
1. 前言
本文主要是以两个目的出发:
-
第一个是简单地介绍下LLM训练的一个完整流程,侧重点在于帮助认识这个过程,而不是严谨地对每一个剖析细节,因此基本没有公式推导,但一些必要的符号是避免不了的; -
第二个是尝试使用小模型(0.5B)来复现DeepSeek-R1的思维链模式,仅仅是一个demo级别的实践。
(本人水平有限,如若发现有不对的,欢迎交流探讨)
2. 如何从零训练一个LLM
最简单的语言来描述一个LLM的工作(推理)机制:
-
将一段输入文本映射为对应的tokens,然后给到transformer模型,预测下一个token的概率分布,选择概率最高的token(当然,也会有采样topK个概率最高的tokens); -
本次选择的token + 输入文本的tokens + 之前预测输出的tokens,拼接起来,继续给到transformer模型,预测下一个token的概率分布; -
重复第2步,直到模型输出代表结束的token; -
最后,将输出的全部tokens映射回对应的自然语言文本。
2.1 预训练阶段
预训练可以类比一下以前BERT时代【预训练-微调】中预训练的方法,会使用互联网爬取的文本数据,比如wiki、百度百科,这一步是为了让模型获得next token prediction的能力,即能够基于已知的上文输出未知的下文,预训练得到模型是具备续写的能力,比如:
|
|
|
|---|---|
|
|
中国浙江省杭州市西湖区龙井路1号,汇水面积为21.22平方千米,湖面面积为6.38平方千米,总面积约60平方千米,为自然与人文景观。 |
但是呢,一般的提问方式或者说对话方式应该是:
|
|
|
|---|---|
|
|
中国浙江省杭州市西湖区龙井路1号,汇水面积为21.22平方千米,湖面面积为6.38平方千米,总面积约60平方千米,为自然与人文景观。 |
为什么会产生这种差异呢?
-
由于预训练的语料大部分来自于网页,许多都是段落形式的长篇文本,然后按照一定规则进行切分。 -
给模型输入前面一段文本,让模型去学习next token prediction的任务,即预测下一段文本,这就导致模型的输出是偏向于续写的 -
这便导致了不符合人类的对话习惯,因此产生后续一系列的post-train(后训练)工作。
2.2 Post-Training(后训练)
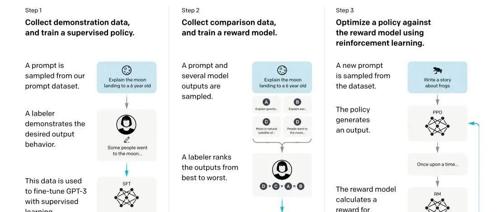
后训练的步骤一般会涉及以下三个步骤:
-
标注数据,进行监督微调学习(SFT,Supervised Fine-Tuning),这也是常常提到的指令微调 -
标注对比数据(comparison data),训练一个奖励模型,可以判断模型输出的质量 -
通过奖励模型来进行强化学习,进一步提升模型的能力
2.3 指令微调(SFT)

这一步需要收集高质量的数据样本,什么样的数据就会让最终的模型呈现出什么样的行为,正如上一步所说的,预训练模型是输出是不符合人类对话习惯,而这一步就需要收集高质量的对话数据,来让模型学习到这种能力。
对于先驱者OpenAI来说,无疑是需要巨大的人力成本来收集和标注这些数据的。而对于后来者,我们一方面可以人工标注数据,但更多的往往是从市场上选择某一个或几个强大的模型(比如GPT、DeepSeek)去蒸馏数据:
-
设计一个prompt,让LLM生成问题的同时,又附带着回答; -
或者自己有着垂直领域的百科知识,就可以设计Prompt去让LLM生成对应的提问,还可以让LLM对知识数据进行润色和丰富; -
这样我们就可以得到这种一问一答的训练样本来进行监督微调了。
(当然实际情况往往复杂得多)
总的来说,这一步就是收集对应的数据,然后加载上一步的预训练模型作为起点,进行监督微调(SFT),让模型学会相应的能力,实现指令对齐:
-
比如现在最为普遍的Chat模型,便是收集符合人类对话习惯的问题(prompt)- 答案(output)。 -
但是,其实这里的prompt和output可以套到其他的实践场景中,比如意图识别等,prompt对应表达意图行为的描述,output对应预测的意图和提取的参数
2.4 奖励模型(Reward Model,RM)

这一步的目标是使用上一步的SFT模型作为初始化(最后增加一层分类器),训练一个奖励模型,能够为一条样本进行打分,以此来区分好样本和坏样本。比如下面的例子,chosen明显比rejected的回答更恰当,模型对chosen的打分应该更高。
{
"prompt": "你是谁",
"chosen": "您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-V3。如您有任何任何问题,我会尽我所能为您提供帮助。",
"rejected": "有什么可以帮您的?"
