



大纲
-
背景:LLM学会“想太多”,人类开始头疼 -
效率危机:“长篇大论”问题出在哪? -
推理阶段优化:学会“点到为止” -
监督微调:思维做“瘦身手术” -
强化学习:“决策直觉” -
预训练革新:从底层重塑高效思维 -
未来展望:推理的终极形态会是什么? -
总结:高效推理是进化的必经之路
当LLM学会“想太多”,我们开始头疼
近年来,以DeepSeek-R1、OpenAI o1为代表的大型推理模型(LRMs)展现出惊人的复杂问题解决能力。它们像人类一样通过“思维链”(Chain-of-Thought)逐步推导答案,但这种能力却带来了新烦恼——AI太能“碎碎念”了!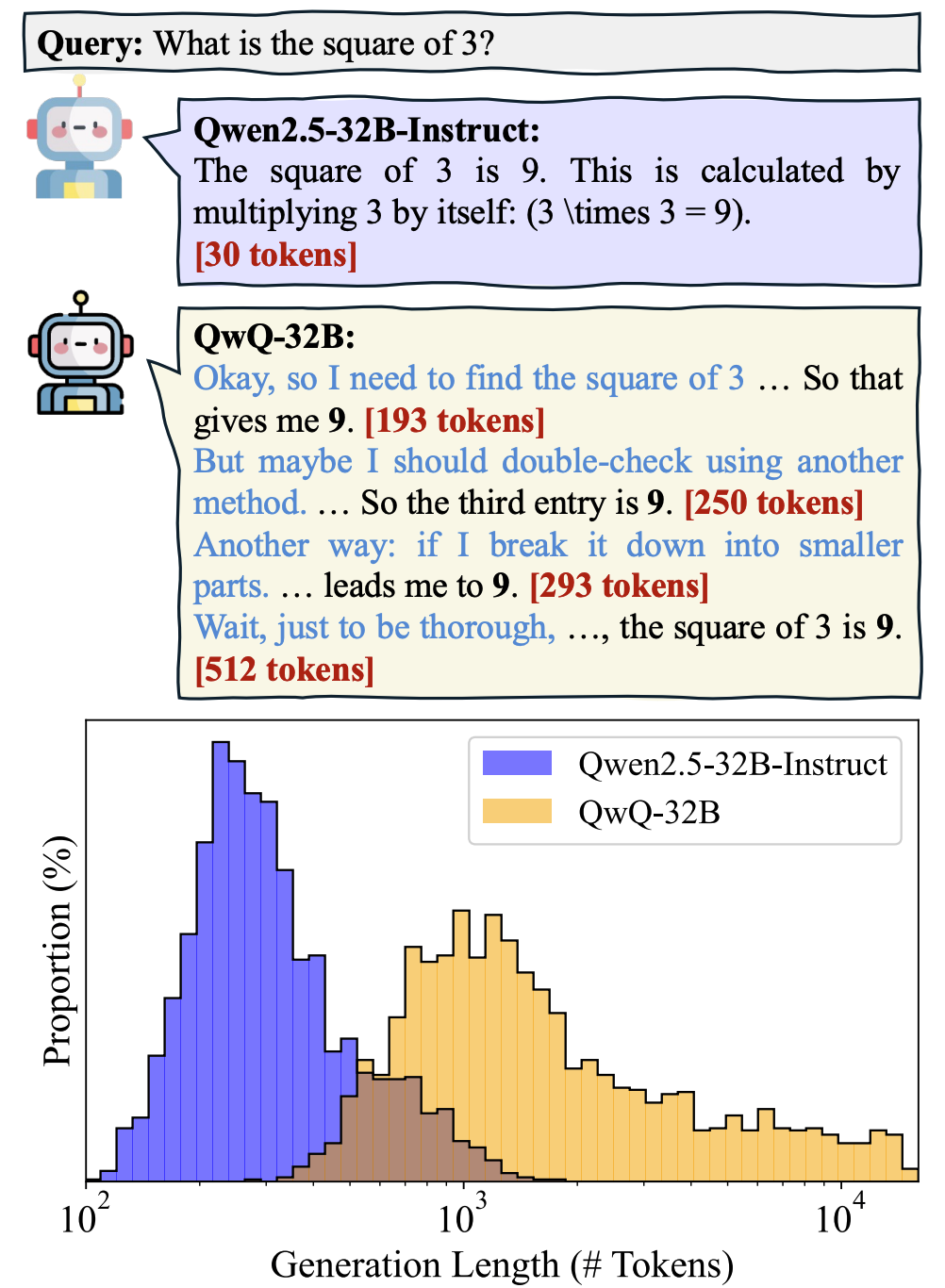 例如,面对一道小学数学题,传统指令模型只需30个词就能解答,而某LRM模型竟用了1248个词,相当于写一篇小作文。这种“过度思考”不仅浪费算力,在实时交互场景(如自动驾驶决策)中更可能引发灾难。本文揭秘如何给LLM的“话痨”属性对症下药。
例如,面对一道小学数学题,传统指令模型只需30个词就能解答,而某LRM模型竟用了1248个词,相当于写一篇小作文。这种“过度思考”不仅浪费算力,在实时交互场景(如自动驾驶决策)中更可能引发灾难。本文揭秘如何给LLM的“话痨”属性对症下药。
论文:A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
