



-
论文标题:Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
-
论文地址:https://arxiv.org/abs/2412.07775
-
代码地址:https://github.com/lzzcd001/nabla-gfn

利用 Nabla-GFlowNet 在 Aesthetic Score 奖励函数(一个美学指标)上高效微调 Stable Diffusion 模型。
扩散过程的流平衡视角
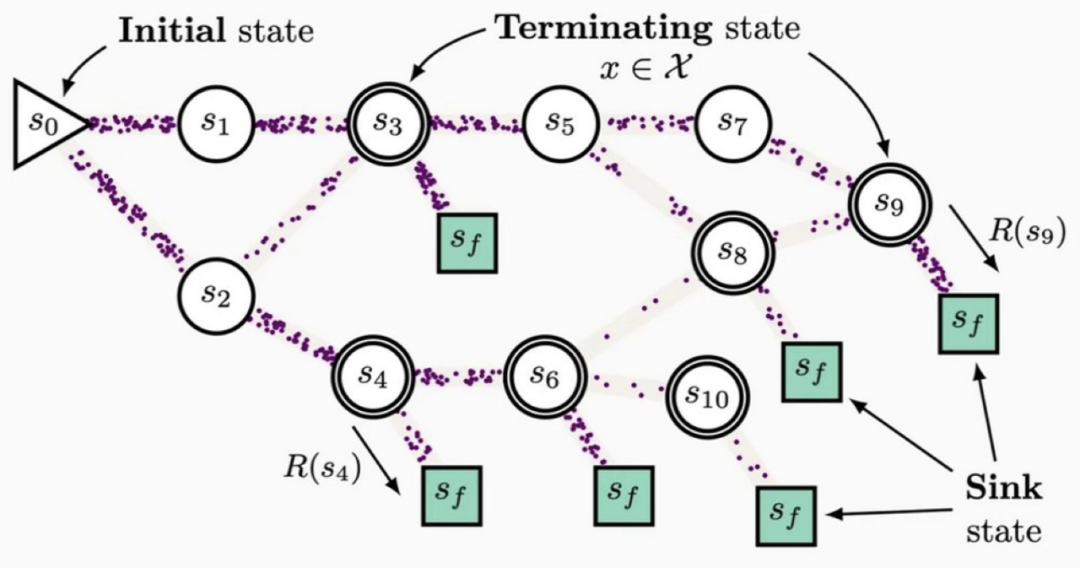
生成流网络 GFlowNet 示意图。初始节点中的「流」通过向下游的转移概率流经不同节点,最后汇聚到终端节点。每个终端节点所对应的流应匹配该终端节点对应的奖励。
在生成流网络(Generative Flow Network, GFlowNet)的框架下,扩散模型的生成过程可以视为一个「水流从源头流向终点」的动态系统:
-
从标准高斯分布采样的噪声图像 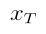 作为初始状态,其「流量」为
作为初始状态,其「流量」为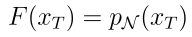 ;
;
-
去噪过程 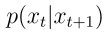 如同分配水流的管道网络,把每一个
如同分配水流的管道网络,把每一个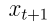 节点的水流分配给下游每一个
节点的水流分配给下游每一个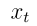 节点;
节点;
-
而加噪过程 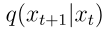 则可以回溯每一个的水流来自哪里;
则可以回溯每一个的水流来自哪里;
-
最终生成的图像 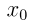 将累积总流量
将累积总流量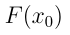 。
。