}
RM的训练流程大致如下:
-
给定一个prompt,人工对LLM的多个输出进行比较,标注哪个输出是更符合人类偏好的(更合理) -
或者可以参考数据蒸馏的做法来构造数据,让LLM同时输出好的回答和坏的回答 -
有了不同质量的回答数据后,需要标注好坏对比顺序,比如上面例子,标记 chosen和rejected的输出,只需要知道chosen>rejected即可 -
然后去训练一个分类Reward Model,训练目标是拉开好样本和坏样本的分数差距,训练好的Reward Model可以为每一条预测对应的分数(结束token的logit)
下面是Reward Model训练样本的一个通用格式:
(chosen和rejected是对于同一个Prompt的不同回答)

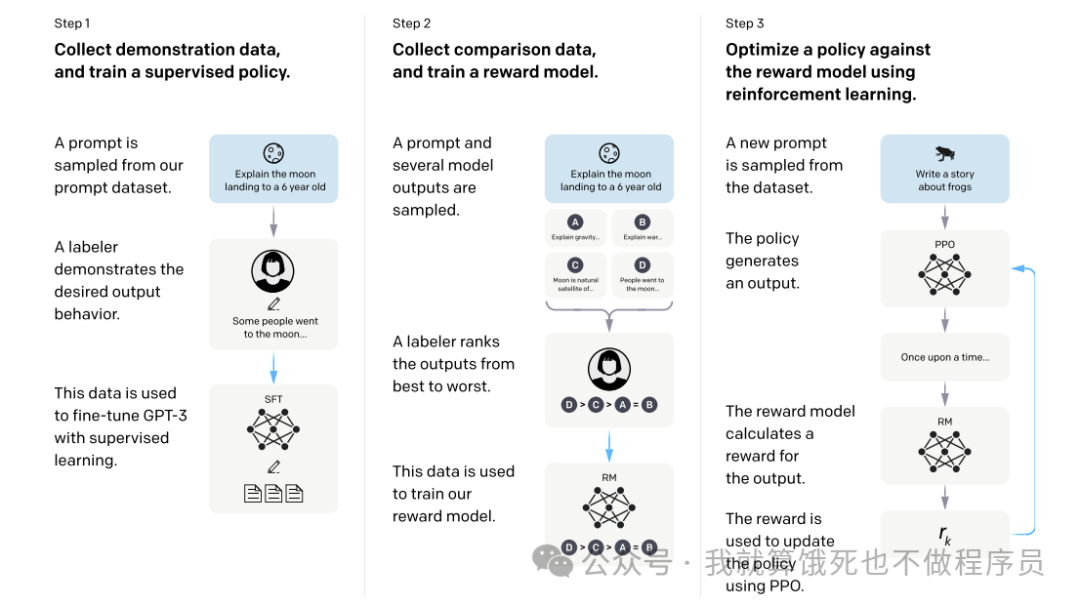
奖励模型一方面对于后续的强化学习起着关键作用,一方面在迭代训练也是至关重要。比如,下图为Llama3的训练迭代流程:
-
加载上一步的SFT模型作为Reward Model的初始化 -
按照上述的思路,不断收集大量的偏好数据pair,训练出一个Reward Model -
收集一批 <Prompts>,使用本轮最好的模型,做 K次采样生成,这样每个Prompt就得到了K条 <Prompt, Output_k> -
通过Reward Model对每一个Prompt的采样生成 <Prompt, Output_k> 进行打分,然后筛选出分数最高的top-N个样本,这便是常常提到的拒绝采样 -
使用留下的top-N的样本作为SFT的训练样本,再加上部分关于特定能力的指令微调数据,训练出一个SFT模型 -
接着,再进入强化学习(DPO)的训练,最后的模型便是本轮最好的模型 -
重复步骤2-6,不断对模型进行迭代优化
2.5 强化学习
 在经过上述的步骤训练出一个SFT模型,最后一般都会在使用强化学习,让模型的能力更上一层楼。今天简单介绍下几种常用的强化学习方法。
在经过上述的步骤训练出一个SFT模型,最后一般都会在使用强化学习,让模型的能力更上一层楼。今天简单介绍下几种常用的强化学习方法。
在此先引入强化学习中涉及的几种模型的概念:
-
Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上一步的SFT初始化而来。 -
Value Model(Critic Model):用于预估当前模型回复的每一个token的收益。接着,还会进一步计算累积收益,累加每一个token的收益时不仅局限于当前token的质量,还需要衡量当前token对后续tokens生成的影响。这个累积收益一般是称为优势,用于衡量当前动作的好坏,也即模型本次回复的好坏,计算的方法一般使用GAE(广义优势估计,generalized advantage estimation))该模型同样需要训练。 -
