跳至内容
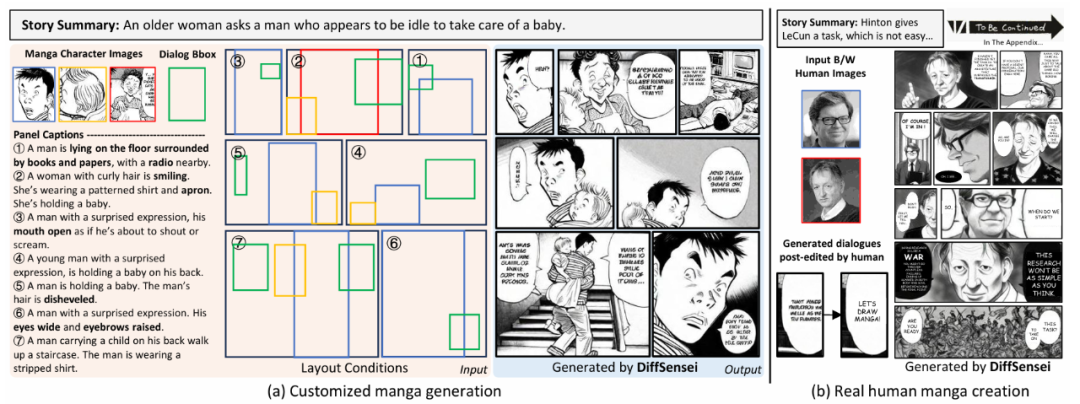
随着生成式人工智能技术(AIGC)的突破,文本到图像模型在故事可视化领域展现出巨大潜力,但在多角色场景中仍面临角色一致性差、布局控制难、动态叙事不足等挑战。
为此,北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。
-
论文地址:https://arxiv.org/pdf/2412.07589
-
GitHub 仓库:https://github.com/jianzongwu/DiffSensei
-
项目主页 – https://jianzongwu.github.io/projects/diffsensei/
-
数据链接 – https://huggingface.co/datasets/jianzongwu/MangaZero
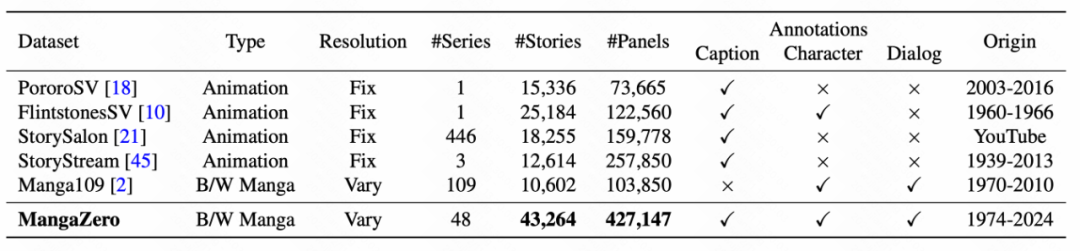
该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制,并支持对话布局的灵活编码。同时,团队发布了首个专为漫画生成设计的 MangaZero 数据集(含 4.3 万页漫画与 42.7 万标注面板),填补了该领域的数据空白。实验表明,DiffSensei 在角色一致性、文本跟随能力与图像质量上显著优于现有模型,为漫画创作、教育可视化、广告设计等场景提供了高效工具。
团队公开了训练,测试代码、预训练模型及 MangaZero 数据集,支持本地部署。开发者可通过 Hugging Face 获取资源,并利用 Gradio 界面快速体验生成效果。
-
角色一致性:跨面板保持角色特征稳定,支持连续叙事,可根据文本动态调整任务状态和动作。
-
布局精准:通过掩码机制与边界框标注,实现多角色与对话框的像素级定位。
-
动态适应性:MLLM 适配器使角色可依据文本提示调整状态(如 “愤怒表情” 或 “挥手动作”),突破传统模型的静态生成限制。
DiffSensei 生成整页漫画结果,每页漫画的故事梗概在其上方,更多结果在项目主页
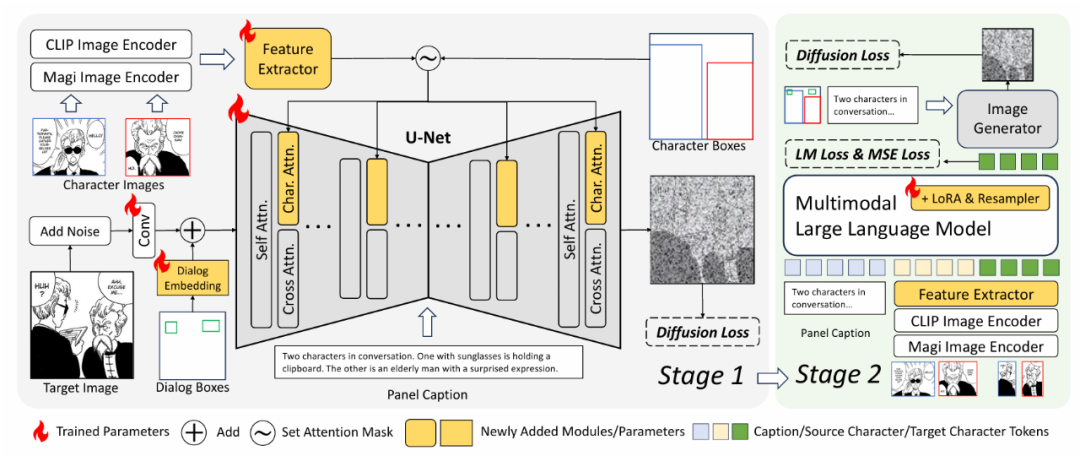
DiffSensei 的技术架构以 “动态角色控制” 和 “高效布局生成” 为核心,通过以下模块实现端到端的漫画生成:
-
结合 CLIP 图像编码器 与 漫画专用编码器(Magi),提取角色语义特征,避免直接复制像素细节导致的 “粘贴效应”。
-
通过重采样模块将特征压缩为低维 token,适配扩散模型的交叉注意力机制,增强生成灵活性。
-
掩码交叉注意力机制:复制扩散模型的键值矩阵,创建独立的角色注意力层,仅允许角色在指定边界框内参与注意力计算,实现布局的像素级控制。
-