扩散模型示意图
流梯度平衡条件
在 GFlowNet 框架下,前后向水流需要满足一定的平衡条件。我们通过推导提出我们称为 Nabla-DB 的平衡条件:
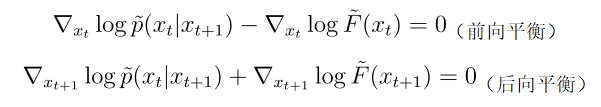
其中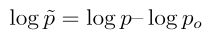 是残差去噪过程,
是残差去噪过程,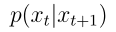 和
和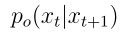 分别是微调模型和预训练模型的去噪过程。
分别是微调模型和预训练模型的去噪过程。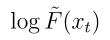 是这个残差过程对应的对数流函数。
是这个残差过程对应的对数流函数。
这个残差去噪过程应该满足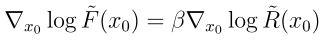 ,其中 β 控制微调模型在奖励函数和预训练模型之间的平衡。如果 β 为零,那么残差过程为零,也就是微调网络等于预训练网络。
,其中 β 控制微调模型在奖励函数和预训练模型之间的平衡。如果 β 为零,那么残差过程为零,也就是微调网络等于预训练网络。
稍作变换,就可以得到我们提出的 Nabla-GFlowNet 对应的损失函数 Residual Nabla-DB(其中 sg 为 stop-gradient 操作):
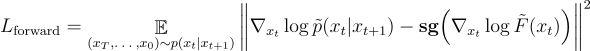
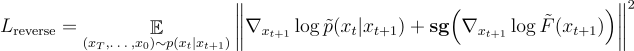
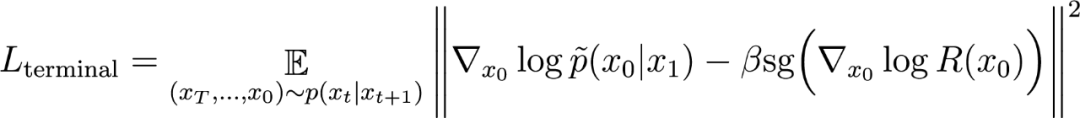
对数流梯度参数化设计
上述损失函数需要用一个额外的网络估计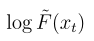 ,但我们观察到:如果我们对
,但我们观察到:如果我们对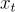 做单步预测得到不准确的去噪结果
做单步预测得到不准确的去噪结果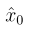 ,那么
,那么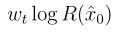 是一个很好的估计,其中
是一个很好的估计,其中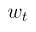 是一个权重常数。因此,我们提出如下参数化:
是一个权重常数。因此,我们提出如下参数化:
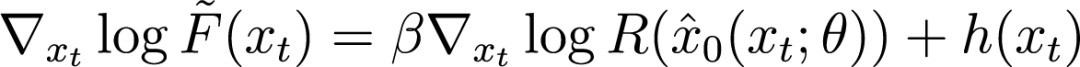
其中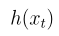 是用 U-Net 参数化的残差梯度,而单步去噪估计为
是用 U-Net 参数化的残差梯度,而单步去噪估计为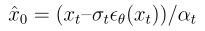 (
(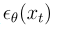 是扩散模型ε-预测参数化的网络)。
是扩散模型ε-预测参数化的网络)。
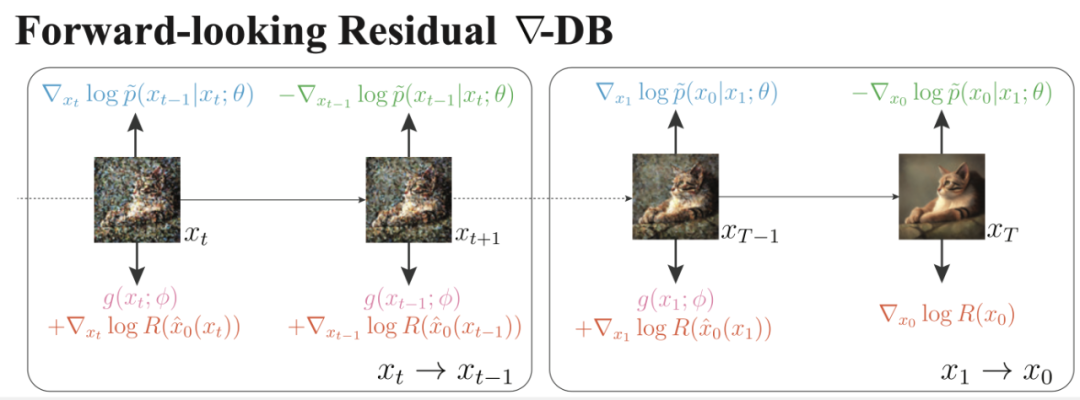
方法示意图。每条采样路径的每个转移对 中每张图的上下两个「力」需要相互平衡。
中每张图的上下两个「力」需要相互平衡。
直观解释
如果我们只计算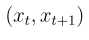 这一转移对的前向匹配损失对扩散模型参数的梯度,我们有:
这一转移对的前向匹配损失对扩散模型参数的梯度,我们有:
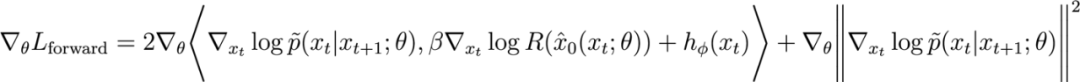
其中第一项是基于内积的匹配度函数(残差扩散模型与奖励梯度估计之间的匹配),第二项是让微调模型趋近于预训练模型的正则化。
伪代码实现

