


本文第一作者王宜平是华盛顿大学的博士生,其导师、通讯作者杜少雷为华盛顿大学Assistant Professor;另外两位通讯作者 Yelong Shen 和 Shuohang Wang 是 Microsoft GenAI 的Principal Researcher。
最近, 大型语言模型(LLM)在推理能力方面取得了显著进展,特别是在复杂数学任务上。推动上述进步的关键方法之一就是带可验证奖励的强化学习(Reinforcement Learning with Verifiable Reward,RLVR),其根据数学题最终答案的正确性提供 0-1 的结果奖励(outcome reward)。然而, 大量研究工作集中于改进原有的强化学习算法(如 PPO,GRPO),对于 RLVR 中所利用数据的研究仍相对不足。
近日,来自华盛顿大学西雅图分校、微软等机构的研究人员探索了一个重要的问题:RLVR 中究竟需要多少数据才能有较好的表现?
他们发现了一个神奇的现象:用一个数学数据就能够大幅提升模型在各种数学推理任务上的表现!

-
论文标题:Reinforcement Learning for Reasoning in Large Language Models with One Training Example
-
论文地址:https://arxiv.org/abs/2504.20571
-
代码地址:https://github.com/ypwang61/One-Shot-RLVR
-
W&B 实验记录:https://wandb.ai/yipingwanguw/verl_few_shot?nw=nwuseryipingwang22
-
X(Twitter):https://x.com/ypwang61/status/1917596101953348000
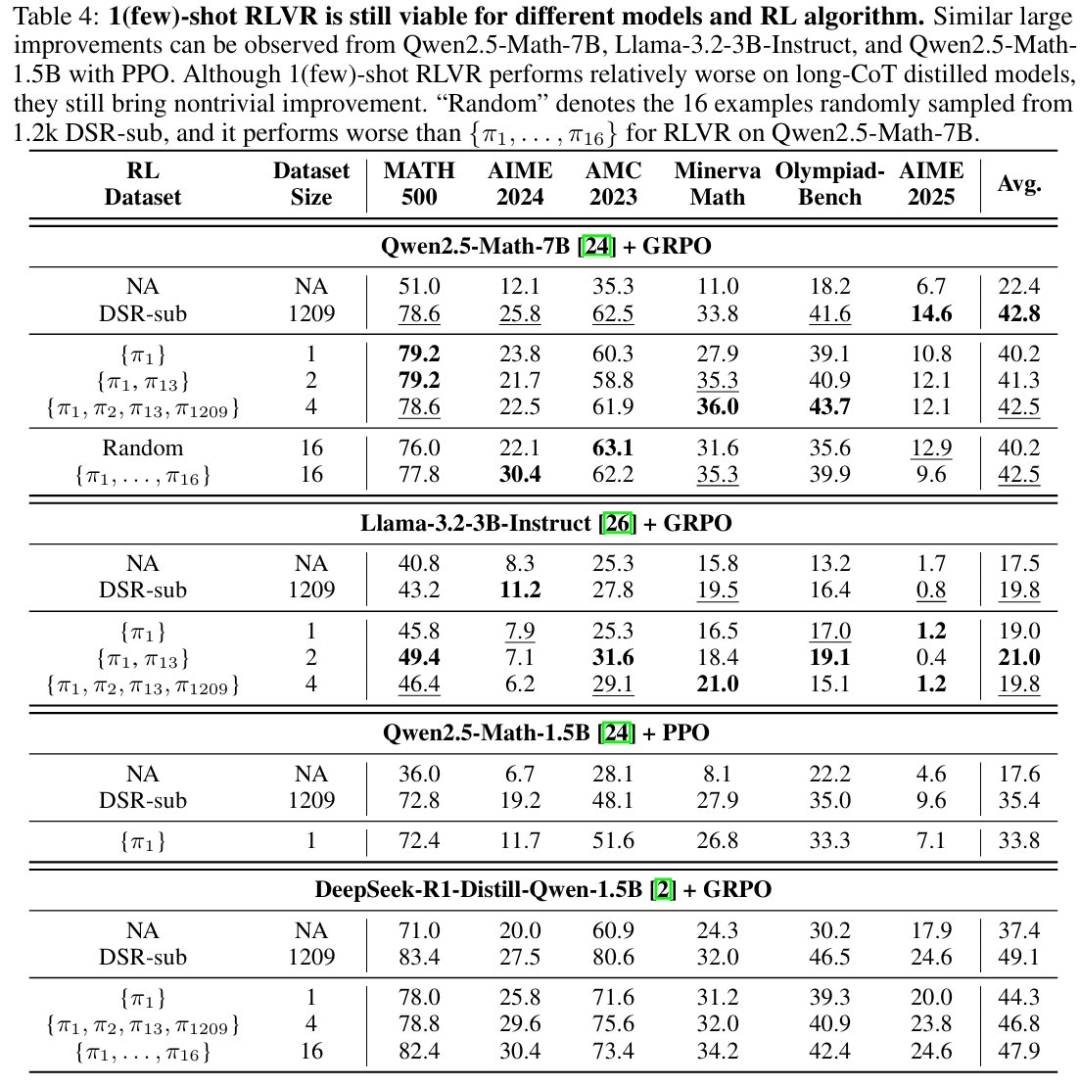
论文发现,只在 RLVR 训练中使用一个训练数据(称作 1-shot RLVR),就可以在 MATH500 上,将 Qwen2.5-Math-1.5B 的表现从 36.0% 提升到 73.6%,以及把 Qwen2.5-Math-7B 的表现从 51.0% 提升到 79.2% 。
这个表现和使用 1.2k 数据集(包括这一个数据)的 RLVR 效果差不多。使用两个训练样本的 RLVR 甚至略微超过了使用 1.2k 数据集(称作 DSR-sub)的表现,和使用 7.5k MATH 训练集的 RLVR 表现相当。这种表现可以在 6 个常用的数学推理任务上都可以观察到。
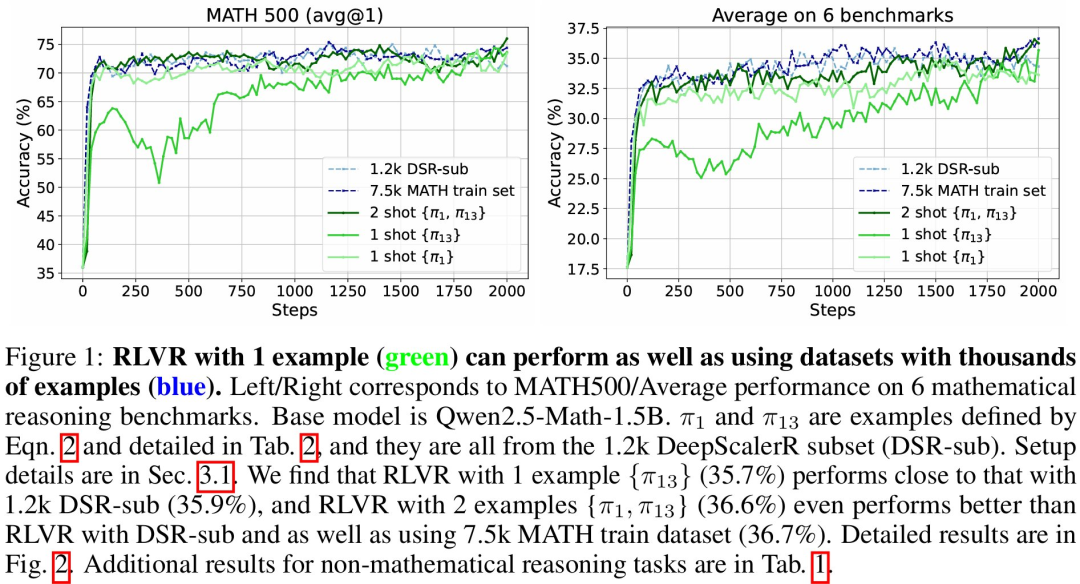
