
“ PyTorch就是工具,而Transformer就是理论;而理论指导工具。”
我们都知道大模型的本质是一个神经网络模型,因此我们学习大模型就是在学习神经网络模型;但了解了很多关于神经网络的理论,但大部分人对神经网络都没有一个清晰的认识,也就是说神经网络到底是什么?它长什么样?
事实上所谓的神经网络本质上就是一个数学模型,里面涉及大量的数学运算;只不过其运算的主要数据类型是——向量,具体表现为多维矩阵。
PyTorch和Transformer
在神经网络的学习研究过程中,有两个东西是绕不过去的;一个是PyTorch神经网络开发框架,另一个就是Transformer神经网络架构。它们两者之间的关系就类似于编程语言和算法之间的关系,PyTorch就是编程语言;而Transformer就是算法。
Transformer即可以通过PyTorch框架实现,也可以通过其它框架实现,比如Tensorflow;PyTorch也可以实现其它的网络架构模型,比如CNN和RNN等。
因此,PyTorch也被称为科学计算框架,原因就在于神经网络的本质就是数学模型,而数学模型就是不停地做科学计算。
如下就是一个简单的使用PyTorch实现的简单神经网络模型,从代码中可以看出,一个神经网络主要由两部分组成,init初始化方法和forward前向传播方法。
import torchimport torch.nn as nn# 定义简单的神经网络架构class SimpleNeuralNetwork(nn.Module):def __init__(self):super(SimpleNeuralNetwork, self).__init__()self.layer1 = nn.Linear(10, 5) # 输入层10维,输出5维self.layer2 = nn.Linear(5, 2) # 隐藏层5维,输出2维def forward(self, x):x = torch.relu(self.layer1(x)) # 使用ReLU激活函数x = self.layer2(x) # 输出层不需要激活函数return x# 创建模型实例并输出网络结构model = SimpleNeuralNetwork()print(model)
在init方法中主要用来初始化一些参数,以及神经网络的网络层;比如Linear就是一个线性神经网络层——也叫做全连接层。
而forward方法就用来做一些科学计算,也就是神经网络模型中的传播算法等。比如上面代码中,就是对目标数据x先使用layer1网络层做一次线性变换,然后再使用relu函数进行激活。之后在使用layer2线性网络做一次线性变换,最终返回变换之后x的值。
在神经网络中,除了输入层与输出层之外;任何一层网络的输入都来自上层网络的输出;而任何一层网络的输出就是下层网络的输入。
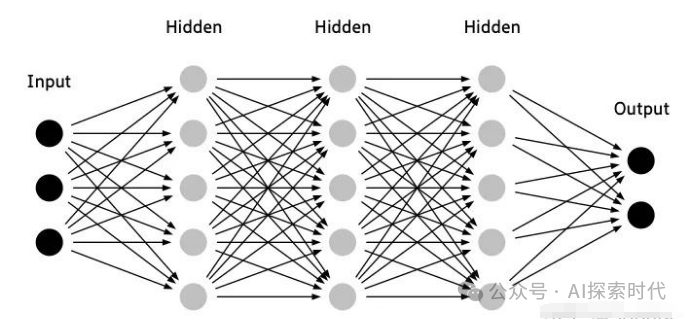
所以,神经网络的核心就是:“将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题”。
但是,为什么多维矩阵在经过多层神经网络的多次变换之后,就能够“理解”自然语言,“看懂”图片和视频;这个就是Transformer等神经网络架构需要解决的问题了。
从外面来看,神经网络就是一个黑盒,我们输入一些数据,然后神经网络这个黑盒就能根据某种规则给我们生成一些新的数据;但我们并不知道神经网络中到底发生了什么。
但把这个黑盒打开之后就可以看到,Transformer这个黑盒是由Encoder-Decoder编码器和解码器组成的;而编码器和解码器又由更小的组件组成——比如多头注意力,残差层等组成。
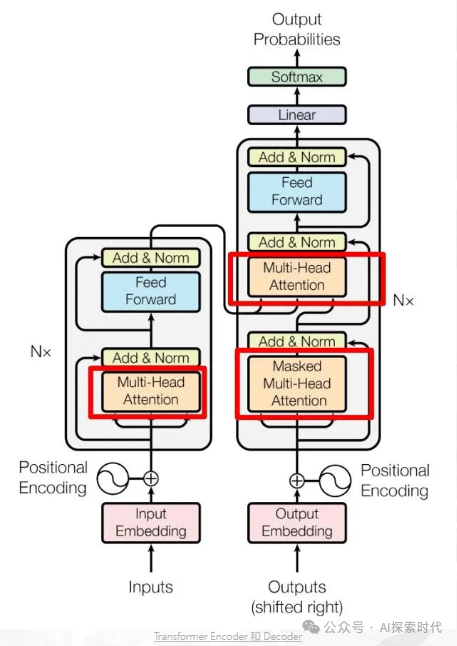
如上图所示就是Transformer论文提供的经典架构图;详细说明了Transformer的编码器和解码器是怎么构成的。
因此,PyTorch和Transformer的关系就是工具和理论的关系;没了工具就无法制造出神经网络,而没有理论神经网络就无法解决实际问题;这里PyTorch就是制造神经网络的工具;而Transformer就是让神经网络能够正常运行的理论。
(文:AI探索时代)