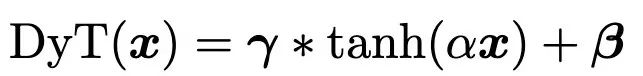跳至内容

对于如今的AI大模型而言,Transformer具有极其重要的影响。
作为一种基于注意力机制的深度学习架构,Transformer最初是由Ashish Vaswani等计算机科学家于2017年在NeurIPS(神经信息处理系统大会)上提出,逐渐成为NLP领域许多最先进模型的基础。
它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),在自然语言处理任务中取得了显著的效果,使得大规模预训练语言模型成为可能,间接推动了GPT等AI大模型的问世。
不过从今天开始,Transformer可能要迎来新变化。
“残差神经网络发明人”、麻省理工学院副教授何恺明与图灵奖得主、“卷积网络之父”Yann LeCun的最新合作论文提出“无需归一化的Transformer”,目前已入选CVPR 2025,该发现有望进一步改进AI模型性能,给开发者们带来新思路。
简单来说,归一化层在现代神经网络中无处不在,长期以来一直被认为是必不可少的。
归一化层的主要作用是使网络的输入数据分布更加稳定,减少内部协变量偏移(Internal Covariate Shift),从而使得网络更容易训练,提高模型的泛化能力。不同的归一化层适用于不同的网络结构和任务场景,选择合适的归一化层对于构建高效的神经网络至关重要。
而这篇最新论文研究表明,通过一种极其简单的技术,无需归一化的Transformer模型能够达到相同甚至更好的性能,是不是有点不可思议?
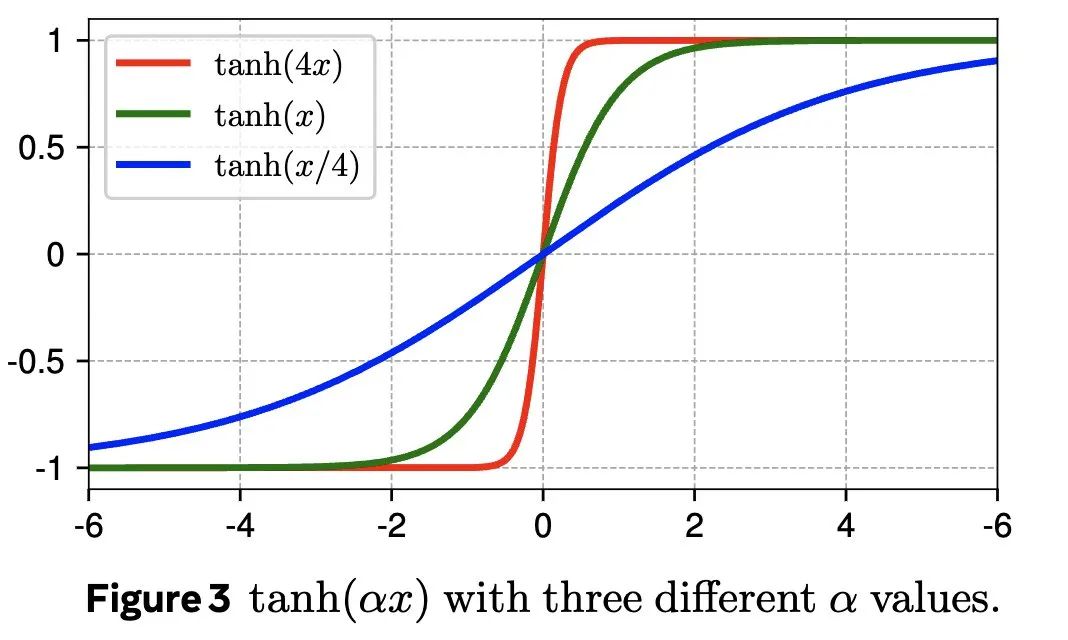
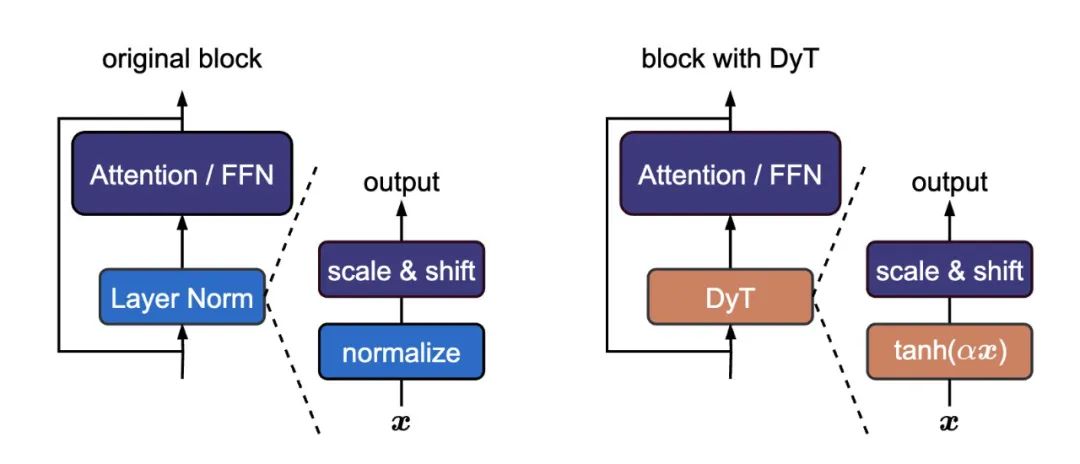
