
人会逆向思维,LLM也可以?DeepMind研究表明还能提升推理能力

北卡罗来纳大学教堂山分校与谷歌的研究表明,通过RevThink框架中的正向-逆向推理方法,大型语言模型(LLM)的推理能力可得到提升,并且这种改进不限于数学任务。
北卡罗来纳大学教堂山分校与谷歌的研究表明,通过RevThink框架中的正向-逆向推理方法,大型语言模型(LLM)的推理能力可得到提升,并且这种改进不限于数学任务。
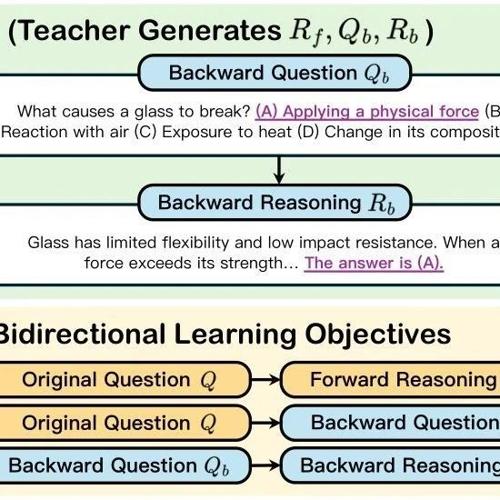
MLNLP社区介绍其愿景促进自然语言处理的学术与产业发展。介绍了REVTINH框架提高大模型推理能力的研究,通过数据增强和学习目标在多个数据集上显著提升表现。