实验结果
我们分别用以下奖励函数微调 Stable Diffusion 网络:
-
Aesthetic Score,一个在 Laion Aesthetic 数据集上训练的美学评估奖励函数; -
HPSv2 和 ImageReward,衡量指令跟随能力的奖励函数。
定性实验结果表明,通过 Nabla-GFlowNet 微调,我们可以快速得到奖励更高但避免过拟合的生成图像。
ReFL 和 DRaFT 等直接奖励优化的方法虽然收敛速度快,但很快会陷入过拟合;而 DDPO 这一基于传统策略梯度的强化学习微调方法由于没有理由梯度信息,微调速度显著劣于其他方法。
同时,我们的定量实验表明,我们的 Nabla-GFlowNet 可以更好保持生成样本的多样性。

Aesthetic Score 奖励函数上的微调结果(微调 200 步,取图片质量不坍塌的最好模型)。Nabla-GFlowNet(对应 Residual Nabla-DB 损失函数)方法微调的网络可以生成平均奖励更高且不失自然的生成图片。

相较于 ReFL,DRaFT 等直接奖励优化的方法,Nabla-GFlowNet 更难陷入过拟合。
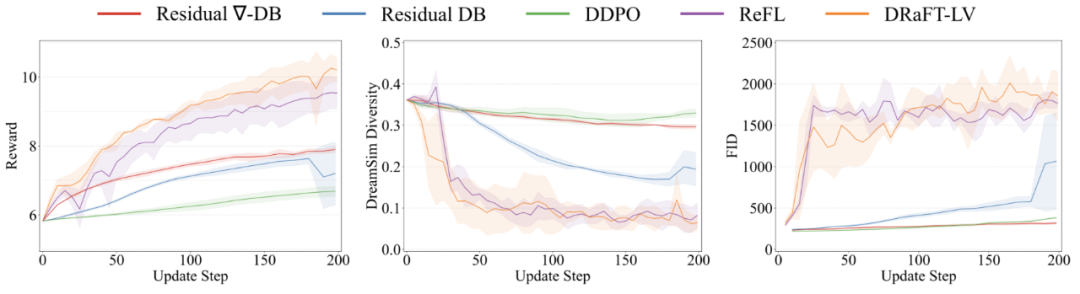
Aesthetic Score 奖励函数上的定量结果 Nabla-GFlowNet 在奖励收敛快的同时,保持更高的 DreamSim 多样性指标(越高代表多样性越好)和更低的 FID 分数(越低代表越符合预训练模型的先验)。

HPSv2 奖励函数上的微调结果

ImageReward 奖励函数上的微调结果
结语
我们利用生成流网络(GFlowNet)的框架,严谨地得到一个可以更好保持多样性和先验的高效的扩散模型奖励微调方法,并且在 Stable Diffusion 这一常用的文生图扩散模型上显示出相较于其他方法的优势。
©
(文:机器之心)