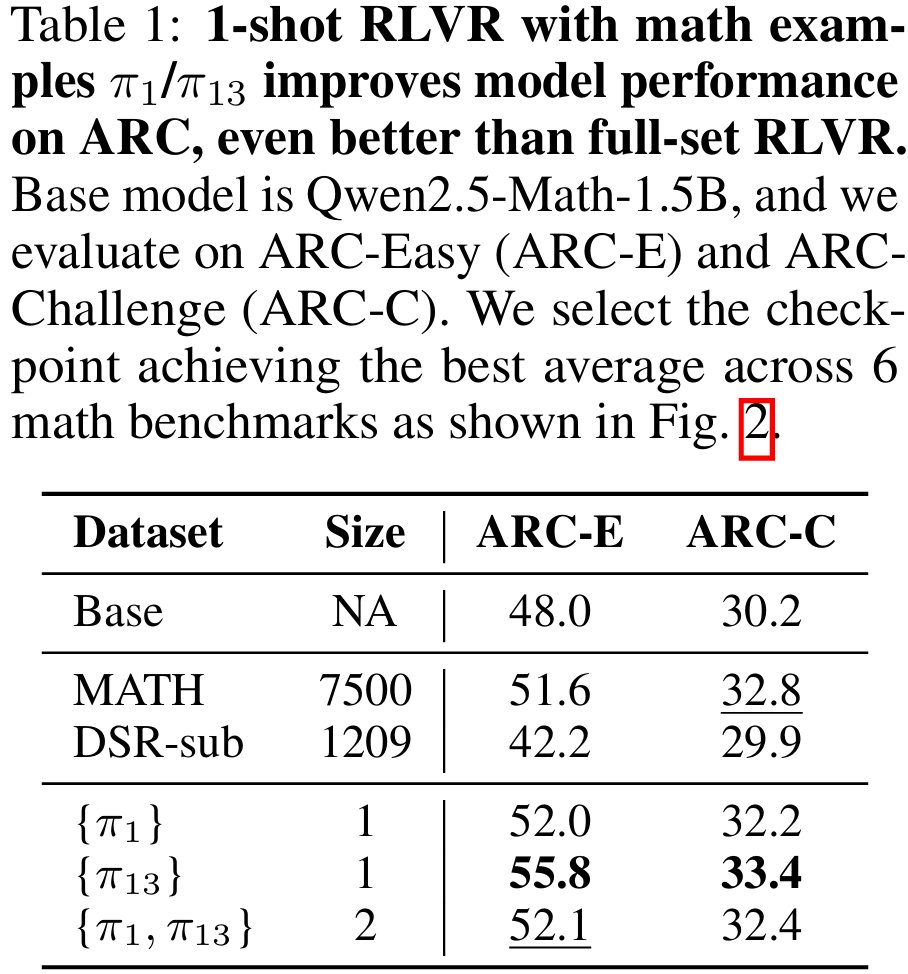
这种利用一个数学训练数据的 1-shot RLVR 激发的推理能力甚至可以拓展到非数学的推理任务上,如 ARC-Easy/Challenge。
背景介绍
在这项工作中,论文使用了包含 policy gradient loss ,KL divergence loss 以及 entropy loss 三项损失函数。这里 policy loss 使用 GRPO 格式的损失函数,对应是否解决数学题的 0-1 结果奖励;KL loss 用于保持模型在一般任务上的语言质量;而 entropy loss(系数为负)用于鼓励模型产生更加多样化的推理模式。
对于数据选择,研究者使用一个叫 historical variance score 的指标来将数据池(前面提到的 1.2k DSR-sub 数据集)中的数据来排序,为了优先选择在模型训练过程中准确度方差较大的那些数据。不过论文强调这种数据选择并不一定是最优的,只是为了更好的说明现象。而且 1-shot RLVR 对很多 historical variance score 不那么高的数据也能生效,可能是更通用的现象。
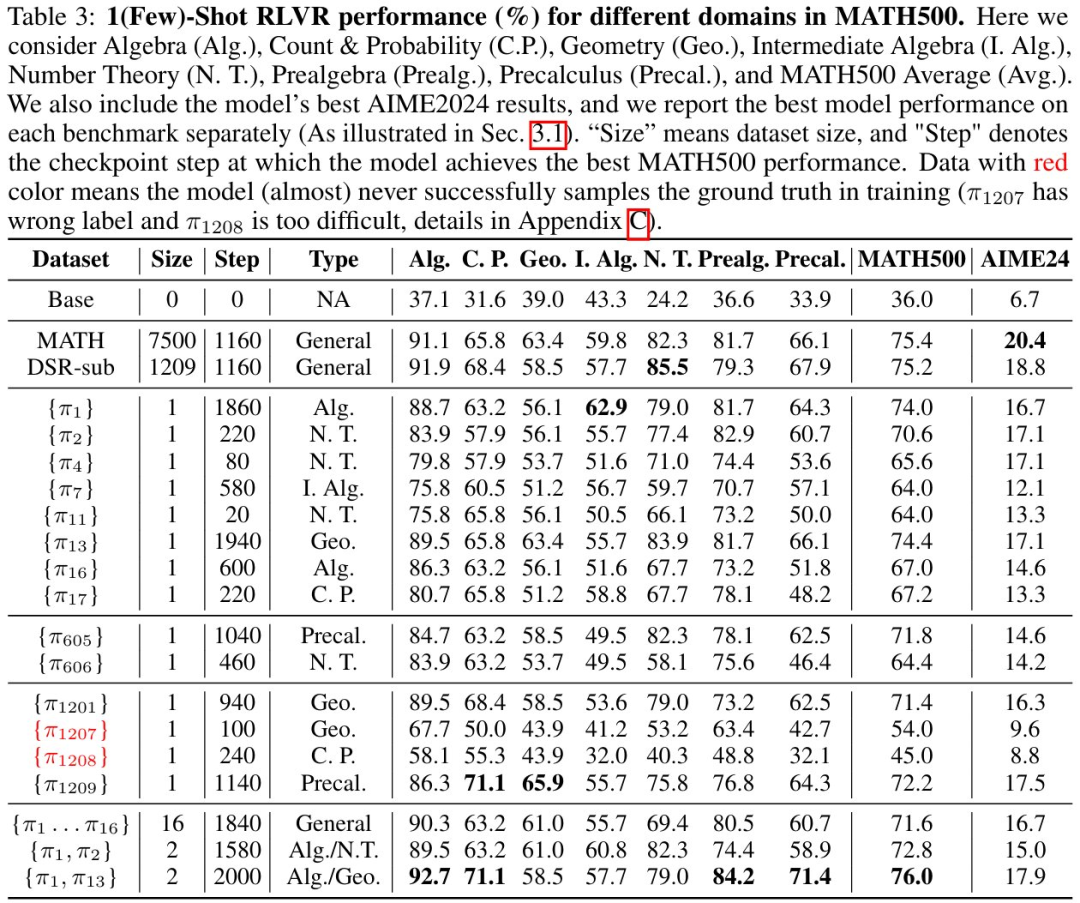
