
GSM8K

港理工提出TokenSkip:让大模型在CoT中“跳”过冗余token,压缩40%,性能几乎不降!

MLNLP社区致力于促进国内外机器学习与自然语言处理领域的交流合作。近日,一篇关于LLM的论文提出TokenSkip方法,通过跳过不重要token来压缩思维链,提高推理速度和用户体验。
标点符号成大模型训练神器!KV缓存狂减一半,可处理400万Tokens长序列,来自华为港大等 开源

来自华为、港大、KAUST和马普所的研究者提出了一种新的稀疏注意力机制——SepLLM,它通过根据原生语义动态划分token数量来显著减少KV缓存使用量,并在免训练、预训练和后训练场景下实现了50%以上的KV缓存减少。
GSM8K-RLVR:用强化学习提升语言模型的数学解题能力
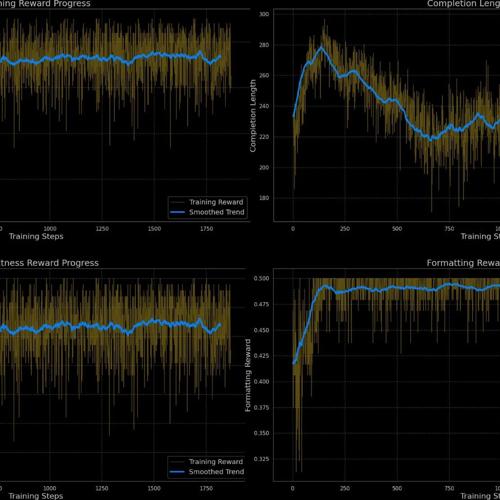
GSM8K-RLVR利用强化学习提升语言模型数学解题能力,Qwen2.5-Math-1.5B模型准确率从70.66%提升至77.33%,简化提示格式无需复杂标签。

Deepseek R1 Zero成功复现, 三阶段RL,Response长度涨幅超50%,涌现语言混杂,double-check

业研究人员。
社区的愿景
是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进
OmAgent v0.2.2 重磅更新!智能体算子来袭,智能体评测平台同步启用!

OmAgent v0.2.2 新版本发布,引入了Agent Operator简化复杂智能体功能的调用,并推出了Open Agent Leaderboard开源评测平台,支持多种主流算法和模型,统一评估框架确保公平性。