链接:https://arxiv.org/pdf/2503.21614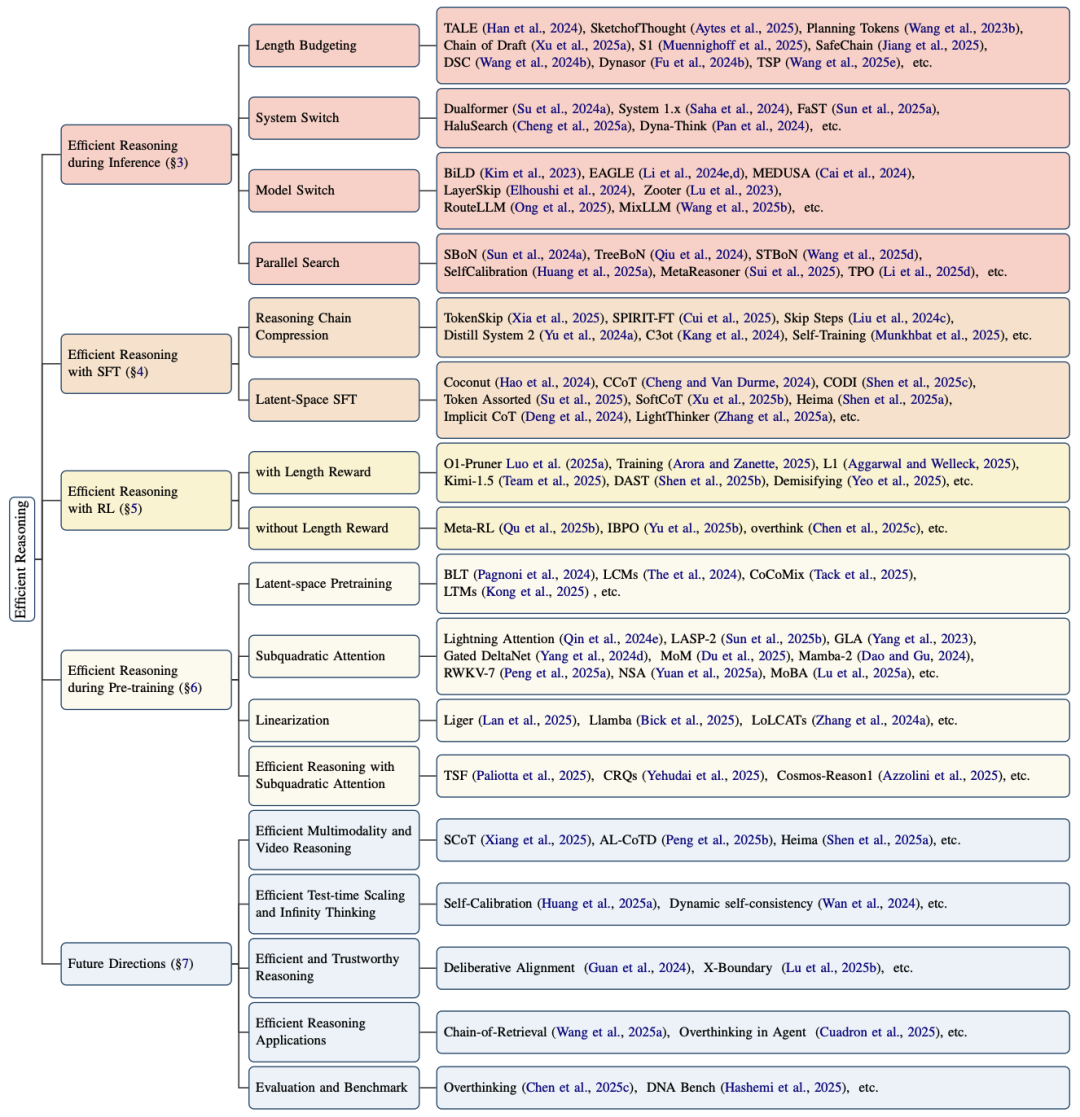
效率危机:“长篇大论”问题出在哪?
论文将推理效率定义为“单位计算成本获得的解题质量”,并总结三大低效模式:
-
冗余内容:反复解释题目,像学生凑作文字数 -
简单问题复杂化:2+3=?也要列十种解法验证 -
思维跳跃:遇到难题时浅尝辄止,在多个思路间反复横跳

更严峻的是,传统加速方法(如模型压缩)对这类“思维冗长”束手无策。就像给跑车换轻量化零件,却解决不了司机绕远路的问题。
推理阶段优化:让LLM学会“点到为止”