此外,研究者还发现让 1-shot RLVR 表现的很好的数据其实都不是特别困难。初始模型就已经有一定的概率可以解决。

实验观察
通过 1-shot RLVR,论文还发现了很多有趣的现象:
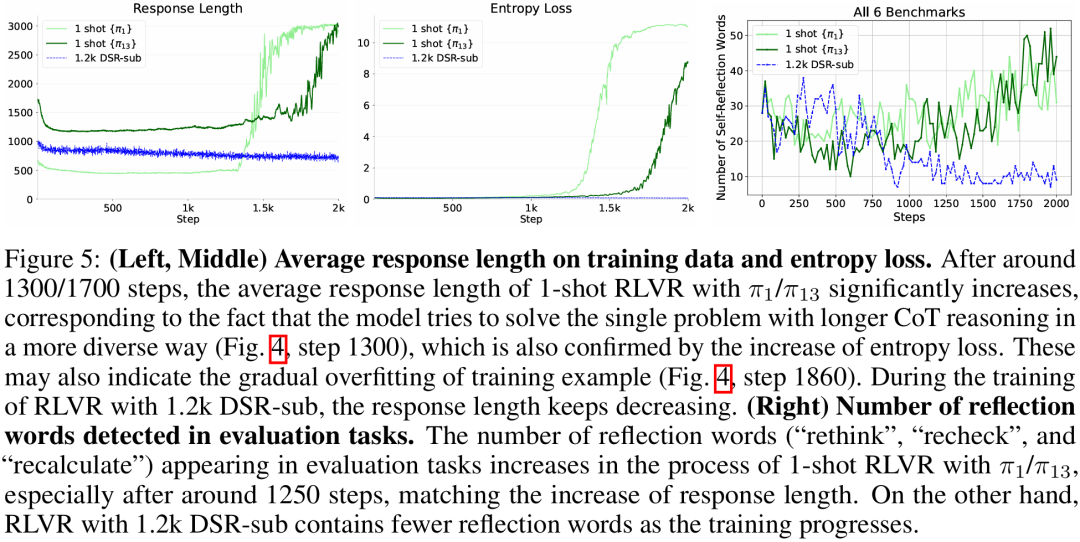
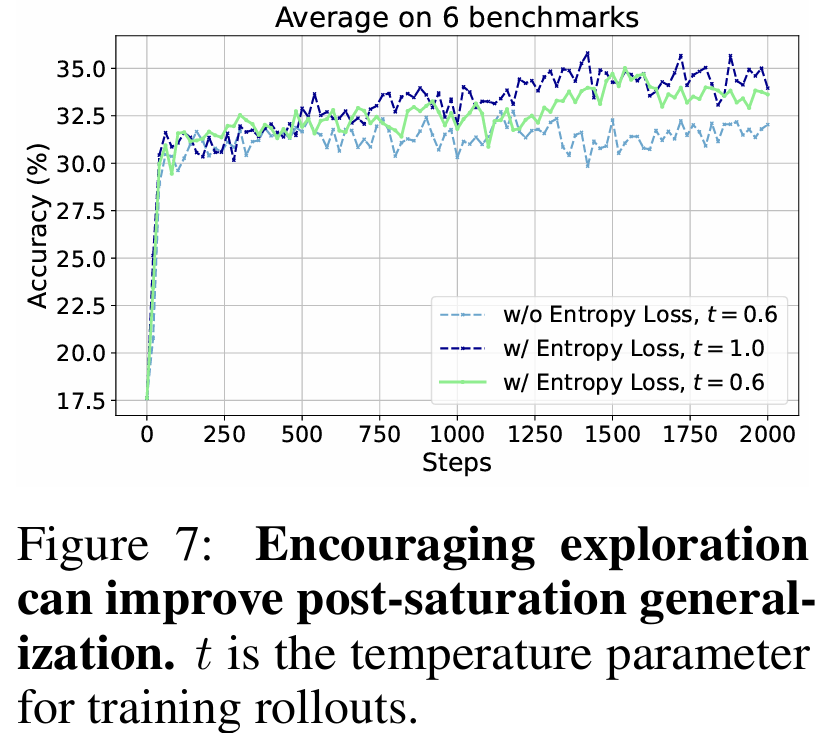
(1) 饱和后泛化:论文发现, 1-shot RLVR 中,单个训练样本的训练准确率快速达到接近 100%,但是下游任务的表现随着训练的进行还在不断地提升。(后文说明因为 entropy loss 鼓励多样性的探索,使得准确率略小于 100%,因此在训练过程中始终保持有 policy gradient)。

与此同时,在饱和后泛化的过程中,过拟合发生的比较晚,在单个样本 rollout 超过 1 百万次之后才出现明显乱码混合正确解答。而且此时下游任务的 reasoning 输出仍然正常而且表现良好。

(2) 1-shot RLVR 对很多数学样例都有效,而且可泛化性好。论文尝试了十多个样本,基本都可以在 MATH500 上取得接近或超过 30% 的提升。同时,来自一个数学主题(如几何)的单个训练数据可以同时提升其他数学主题(如代数,数论等)的表现。
