跳至内容
检索增强生成(RAG)在开放域问答任务中表现出色。然而,传统搜索引擎可能会检索浅层内容,限制了大型语言模型(LLM)处理复杂、多层次信息的能力。为了解决这个问题,我们引入了WebWalkerQA,一个旨在评估LLM执行网页遍历能力的基准。它评估LLM系统性地遍历网站子页面以获取对应信息的能力。同时我们提出了WebWalker,一个通过explorer-critic范式模拟人类网页导航的multi-agent框架。广泛的实验结果表明,WebWalkerQA具有挑战性,证明了结合WebWalker的RAG在实际场景中通过横向搜索和纵向页面挖掘集成的有效性。
RAG场景下,搜索引擎只是对query的横向网页搜索,缺少对搜索到的网页进行纵向的深度深挖!
动机
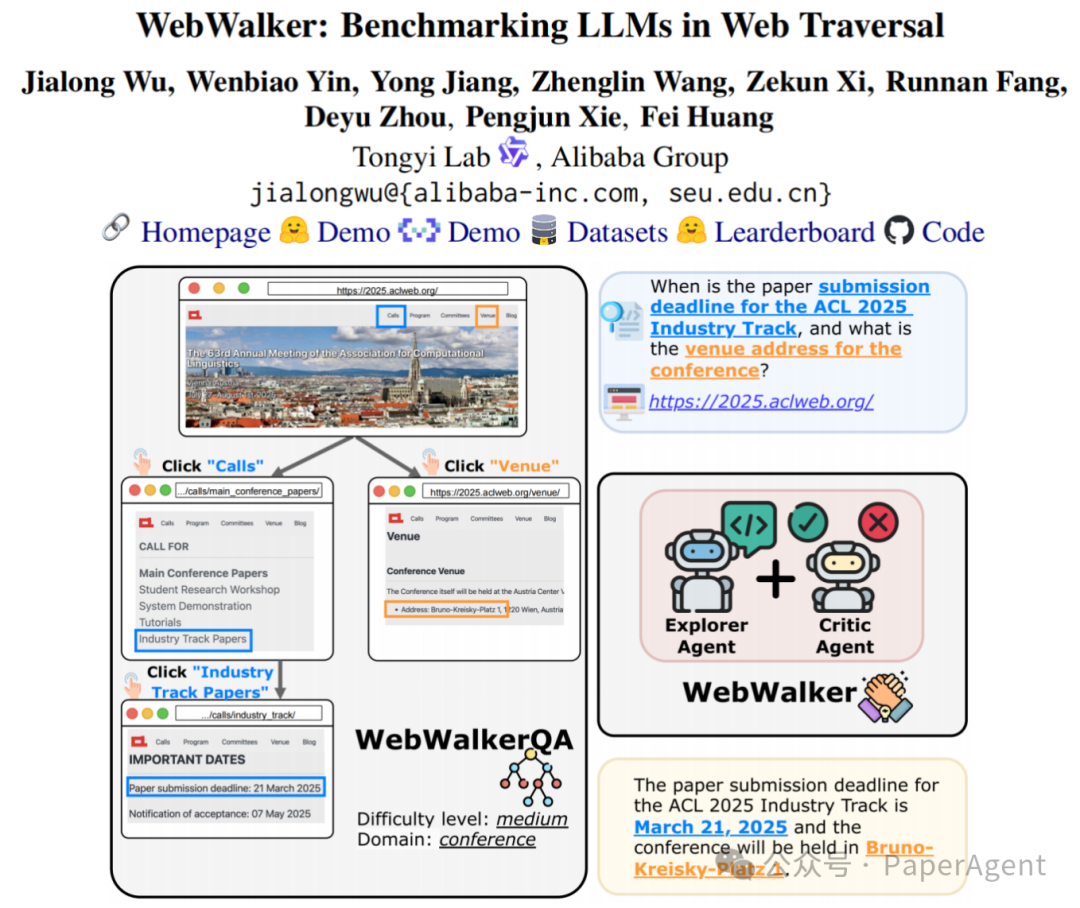
大型语言模型(LLM)通常处于知识固定状态(无法实时更新)。尽管使用检索增强生成(RAG)可以获取最新信息,但传统搜索引擎(如谷歌、百度等)的横向搜索方式限制了对信息的深层挖掘能力,无法像人类一样通过逐步点击等操作获取更多细节,从而更“聪明”地获取所需信息。因此,作者提出了一个新任务——Web Traversal,旨在给定与查询相关的初始网站,系统地遍历网页以揭露隐藏在其中的信息。