Reward Model:正如上述章节[2.4 奖励模型]介绍,对Policy Model的输出整体进行打分,评估模型对于当前输出的即时收益。该模型训练过程不进行更新。 -
Reference Model:与 Policy Model是一样的模型,但在训练过程中不进行更新。其作用主要是与Policy Model计算KL散度(可以理解为两者的预测token概率分布差距)来作为约束,防止Policy Model在更新过程中出现过大偏差,即每一次参数更新不要与Reference Model相差过于大。
2.5.1 DPO(Direct Preference Optimization)
DPO是一种成本比较低的强化学习方法,它不需要显式的Reward Model,只需要Policy Model和Reference Model:
-
训练数据是与上述奖励模型一样的偏好对数据 -
Policy Model的目标是尽量拉开 chosen(preferred)样本与rejected(dispreferred)样本的token概率差距 -
但是,同时Policy Model的概率差距与Reference Model的概率差距不要太过于大,避免训练不稳定
具体的DPO loss公式如下:
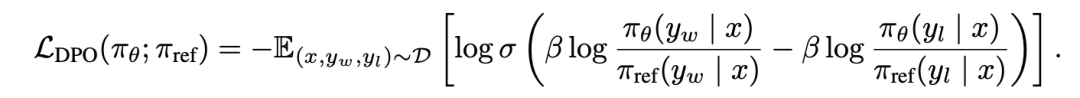
为什么说是不需要显式的Reward Model,因为Policy Model在DPO中,其实也是充当了Reward Model的角色,概率差可以认为是对应的应得奖励收益。
2.5.2 PPO(Proximal Policy Optimization)
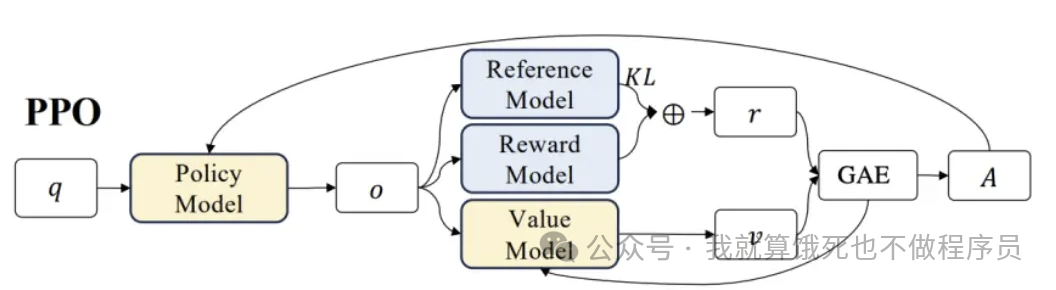
PPO(近端策略优化)比较复杂,尽量减少非必要的公式,用简单的描述来说明整个流程(以一个批次的数据训练为例):
-
在当前状态下,也即未更新前的Policy Model和Value Model,对一个样本的Prompt q,使用Policy Model(Actor Model)进行一次采样生成,也即一次“动作”; -
用Reward Model计算的分数,以及计算Reference Model与Policy Model的KL散度,这两个结合起来作为即时奖励; -
接着,用Value Model(Critic Model)来计算每一个token的收益,记为。 -
然后,如上述,计算本次采样生成的优势(累积收益),即每一个token的奖励计算不仅考虑当前token的分数,还有考虑对后续tokens分数的影响,再结合上第2步的即时奖励,便是本次动作(采样)的优势;
到这里,一次采样就得到本轮ppo训练的参考奖励和。下面会使用这些来进行k次迭代更新,即一次采样能够进行k次的模型更新,每一次模型的更新步骤如下:

到这里就介绍完整的PPO训练流程了,但可能对于第5-6步可能还会存在疑问,为什么要去提升和降低?
