
仅需1个数据,就能让大模型的数学推理性能大大增强?

最近研究发现仅使用一个数学训练数据就能大幅提升大型语言模型在数学推理任务上的表现,论文提出了1-shot RLVR方法,并展示了其在多个数学和非数学推理任务上的应用效果。
最近研究发现仅使用一个数学训练数据就能大幅提升大型语言模型在数学推理任务上的表现,论文提出了1-shot RLVR方法,并展示了其在多个数学和非数学推理任务上的应用效果。
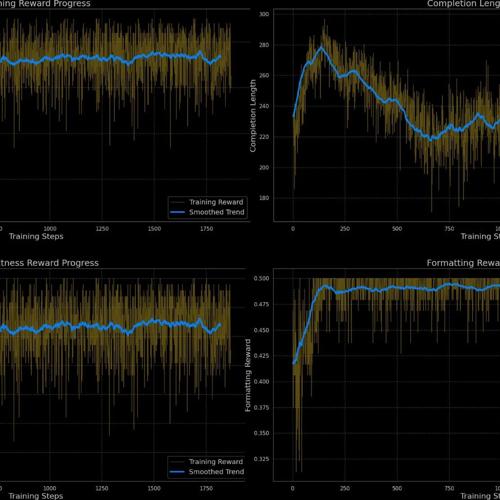
GSM8K-RLVR利用强化学习提升语言模型数学解题能力,Qwen2.5-Math-1.5B模型准确率从70.66%提升至77.33%,简化提示格式无需复杂标签。