引入对话布局嵌入,将对话框位置编码为可训练的嵌入向量,与噪声潜在空间融合,支持后期人工文本编辑。
-
MLLM 驱动的动态适配器:以多模态大语言模型(如 LLaVA)为核心,接收面板标题与源角色特征,生成与文本兼容的 目标角色特征,动态调整表情、姿势等属性。训练中结合 语言模型损失(LM Loss) 与 扩散损失,确保生成特征既符合文本语义,又与图像生成器兼容。
-
-
第一阶段:基于 MangaZero 数据集训练扩散模型,学习角色与布局的联合生成。
-
第二阶段:冻结图像生成器,微调 MLLM 适配器,强化文本驱动的角色动态调整能力 813,从而适应与文本提示对应的源特征。在第一阶段使用模型作为图像生成器,并冻结其权重。
上图展示了 MangaZero 数据集的基本信息,该数据集中包含最著名的日本黑白漫画系列。图 a 显示了所有 48 系列的封面。这些漫画系列之所以被选中,主要是因为它们的受欢迎程度、独特的艺术风格和广泛的人物阵容,为该模型提供了发展强大而灵活的 IP 保持能力。
图 c 描绘了数据集中的面板分辨率分布。为了提高清晰度,其中包括三条参考线,分别表示 1024×1024、512×512 和 256×256 的分辨率。大多数漫画画板都集中在第二行和第三行周围,这表明与最近研究中通常强调的分辨率相比,大多数画板的分辨率相对较低。这一特性是漫画数据所固有的,该工作专门针对漫画数据。因此,可变分辨率训练对于有效处理漫画数据集至关重要。
MangaZero 数据集相比同类数据,规模更大,来源更新,标注更丰富,漫画以及画面分辨率更多样。与广为人知的黑白漫画数据集 Manga109 相比,MangaZero 数据集收录了更多在 2000 年之后出版的漫画,这也正是其名称的由来。此外,MangaZero 还包含一些 2000 年之前发行、但并未收录于 Manga109 的著名作品,例如《哆啦 A 梦》(1974 年)。
上图展示了 MangaDex 数据集的构建过程,作者通过三个步骤构建 MangaZero 数据集。
-
-
步骤 2 – 使用预先训练好的模型自主为漫画面板添加相关标注。
-
步骤 3 – 利用人工来校准人物 ID 标注结果。
-
多 ID 保持,灵活可控的图片生成训练。漫画数据天然拥有同一个人物多个状态的图像,对可根据文本灵活控制人物状态的定制化生成训练有很大帮助。
-
风格可控的漫画生成。MangaZero 中包含的漫画系列多样且具有代表性,可以在模型结构中增加风格定制模块,实现画风可控的漫画生成。例如生成龙珠风格的柯南。
DiffSensei 通过多模态技术的深度融合,重新定义了 AI 辅助创作的边界。其开源属性与行业适配性,将加速漫画生成从实验工具向产业级应用的跨越。未来,研究方向可扩展至彩色漫画与动画生成,进一步推动视觉叙事技术的普惠化。
(文:机器之心)