-
容易注意到,其实与KL散度计算很像,只是多了一层exp,因此可以用KL散度的视角去帮助理解,即预测tokens的概率分布差距; -
首先,是输入文本Prompt,然后用Policy Model去进行采样生成,得到预测的tokens序列,即概率最高的tokens,以及对应的logit,举个简单例子,Prompt为“你叫什么名字”,生成的tokens为“你好,我叫小红”,为了方便理解,用概率来表示: -
是用同样的Prompt,再去生成一次,那么也能得到对应预测tokens的logit,比如 -
那么当本次生成(“你好,我叫小红”)的质量比较好,即,那么当然应该鼓励Policy Model去学习,尽量拉高这些tokens的概率,便对应着提升;反之,同样的道理。
(这里的token不一定是这么分词的,只是为了举例子说明)
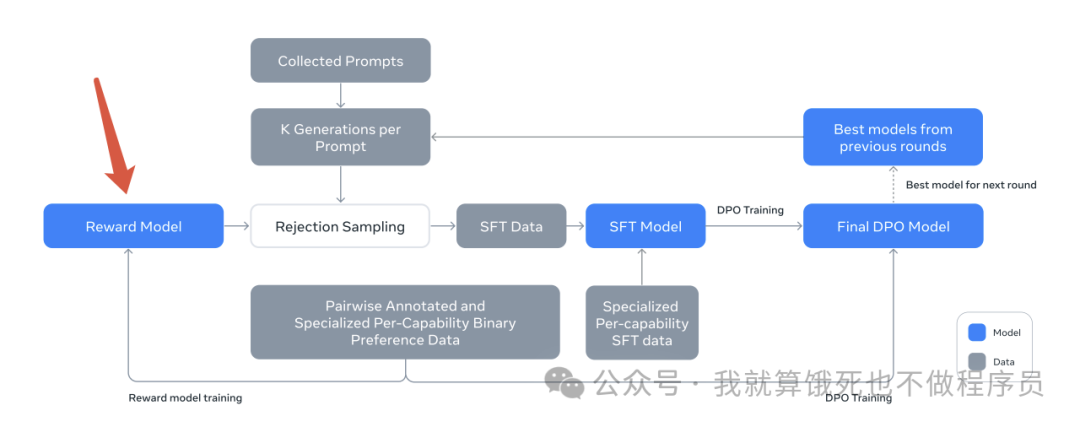
2.5.3 GRPO(Generalized Reinforcement Learning with Policy Optimization)
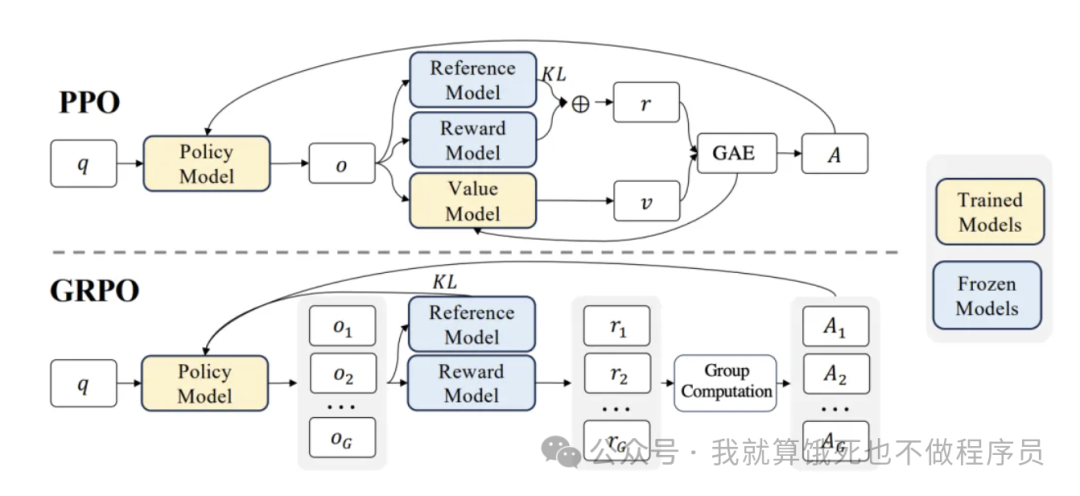
GRPO是DeepSeek-R1论文中提出的另外一种强化学习方法。从上图可以看出,相比PPO,GRPO去掉了Value Model,简化了训练流程,降低了显存消耗。简单描述下GRPO的流程:
-
对一个样本的Prompt q,使用Policy Model进行G次生成 -
同样地,Reference Model也进行G次生成,与Policy Model进行KL散度计算,KL散度可以理解为两者的预测token概率分布差距,跟其他方法都是类似作用,避免Policy Model训练不稳定 -
再使用Reward Model对Policy Model的这G次生成进行打分。参考DeepSeek-R1的做法,甚至可以不需要Reward Model,只需要奖励函数,比如代码问题,可以根据模型生成的代码是否能够运行,有标准答案的数学问题,从模型的生成中提取的答案是否正确,来给予一定的奖励分数 -
最后平均的KL散度和奖励分数作为Loss去更新Policy Model
3. R1微调实践
目前的开源模型基本都是至少经过预训练和SFT这两个步骤的,而且大多知名的开源模型也是完整地包含了强化学习的全链路,因此,我们去微调或者甚至想训练一个新的模型,并不需要从预训练开始,而是选择一个底座模型,然后使用自己的数据集去SFT,来让模型进一步认识私域的知识或者约束模型的输出格式,接着可以选择性地使用强化学习进一步提升模型的能力。
(使用的训练框架是:huggingface/trl)
3.1 微调流程
这个实验的目标是将一个0.5B的普通chat模型Qwen2.5-0.5B-Instruct微调成为一个具有像DeepSeek-R1的思维链能力,即模型会先输出自己的思考过程,然后再给出具体的答案,即下面这种格式:
<think>
思考过程...
