


近年来,推理大语言模型(RLLMs)通过内置的链式思考(CoT)能力,在复杂任务中展现出显著优势。然而,传统LLMs依赖外部CoT提示(如少样本示例)提升性能,但研究人员担心这种策略可能对RLLMs无效甚至有害。本文首次系统探究了零样本CoT(仅添加“逐步思考”指令)和少样本CoT对RLLMs的影响,并提出了关键问题:CoT提示是否仍是增强RLLMs推理能力的必要工具?

论文:Innate Reasoning is Not Enough:In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking
链接:https://arxiv.org/pdf/2503.19602
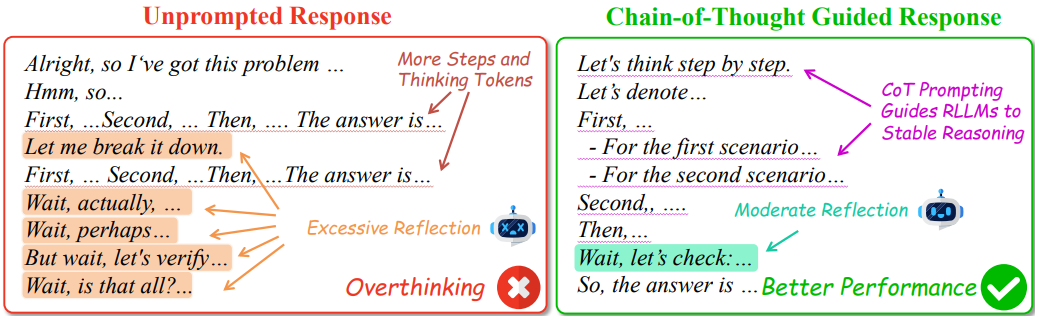
方法与实验
实验覆盖1.5B至32B参数的RLLMs(如DeepSeek-R1系列),并在6个数学推理数据集(GSM8K、MATH、AIME24等)上测试。通过对比直接提示、零样本CoT和少样本CoT,评估以下指标:
-
准确性:答案正确率 -