WebWalkerQA和WebWalker
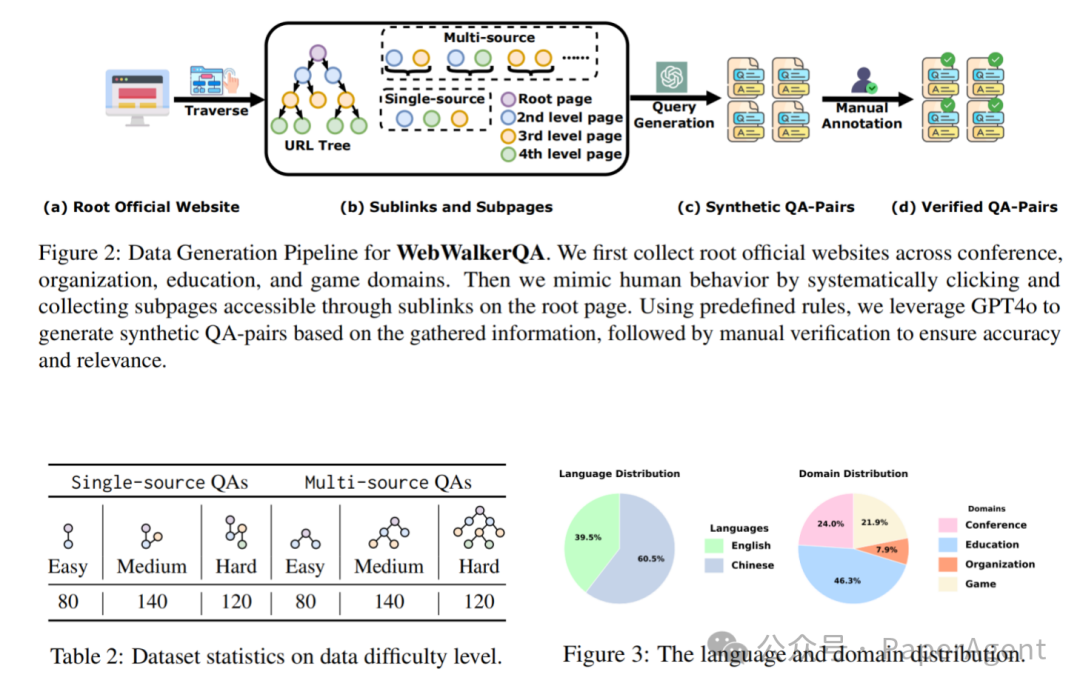
[Dataset] WebWalkerQA:根据网站的URL树,通过四个阶段,构建单源/多源的easy、medium、hard难度的QA对,涵盖四种常见官网来源及中英两种语言。
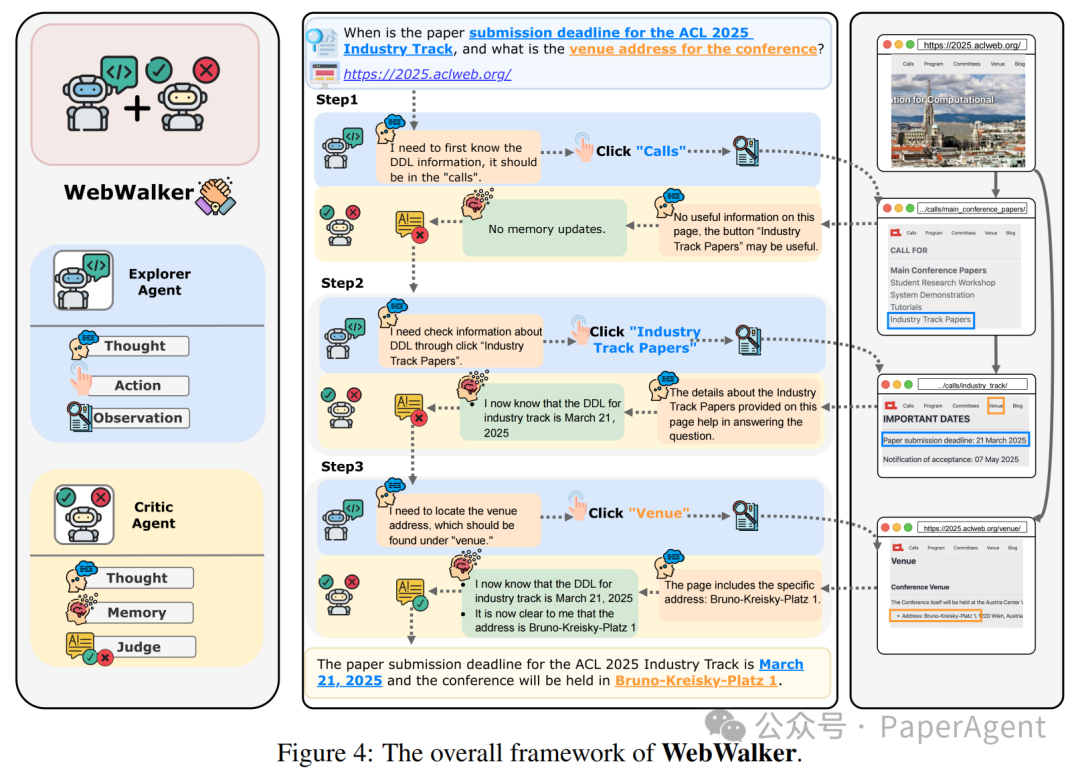
[Method] WebWalker:采用多代理框架,由一个探测代理(explorer agent)和一个裁判代理(critic agent)组成。探测代理基于ReAct,遵循思考-行动-观察范式,模拟人在网页中点击按钮跳转页面的过程;裁判代理则负责存储搜索过程中的信息,在探测代理点击的过程中,保存对查询有帮助的信息,并判断何时能够停止探测代理的探索。
实验
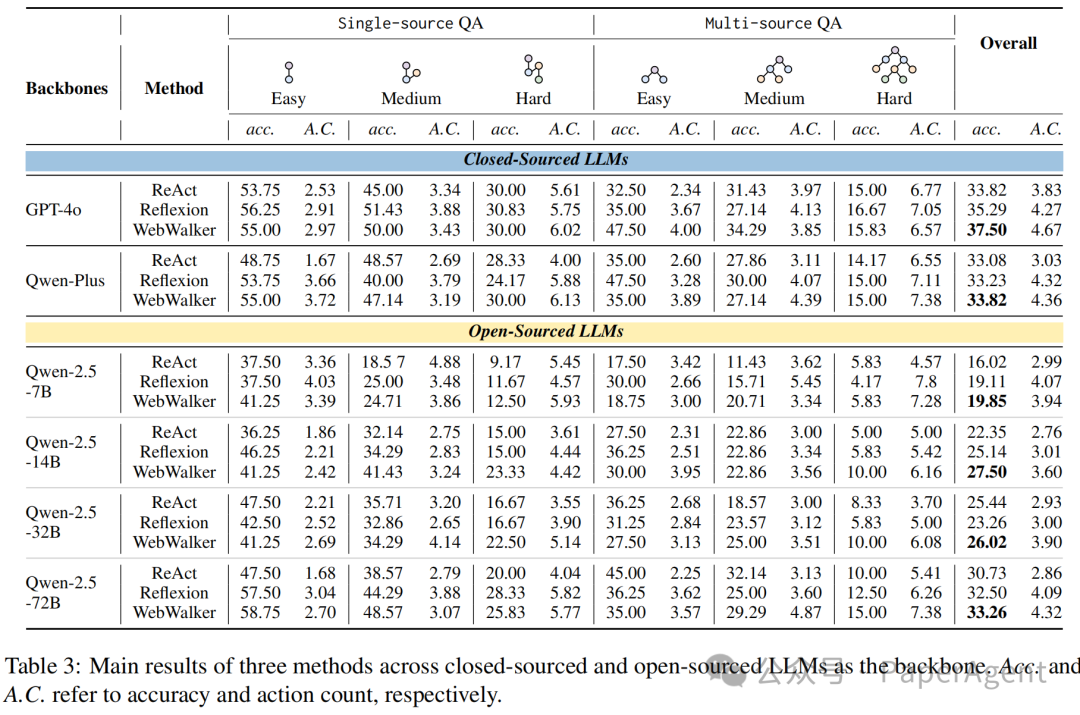