研究人员引入了动态双曲正切函数(DyT),可以直接替代Transformer模型中的归一化层。
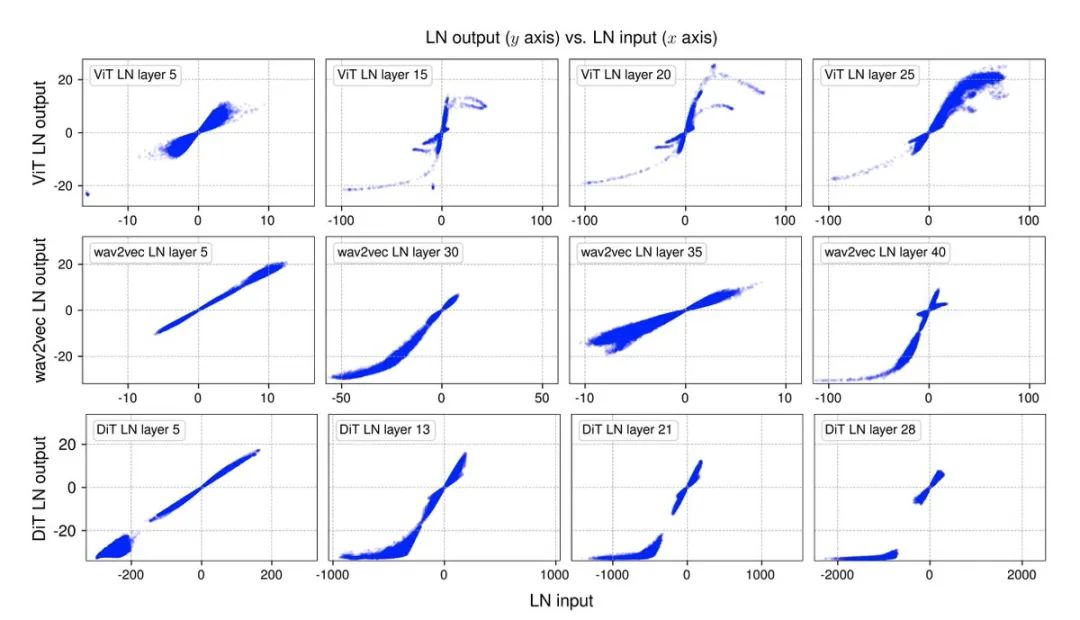
DyT的灵感来源于这样一个观察结果:Transformer模型中的层归一化常常会产生类似双曲正切函数的S形输入输出映射。通过整合DyT,无需归一化的Transformer模型能够达到甚至超过带有归一化层的Transformer模型的性能,而且在大多数情况下无需进行超参数调整。
论文作者在各种不同的场景中验证了带有 DyT 的 Transformer模型的有效性,涵盖了从识别到生成任务、从监督学习到自监督学习,以及从计算机视觉到语言模型等多个领域,这些发现挑战了传统观念中归一化层在现代神经网络中不可或缺的认知,并为深入理解归一化层在深度网络中的作用提供了新的视角。
Meta FAIR实验室研究科学家刘壮作为论文负责人,在社交平台分享了几点论文摘要。
1、发现了一个非常简单的标准化层替代方案:缩放的tanh函数,团队称之为动态Tanh,或DyT。
2、这实际上是由一个非常简单的观察驱动的:LayerNorm使用类似于tanh的S形曲线将其输入转换为输出,它压缩极端值,同时保持中心的线性形状。
4、将层归一化(LayerNorm)/旋转尺度归一化(RSMNorm)替换为动态双曲正切函数(DyT),并在以下的Transformer模型上进行测试:
涵盖了视觉领域的监督学习(ViT和ConvNeXt)、视觉领域的自监督学习(MAE和DINO)、扩散模型(DiT)、大型语言模型(LLaMA)、语音领域的自监督学习(wav2vec 2.0)和DNA序列建模(HyenaDNA和Caduceus),在每种情况下,采用DyT的Transformers都实现了与标准化Transformers相似或更好的性能。