</think>
<answer>
答案
</answer>
使用的数据集是一个代表性的小学数学题集gsm8k:

-
answer里包含了解题思路和答案,因此正好可以将解题思路来作为思维链。
具体的训练流程:
-
首先,使用SFT的方法进行训练,将Qwen2.5-0.5B-Instruct能够按照上述思维链的格式进行输出; -
接着,再使用GRPO的强化学习对上一步的SFT模型继续训练,保持思维链的同时,进一步来提升模型的回复准确性; -
其中,因为这个数据集的答案是非常标准唯一的数字答案,因此可以不需要Reward Model,直接根据模型的输出答案是否正确来给予一定的奖励分数
3.2 奖励函数
设计的奖励函数主要是两个目标:
-
检测模型的输出是否按照思维链的格式; -
模型的输出中答案是否准确
import re
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
"""检查LLM输出的答案是否完全正确"""
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
q = prompts[0][-1]['content']
print('-' * 20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}",
f"\nExtracted:\n{extracted_responses[0]}")
return [2.0if r == a else0.0for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
"""由于gsm8k数据集答案都是整型。检查LLM输出的答案是否为整型"""
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5if r.isdigit() else0.0for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""检查LLM输出是否完全按照思维链的格式"""
pattern = r"^<think>.*?</think>\s*<answer>.*?</answer>\n?$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r, re.DOTALL) for r in responses]
return [0.5if match else0.0for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""检查LLM输出是否存在符合思维链格式的部分"""
pattern = r"<think>.*?</think>.*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r, re.DOTALL) for r in responses]
return [0.5if match else0.0for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<think>\n") == 1:
count += 0.125
if text.count("\n</think>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1]) * 0.001# 不以</answer>结尾扣除部分奖励分数
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1) * 0.001# 不以</answer>结尾扣除部分奖励分数
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
"""思维链不完整也给予一定的奖励分数"""
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
3.3 SFT+GRPO训练
如上述提到,使用一半的数据集来进行SFT训练
trainer = SFTTrainer(
model=model,
processing_class=tokenizer,
args=training_args,
train_dataset=get_gsm8k_dataset(sft=True, cache_dir=args.cache_dir,
first_half=args.split_half=="first_half",
second_half=args.split_half=="second_half"),
)
trainer.train()
再接着用另外一半进行GRPO训练
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=reward_funcs,
args=training_args,
train_dataset=get_gsm8k_dataset(cache_dir=args.cache_dir,
first_half=args.split_half == "first_half",
second_half=args.split_half == "second_half"),
)
trainer.train()
3.4 推理
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=args.max_completion_length
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Assistant:\n{response}")
对数据集其中一道题,改下数字,看看下面模型的输出是否符合预期:
Natalia sold clips to 22 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Assistant:
<think>
In April, Natalia sold clips to 22 friends.
In May, she sold half as many clips as in April, which is 22/2 = <<22/2=11>>11 clips.
Altogether, Natalia sold 22+11 = <<22+11=33>>33 clips in April and May.
</think>
<answer>
33
</answer>
可以看到,模型的输出即包含了思维链,然后答案也是准确的。
3.5 总结
-
虽然微调第一步得到的SFT模型已经能够输出思维链,但是其回答问题的准确性还比较差,因为SFT训练的重点其实是整体的回复质量,而不是专注于正确答案; -
但如果不经过SFT训练,直接使用GRPO的话,一开始模型的输出是没有思维链的,又无法准确提取答案,导致没有任何奖励,变得难以训练,或者选择能力更强的底座模型; -
因此对于聊天类的数据,可以考虑直接使用SFT去微调,因为整体的回复质量更为重要,而对于数学/代码等要求正确答案/能否运行的数据,可以SFT+强化学习。
4. 完整代码
https://github.com/QunBB/DeepLearning/tree/main/llms/train/deepseek-train
(文:极市干货)