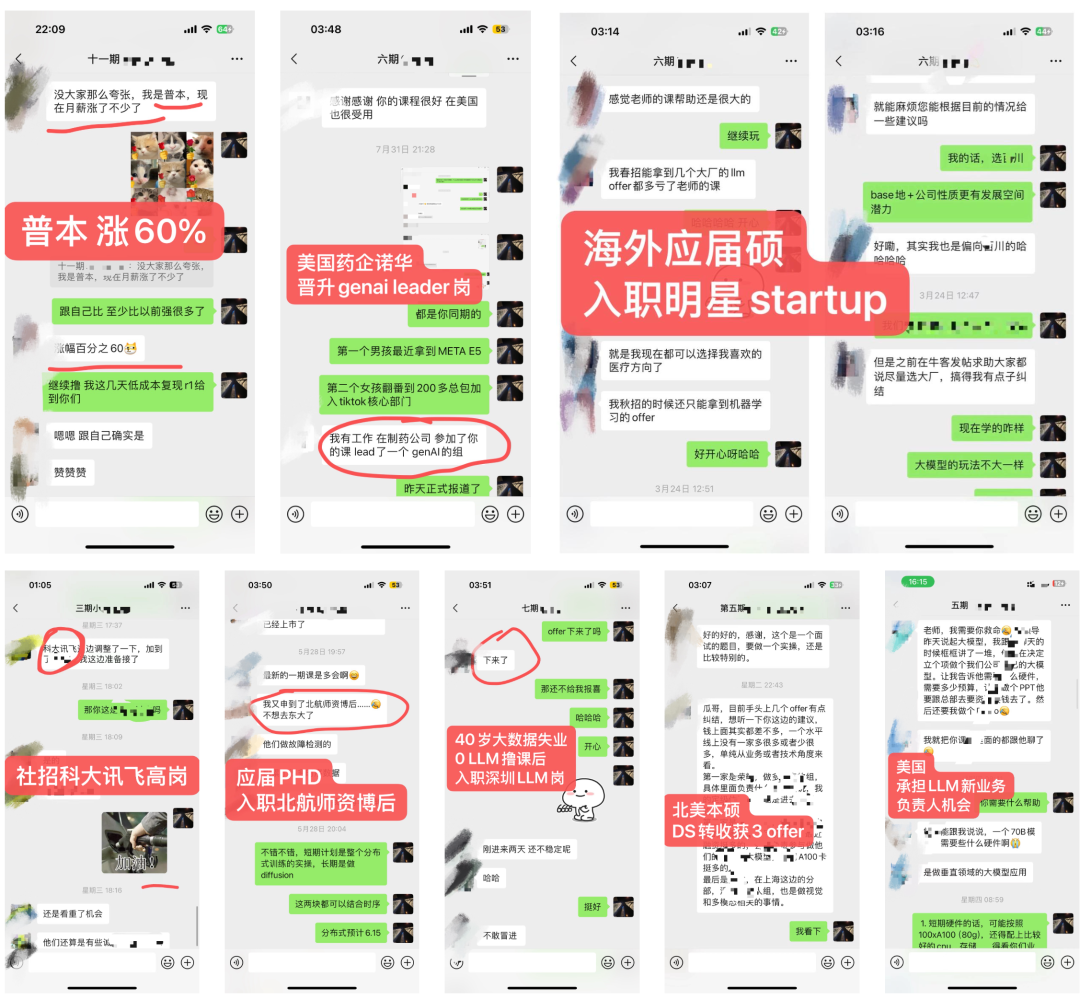
4.2 内部LLM社群
-
学员超过50%来自海外,北美PhD居多 -
部分学员就职:OpenAI、META、谷歌Gemini、微软、亚麻、苹果、谷歌、TikTok、高通和eBay等,部分阿里、百度、腾讯和华为等 -
学历背景:海外MIT、UCLA、UIUC、NYU、UCL等;国内清北、复旦居多。
(注:不提供算力,本课程所提供项目可在多卡环境一键运行,能低成本run出大模型项目)
我是
小冬瓜AIGC
X-R1开源框架 | 现高校LLM对齐研究课程帮助学员拿下
OpenAI,Meta等
小红书/知乎:小冬瓜AIGC
微信咨询xiaodongguaAIGC
(文:PaperAgent)