Table3展示了不同模型作为backbone,WebWalkerQA使用不同方法的代理性能结果。可以发现即使是最好的模型gpt-4o在这个任务也表现较差,任务中可能涉及到多跳推理和对文本的推理的能力。
Table4显示了在close book和目前较好的开源及商用RAG系统上的性能。在close book 设置下正确率只有10%,因为WebwalkerQA具有高时效性,而LLM具有知识的cutoff,这与第一个limitation呼应。在源及商用RAG系统上,最好的效果也只有40,验证了第二个limitation,传统搜索引擎可能会检索浅层内容,即使很多闭源的RAG系统使用了query改写或者agentic的操作,但是还是没有一步到位定位到的需要的web information source。
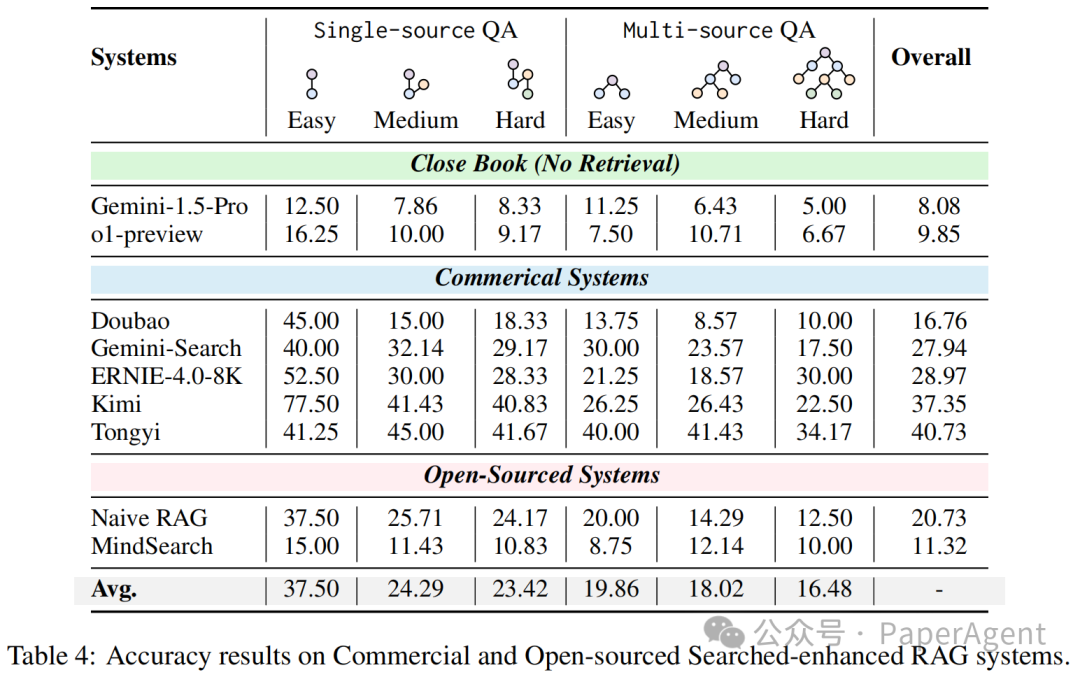
值得注意的是,webwalker中的memory对于回答query是非常重要的。如果rag链路中的搜索引擎可以当作对query进行横向搜索,webwalker是对页面的纵向深度探索,这是完全可以互补的。
因此可以把webwalker中的memory拼接到rag链路上,这种横向和纵向整合表现出色,在所有类别和难度的数据集上效果均有提升,证明了垂直探索页面对于提升RAG性能的潜力。这是对RAG二维探索的首次尝试!
此外,对webwalker 的挖掘点击次数进行scale up,看是否能得到更好的、更多的memory信息,随着挖掘点击次数的增大,不仅在webwalker上有较大提升,把memory加入到rag系统之后,性能也随之提升。这给rag系统进行test-time的拓展提供了新的角度。
💡 WebWalker的设计让人联想到pair programming(对编程),即两人协作,一个写代码,一个检查bug。探测代理和裁判代理的功能其实类似于这种协作。
💡 文章最后提出了三项发现,首次提出了RAG二维探索的scaling潜力,探讨如何更“聪明”地进行横向和垂直两个方向的探索(test-time compute)。
作者介绍:本文主要作者来自通义实验室和东南大学。通讯作者是通义实验室蒋勇和东南大学周德宇。第一作者吴家隆,东南大学硕士二年级,主要研究方向是Agent和Efficient NLP,该工作在阿里巴巴通义实验室RAG团队科研实习完成
(文:PaperAgent)



传统搜索引擎果然不够高级,只会检索浅层内容。RAG和WebWalkerQA才是真正的未来!