思考令牌数:模型输出中用于推理的token数量 -
推理步骤:逻辑分解的步骤数 -
反思频率:如“Wait”“Double-check”等自我修正语句的出现次数
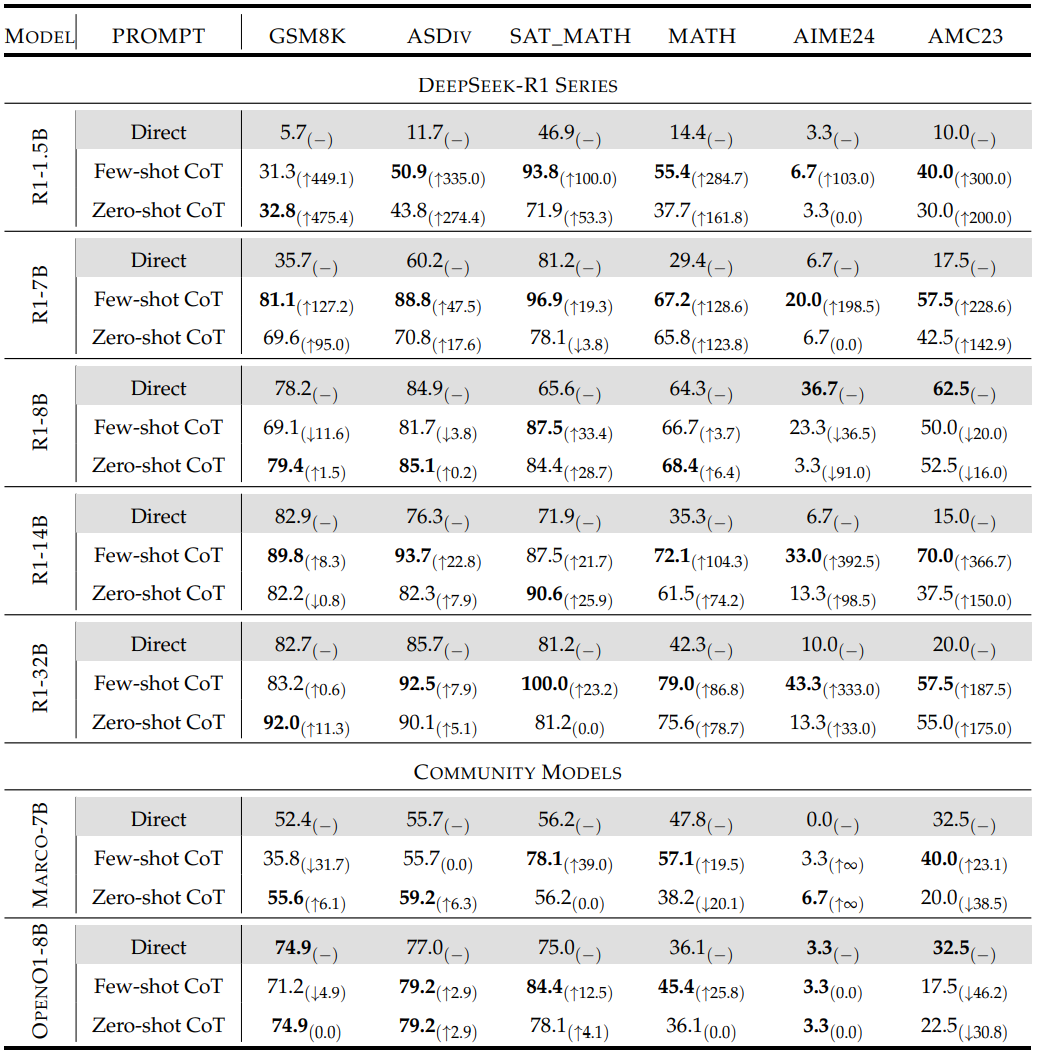
主要发现
-
性能提升的普遍性:72%的实验场景中,CoT提示显著提升RLLMs准确性,如R1-1.5B在GSM8K任务中零样本CoT提升475.4%。 -
模型容量与任务复杂度的交互效应: -
大模型(如32B)在复杂任务(如AIME24)上提升显著(最高333%),而在简单任务(如GSM8K)上增益微弱(0.6%)。 -
小模型(如1.5B)则相反,简单任务提升显著(475%),复杂任务增益有限。 -
单样本CoT的优越性:与LLMs不同,RLLMs在单示例提示下表现最佳(如R1-32B在AIME24上提升467%),多示例可能引入干扰。 -
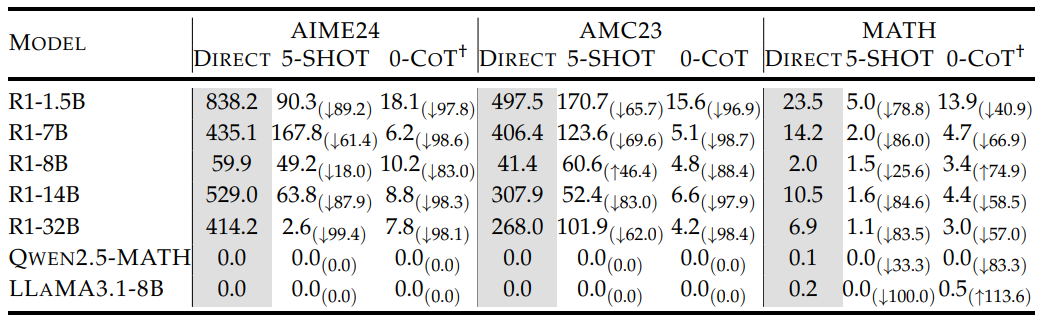
过度反思的抑制:CoT提示可将反思频率降低约90%(如R1-32B在AIME24上从414次/问题降至2.56次)。