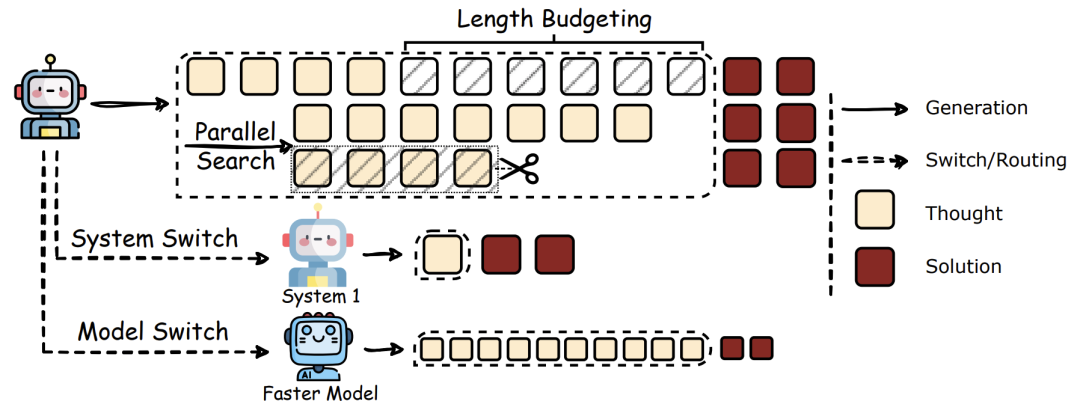
当前最直接的解决方案是在推理过程中动态调控:
-
字数预算:像考试作文要求“不少于800字”,给AI设定词数上限 -
双系统切换:模仿人脑“快思考”与“慢思考”,简单问题直觉反应,难题再启动深度推理 -
模型路由:小模型处理简单任务,大模型专攻硬骨头,像医院分诊系统 -
并行搜索:同时生成多个解题思路,及时淘汰低效路径
这些方法已在部分场景实现推理长度缩减40%,但强制截断可能导致关键步骤缺失,仍需更精细的控制策略。
监督微调:给思维做“瘦身手术”
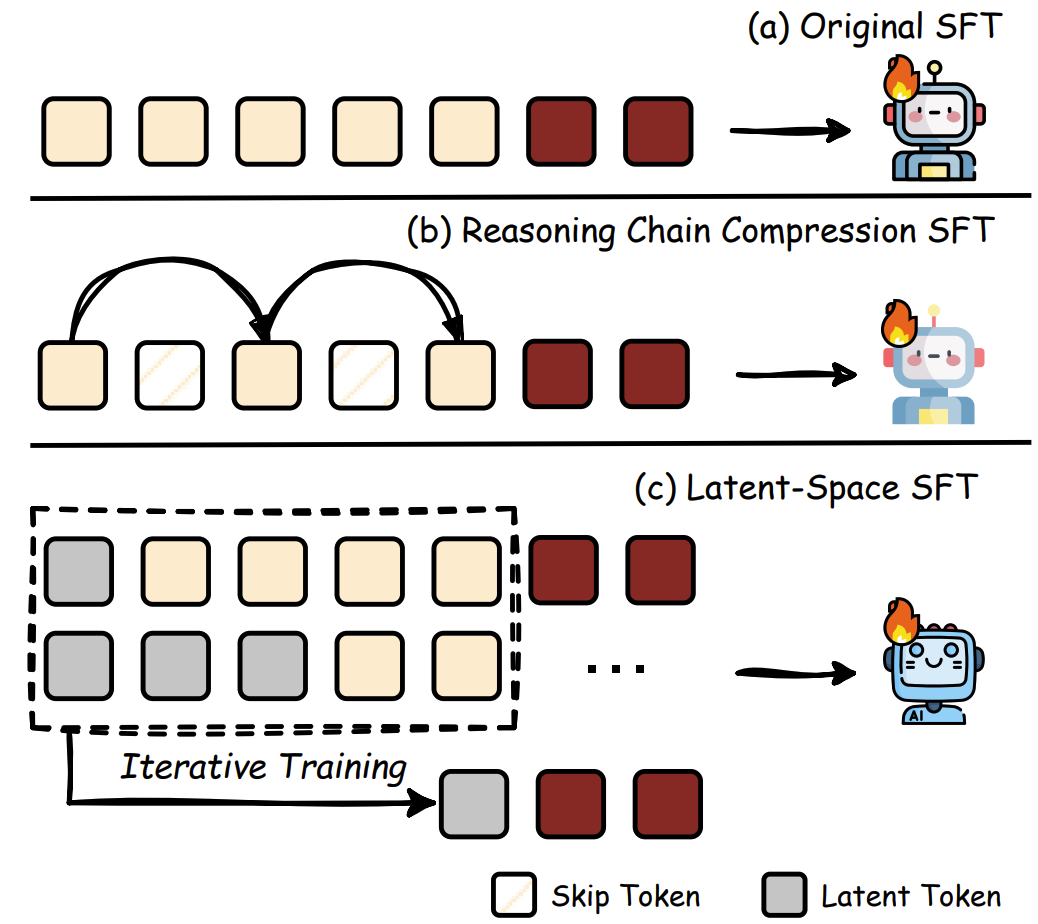
