


论文: Reverse Thinking Makes LLMs Stronger Reasoners 链接: https://arxiv.org/pdf/2411.19865v1
研究背景
-
研究问题:如何在大语言模型(LLMs)中引入反向思维,从而提高其推理能力。具体来说,反向思维可以帮助模型在正向和反向推理之间进行一致性检查,从而增强整体推理性能。 -
研究难点:如何有效地生成结构化的前向和后向推理数据,如何在训练过程中有效地利用这些数据来提高模型的推理能力,以及如何在保持测试时计算效率的同时实现这一目标。 -
相关工作:通过提示和聚合等方法改进LLMs的推理能力(如Chain-of-Thought和Self-Consistency),利用反向推理验证Chain-of-Thought并提高数学推理能力,以及知识蒸馏和数据增强等技术。
研究方法
-
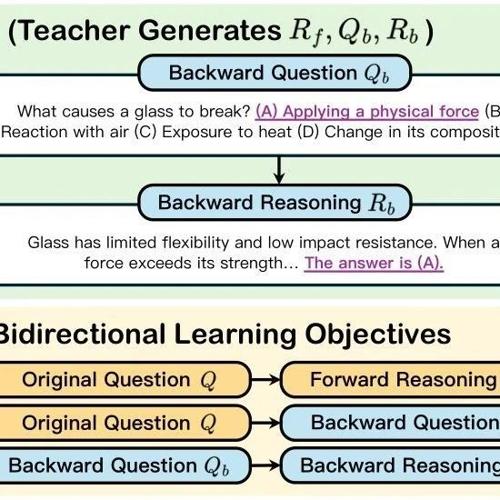
数据增强:首先,使用一个更大的教师模型生成结构化的前向和后向推理数据。具体步骤包括:
-
生成前向推理:通过提示教师模型生成从问题到答案的前向推理链。 -
生成后向问题:根据原始问题和正确答案生成后向问题。 -
生成后向推理:通过提示教师模型解决后向问题,生成后向推理链。 -
数据过滤:仅保留前向推理正确且前后向推理一致的数据点。 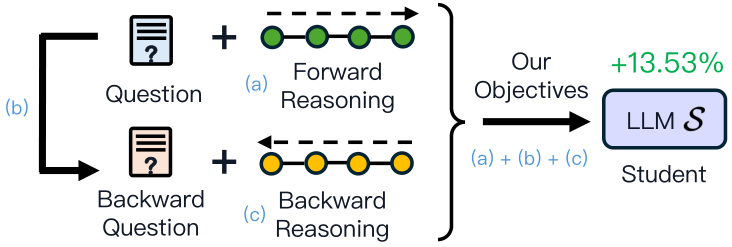
-
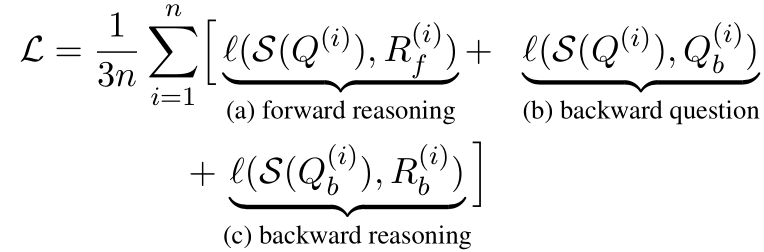
学习目标:其次,提出三个学习目标来训练较小的学生模型:
-
从问题生成前向推理。 -
从原始问题生成后向问题。 -
从后向问题生成后向推理。
实验设计
-
数据集:实验使用了12个多样化的数据集,涵盖常识推理、数学推理、逻辑推理和自然语言推理等领域。具体数据集包括StrategyQA、CSQA、ARC、MATH、GSM8K、TabMWP、ANLI、Date、BoolQ、OpenbookQA、e-SNLI和GSM8K-Rev。 -