(3) 更多的自我反思:1-shot RLVR 的训练过程也会出现之前 R1 之类的工作提到的回答长度(response length)的增加。而且更重要的是,论文观察到了模型在下游任务上的自我反思(self-reflection)相关词汇的频率的增加。
(4) 1-shot RLVR 可用在不同的模型和算法上。研究人员尝试了不同的模型 (Qwen2.5-Math-1.5B/7B, Llama-3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B),不同的 RL 算法 (GRPO, PPO),都可以观察到很大的提升。而且这里使用的数据是用 Qwen2.5-Math-1.5B 模型的 historical variance score 计算得到的,说明有些数据对不同的模型都适用。
消融实验和分析
论文进一步分析 1-shot RLVR 取得的改进的主要原因。通过移除其他的损失函数,论文发现 1-shot RLVR 对模型的改进主要来自于 policy gradient loss,而且和 KL divergence loss 以及 weight decay 关系不大。因此,即使饱和后泛化现象与 “grokking” 现象有相似之处(都出现了在过拟和之后仍能在下游任务泛化良好),因为 “grokking” 受到 regularization 方法(如 weight decay)的影响较大,两者仍有较大区别。

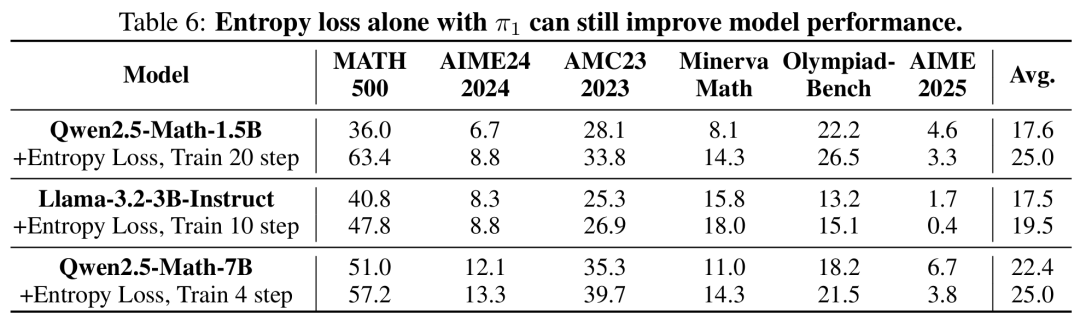
此外,论文也发现鼓励探索的重要性,如额外在 policy gradient loss 的基础上加合适大小的 entropy loss 能够进一步提升 1-shot RLVR 的表现,尤其是对饱和后泛化较为重要。作为一个额外的观察,论文发现只加 entropy loss 进行少量 step 的训练也能神奇的提升模型表现,并且这导致了在 1-shot RLVR 中如果数据的 lable 出现错误,也仍能部分提高模型的表现。论文作者们也仍在探究这一现象的原因。
总结和讨论
1-shot RLVR 在数学任务上的表现支持了之前很多论文的结论,即用于 RLVR 的基础模型本身往往就有较好的推理能力,而这篇论文进一步展示了这种能力可能可以用非常少的数据就激发出来。
论文相信这些现象可以促进人们进一步反思最近 RLVR 的进展,并思考 RLVR 的内部机制。并且它们对一些问题留下了一些启发,例如如何设计更好的 RLVR 数据选择算法,如何理解 1-shot RLVR 以及饱和后泛化现象,如何更好的鼓励探索,以及如何探索其他任务的少样本 RLVR 及其应用等等。
©
(文:机器之心)