通过训练数据改造,“从源头学会简洁”:
-
推理链压缩:用GPT-4当老师,把啰嗦的思维过程精简成提纲 -
隐式推理:让AI用“脑内活动”替代文字推导,像人类心算时不写草稿
例如Coconut技术将传统思维链替换为隐藏层状态循环,推理速度提升17%。但这类方法可能让AI变成“黑箱”,难以追溯错误根源。
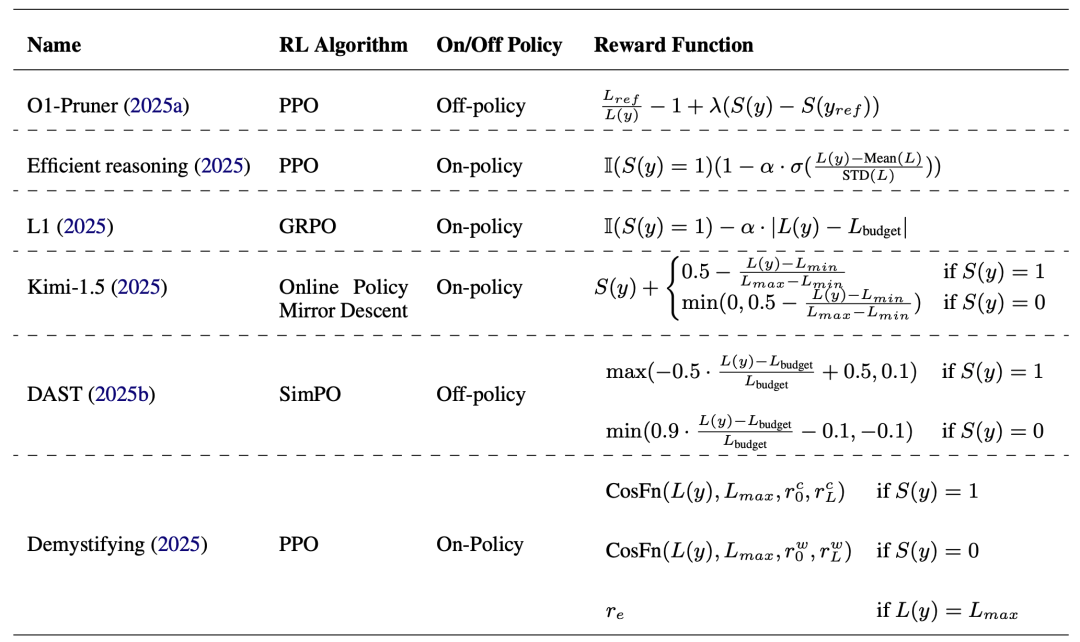
强化学习:训练“决策直觉”
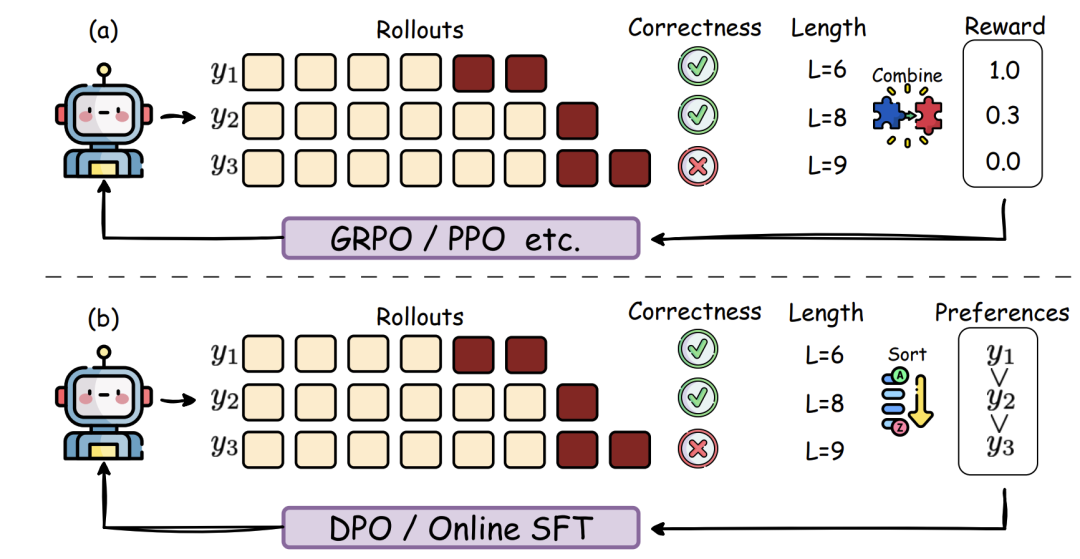
通过奖励机制塑造AI的“成本意识”:
-
词数惩罚:答案正确但用词过多?扣分! -
动态平衡:根据题目难度自动调整思考深度,像老司机根据路况切换驾驶模式