深度分析
-
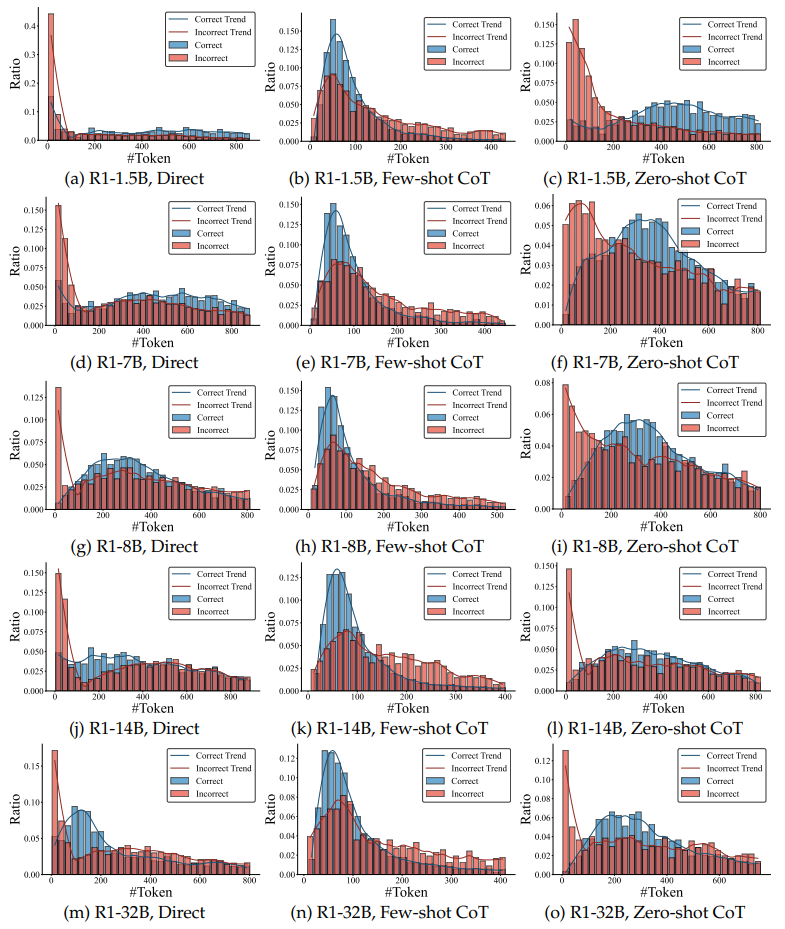
思考令牌分布:直接提示下令牌数分散,而CoT提示(尤其是少样本)使分布集中,减少冗余。
-
推理步骤与准确性的关系:复杂任务中,步骤数与准确性正相关,但简单任务存在“倒U型”关系(步骤过多导致性能下降)。
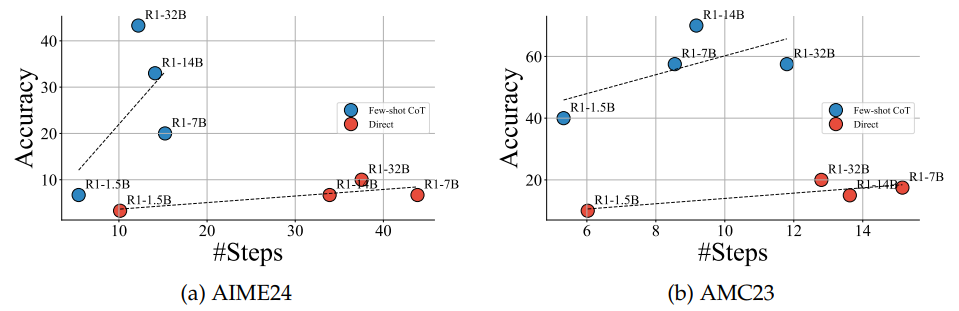
-
注意力机制揭示的过度反思根源:RLLMs对“Wait”“Double-check”等词的注意力权重显著高于基模型,表明其训练过程中过度拟合自修正机制。
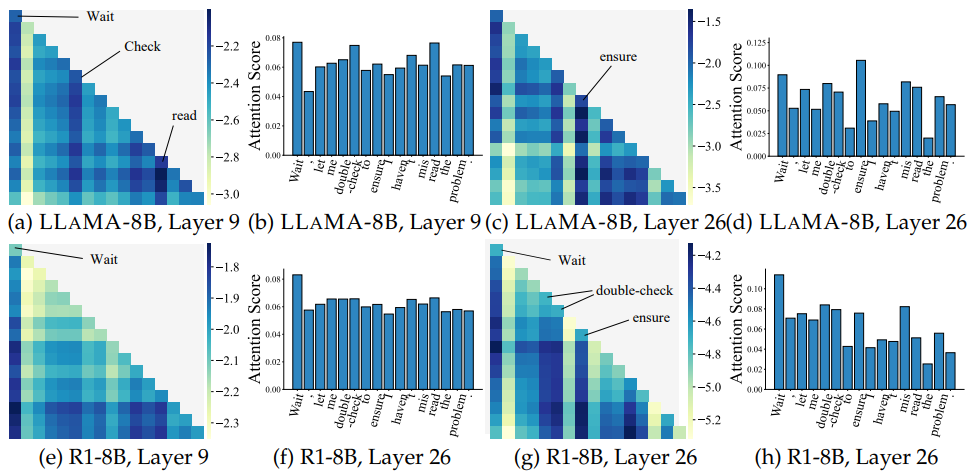
结论与意义
本文证实了CoT提示对RLLMs的必要性:
-
性能优化:通过单样本CoT实现高效推理。 -
行为调控:抑制过度反思,减少冗余计算。 -
工程启示:需根据模型容量和任务复杂度动态选择提示策略。
未来研究可探索更精细的提示设计,或结合强化学习进一步优化RLLMs的反思机制。
(文:机器学习算法与自然语言处理)