港理工提出TokenSkip:让大模型在CoT中“跳”过冗余token,压缩40%,性能几乎不降!

MLNLP社区致力于促进国内外机器学习与自然语言处理领域的交流合作。近日,一篇关于LLM的论文提出TokenSkip方法,通过跳过不重要token来压缩思维链,提高推理速度和用户体验。
MLNLP社区致力于促进国内外机器学习与自然语言处理领域的交流合作。近日,一篇关于LLM的论文提出TokenSkip方法,通过跳过不重要token来压缩思维链,提高推理速度和用户体验。

上海AI Lab提出的新方法OREAL利用基于结果奖励的强化学习超越了DeepSeek,无需超大规模模型蒸馏。通过模仿正样本、偏好负样本并关注关键步骤,实现了数学推理任务上的显著提升,并开源训练数据和模型以促进研究对比。

上海AI Lab/清华哈工大/北邮团队的研究表明,通过改进Test-Time Scaling(TTS)方法,在数学推理任务上提升了小模型的性能。该研究发现最优的TTS方法高度依赖于具体的策略模型、过程奖励模型和问题难度。

AIGC开放社区分享OpenAI联合创始人Sam Altman罕见公开赞扬DeepSeek R1模型的事件及其影响,强调了中国开源大模型的实力。

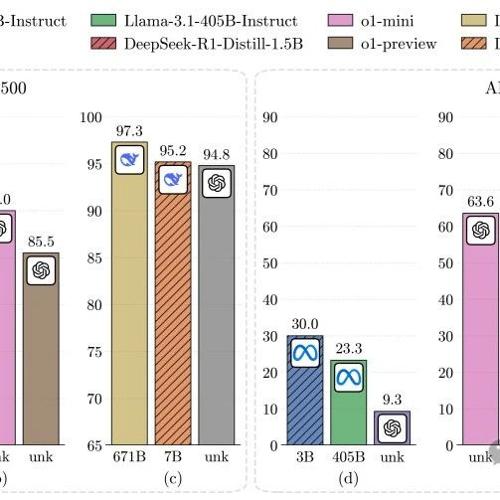
DeepSeek最新开源的R1模型在多项测试中表现优异,性能超越OpenAI o1模型。价格低廉(仅0.14美元/百万tokens输出),推理效率高,可与GPT-4竞争。

Mooncake是专为大规模语言模型服务的分散架构平台;QwQ致力于推进人工智能推理能力,并在各种基准测试中表现优异;Next.js AI Chatbot x Supabase提供高效的聊天功能与数据存储解决方案;Insight-V是一个早期探索长链视觉推理的多模态大语言模型;《AGI之路》深入探讨了大模型构建与应用的关键技术。