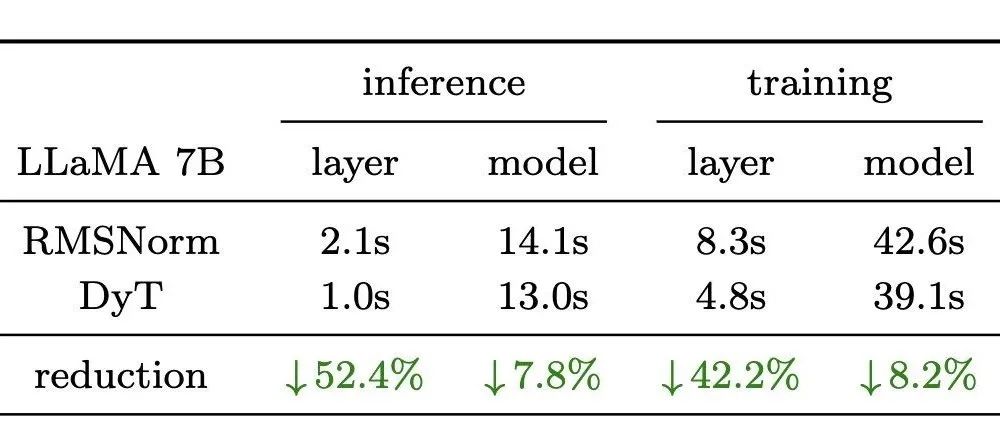
5、在英伟达H100 GPU上,动态双曲正切函数(DyT)的运算速度比均方根归一化(RMSNorm,在前沿的大语言模型中较为常用)要快。
DyT旨在取代Transformers中的规范化层,使用DyT的模型可实现与经过规范化的模型相似或更好的性能。
论文负责人刘壮表示,鉴于模型训练和推理可能需要数千万的计算资源,DyT有可能进一步帮助行业降低成本,很期待看到它接下来会找到什么应用。
目前,该团队在GitHub上开源提供了完整代码库,开发人员可以进行测试一番:https://github.com/jiachenzhu/DyT
除了Yann LeCun,这篇论文包含来自4位华人作者的共同努力。
何恺明清华大学毕业,香港中文大学获得博士学位,目前在美国麻省理工学院(MIT)担任电气工程与计算机科学系的副教授,研究涵盖计算机视觉和深度学习领域的广泛主题,最为人所知的研究成果是深度残差网络(ResNets),其中的残差连接如今在现代深度学习模型中随处可见,包括Transformer模型(如GPT、ChatGPT)、谷歌的AlphaGo Zero、AlphaFold等等。
何恺明的多篇论文在CVPR、ICCV、NeurIPS、ECCV等国际学术会议获得最佳论文荣誉,论文引用量超过50万次,每年的引用量增长超过10万次。
刘壮是Meta基础人工智能研究部门(FAIR)的一名研究科学家,在加州大学伯克利分校电气工程与计算机科学系获得计算机科学博士学位,导师是特雷弗・达雷尔(Trevor Darrell)教授,本科毕业于清华大学姚班。
他此前还主导了密集连接卷积网络(DenseNet,该成果曾荣获CVPR的最佳论文奖)和ConvNeXt的研发工作,两者都是深度学习和计算机视觉领域中应用最为广泛的神经网络架构之一。