实验显示,引入强化学习后模型在数学题上的冗余推理减少58%,但过度优化可能导致AI在复杂问题上“躺平”,需要更智能的奖励设计。
预训练革新:从底层重塑高效思维
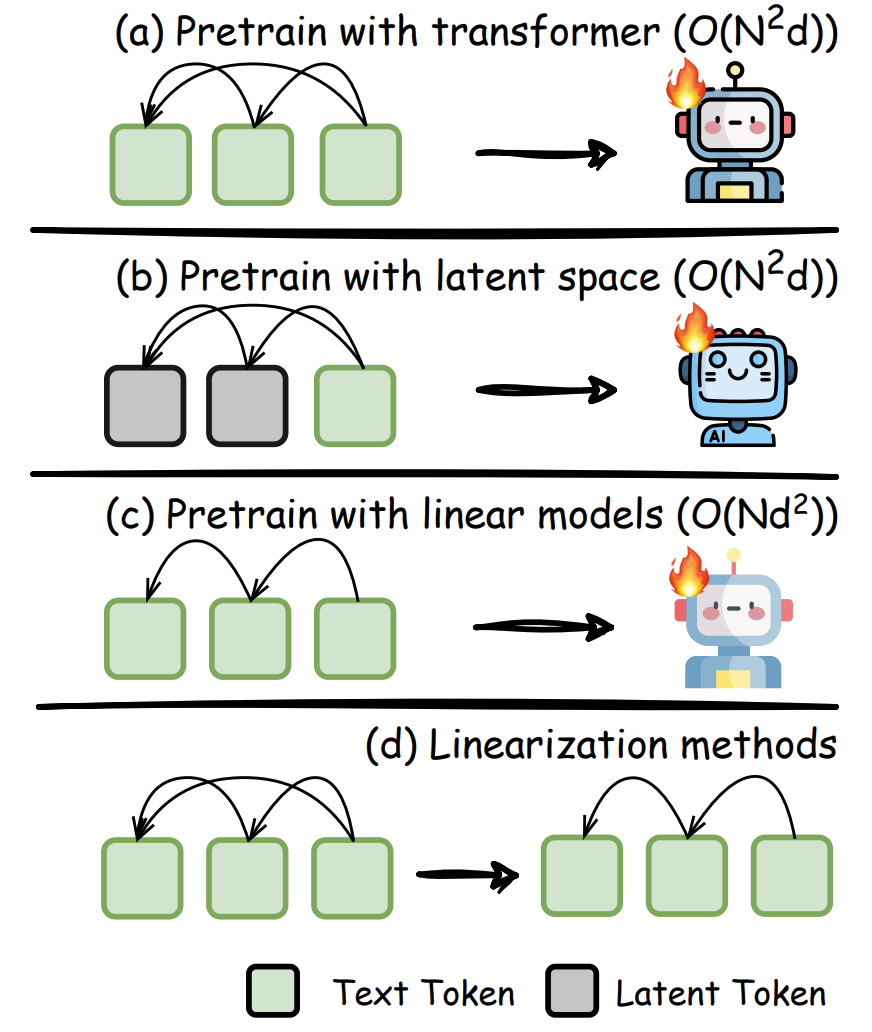
从模型架构动刀,突破Transformer的限制:
-
线性注意力:将计算复杂度从平方级降至线性级,处理长文本不再卡顿 -
稀疏注意力:只关注关键信息,像阅读时跳读无关段落 -
状态空间模型:用类RNN结构记忆关键信息,减少重复计算
这些变革让模型在保持精度的同时,推理速度提升3倍以上,但与传统架构的兼容性仍是挑战。
未来展望:推理的终极形态会是什么?