模型:实验使用了两个模型:Mistral-7B-Instruct和Gemma-7B-Instruct。教师模型使用Gemini-1.5-Pro-001,学生模型分别使用LoRA微调和vllm进行训练。 -
训练配置:学生模型在数学推理任务上训练3个epoch,在其他领域训练10个epoch。Mistral-7B-Instruct的学习率为5e-6,Gemma-7B-Instruct的学习率为2e-4。
结果与分析
-
主要结果:REVTHINK在12个数据集上的平均表现为13.53%,相较于学生模型的零样本性能有显著提升,并且比广泛使用的符号知识蒸馏(SKD)方法提高了6.84%。与其他数据增强基线相比,REVTHINK在常识推理、表格数据推理和日期理解等领域表现出更大的性能提升。 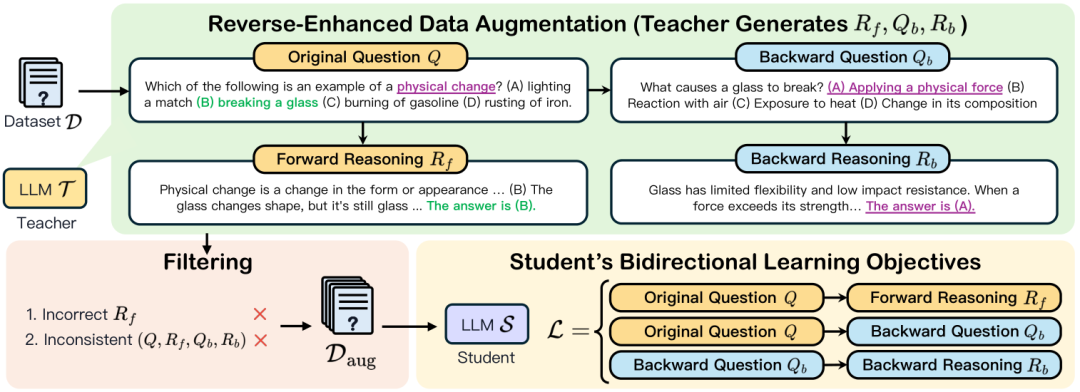
-
样本效率:在低资源情况下,使用10%的正确前向推理数据,REVTHINK的性能超过了使用完整训练集的SKD方法。 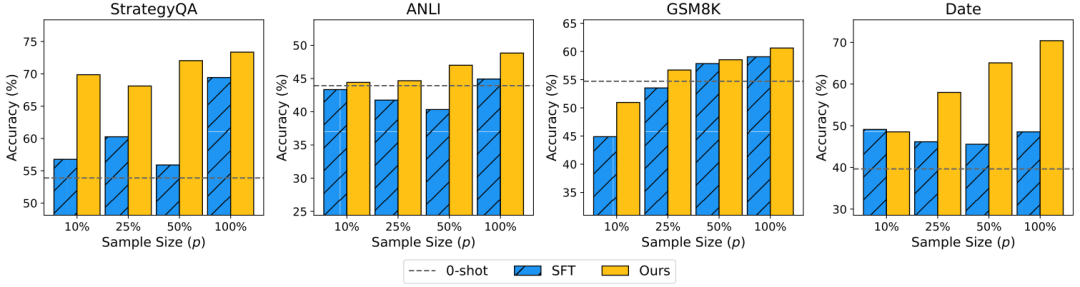
-
泛化能力:REVTHINK在未见过的数据集上表现出良好的泛化能力,特别是在领域外数学数据集上,REVTHINK显示出更大的增益。 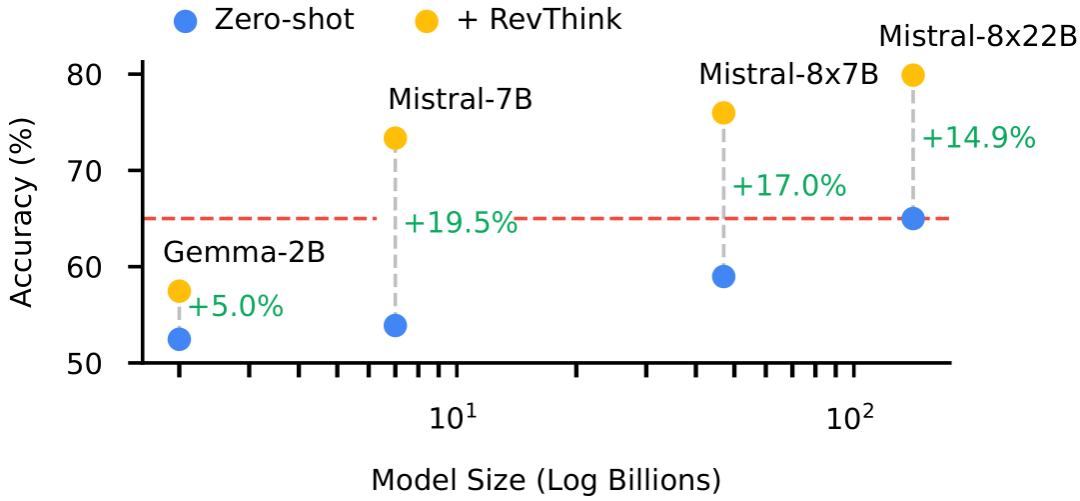
-
模型规模:REVTHINK随着学生模型规模的增加而扩展良好,Mistral-7B模型在使用REVTHINK方法时的表现优于参数更多的Mistral-8x22B模型。 -
互补性:REVTHINK与现有的数据增强方法(如Answer Augmentation)相结合,能够进一步提高性能。 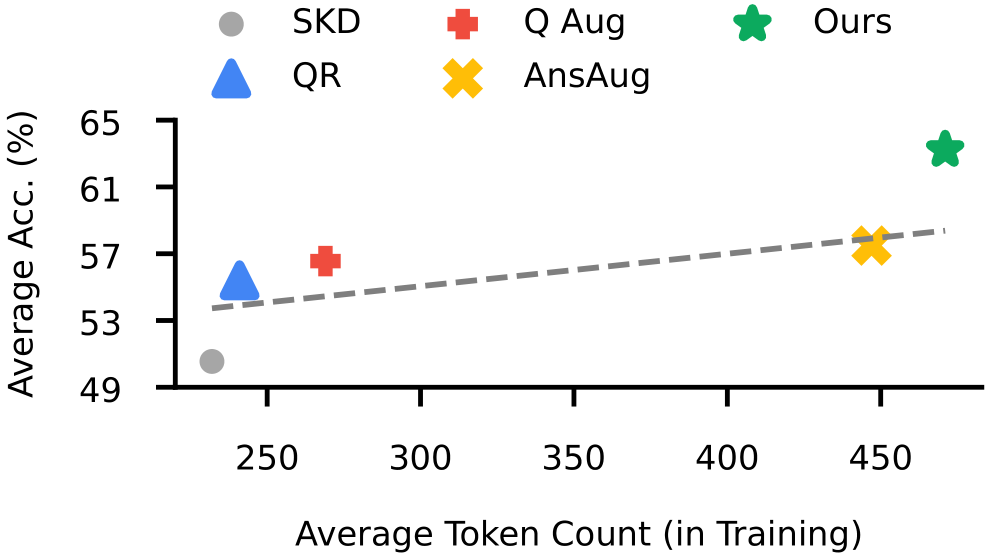
总体结论
(文:机器学习算法与自然语言处理)