陈鑫磊毕业于中国浙江大学计算机科学系,在卡内基梅隆大学语言技术研究所攻读博士学位,目前在Meta FAIR担任研究科学家,研究领域聚焦在预训练和理解视觉表征。此前和何恺明、Yann LeCun、刘壮等合作发表过多篇论文。
朱家晨香港理工大学计算机科学专业毕业,目前是纽约大学柯朗数学科学研究所计算机科学专业的五年级博士研究生,导师是Yann LeCun, Meta 公司基础人工智能研究部门的访问研究员,研究重点是图像和视频的自监督学习,以及为视觉语言模型(VLM)预训练视觉编码器。
被CVPR 2025收录的论文代表了计算机视觉和模式识别领域的较高水平。
据了解,CVPR 2025共收到13008份有效投稿,录用2878篇,录用率为22.1%,能在同行学术竞争中脱颖而出,这些论文通常会在理论、方法、技术或应用等方面具有显著创新,本次论文里提到的“DyT”方法能否给行业带来新的启发,衍生出广泛的影响值得关注。
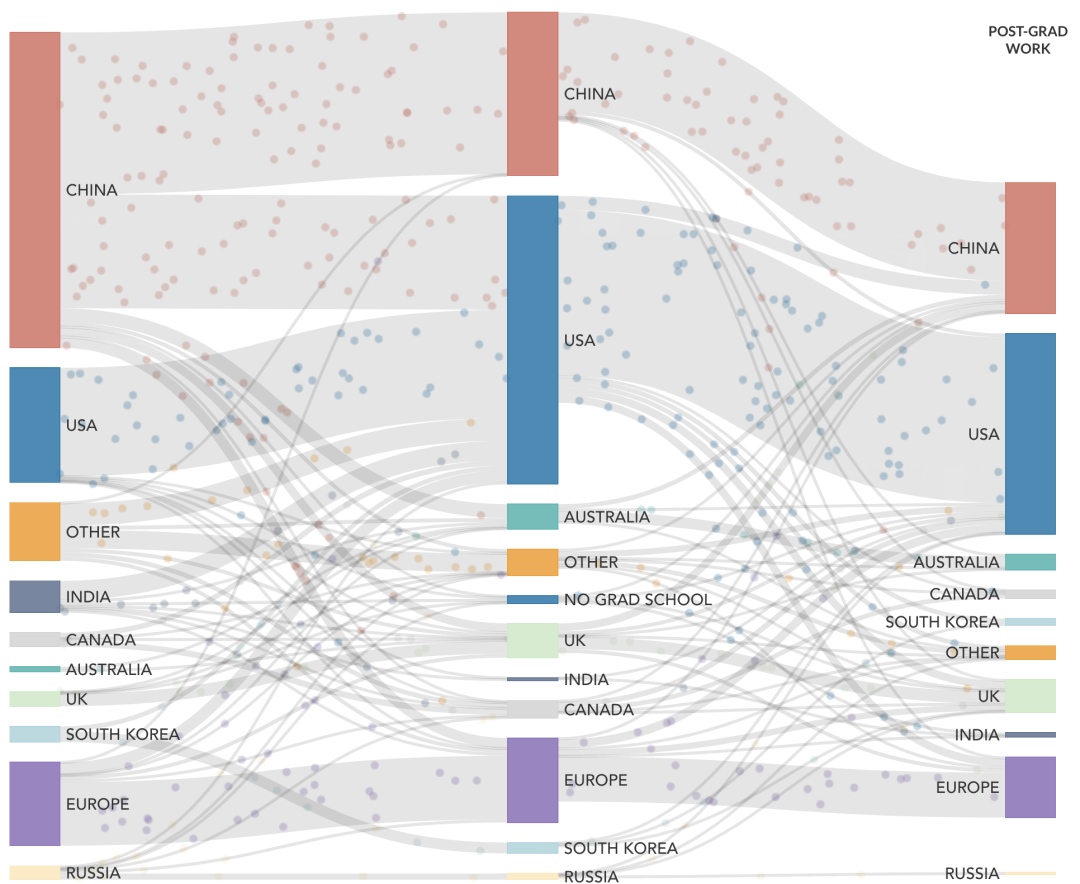
近些年,中国学者对于AI的学术贡献量非常大,MacroPolo发布的《全球人工智能人才追踪调查报告2.0》显示,2019年,原国籍为中国的顶尖AI研究人员占比为 29%,到2022年,这一比例升至47%,中国为世界输送了大量的AI人才。
《自然》增刊“自然指数2024人工智能”显示,2019年至2023年,AI研究产出增幅最大的10家机构中,有6家来自中国,分别是中国科学院、北京大学、清华大学、浙江大学、中国科学技术大学和上海交通大学。
可以说,更多的学术创新研究推动着中国在AI产业领域呈现出强劲发展态势,期待更多来自中国学者的创新AI研究出炉。
(文:头部科技)