论文勾勒出四大前沿方向:
-
多模态高效推理:让AI看视频时不再逐帧分析,快速抓住关键帧 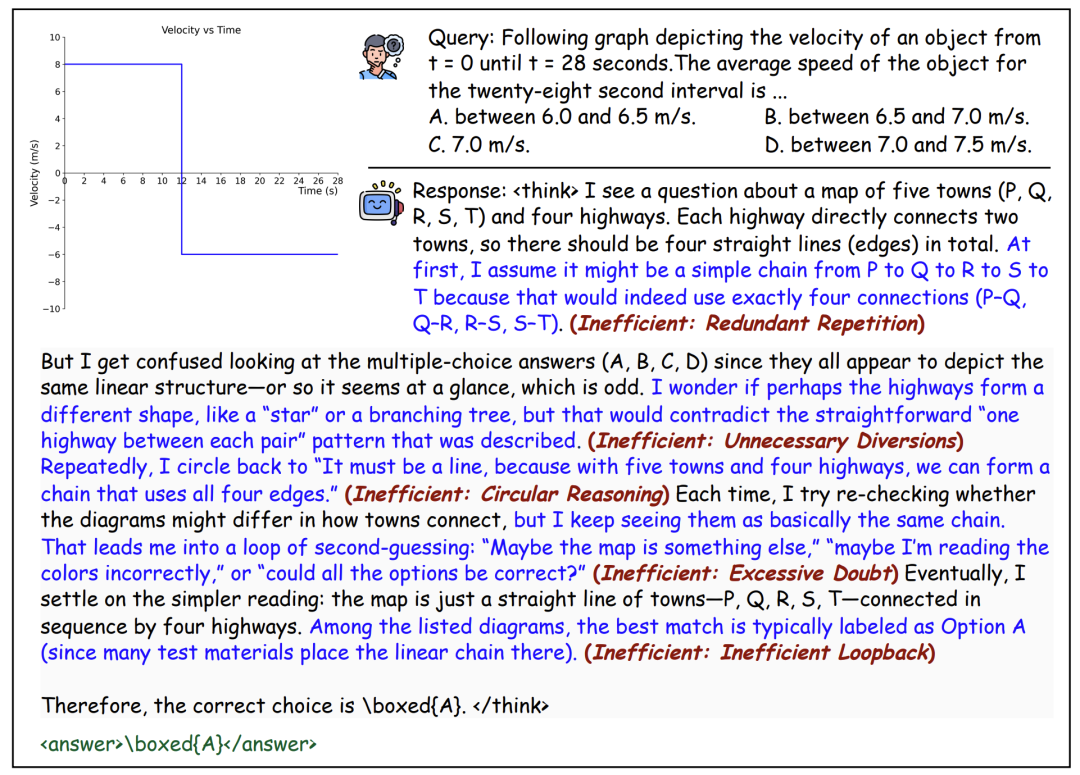
-
无限思考:像围棋AI一样边推理边总结,突破上下文长度限制 -
可信推理:既要简洁又要可靠,避免“为了简短胡说八道” -
应用革命:在医疗诊断、自动驾驶等领域实现实时精准决策
未来的AI可能像福尔摩斯般精准犀利,用最少步骤直击问题核心。
总结:高效推理是进化的必经之路
当AI学会“少即是多”,我们离真正的智能就更近一步。这项研究不仅关乎算力节省,更是打开通用人工智能的关键钥匙——毕竟,真正的智慧不在于能想多少,而在于如何想得巧。
(文:机器学习算法与自然语言处理)