


100天前,DeepSeek团队发布了「推理大模型」DeepSeek-R1。这个模型不仅能回答问题,还能像人类一样一步步「写草稿」「验算」「纠错」,比如解数学题时先列公式再计算,写代码时边写边检查。这种「显式推理」能力让它迅速成为AI圈的焦点。
论文:100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
链接:https://arxiv.org/pdf/2505.00551
但DeepSeek-R1的技术细节并未完全开源,于是全球研究团队开启了「复现竞赛」——用公开数据和算法,尝试复刻它的能力。这篇论文就像一份「复现攻略」,总结了100天来的经验,还画出了未来的技术地图。
推理大模型的本质是「让AI学会思考」,而不仅是「背诵答案」。
概念:推理大模型 VS 普通大模型
普通大模型(比如ChatGPT)像「速记员」:你问它问题,它直接输出答案,但中间过程是「黑箱」。而推理大模型更像「学霸」:解题时会展示完整的思考步骤,比如:
-
自我验证:算完结果后反向检查 -
多步推导:拆解复杂问题为小步骤 -
反思纠错:发现错误后重新尝试
这种能力对数学、编程、逻辑题尤其重要。比如解方程时,模型可能会先写「设未知数为x」,再列出方程,最后验算答案是否正确。
复现研究的两大方法
一:监督微调(SFT)
监督微调的核心是让模型学习高质量「解题范例」。比如:
-
数据从哪来:从数学竞赛题、代码题中筛选,再用DeepSeek-R1生成「标准答案」 -
关键操作:去重、过滤错误、难度分级(参考下表的数据集统计) 
-
效果对比:某些团队用仅1千条精选数据,就能达到不错效果 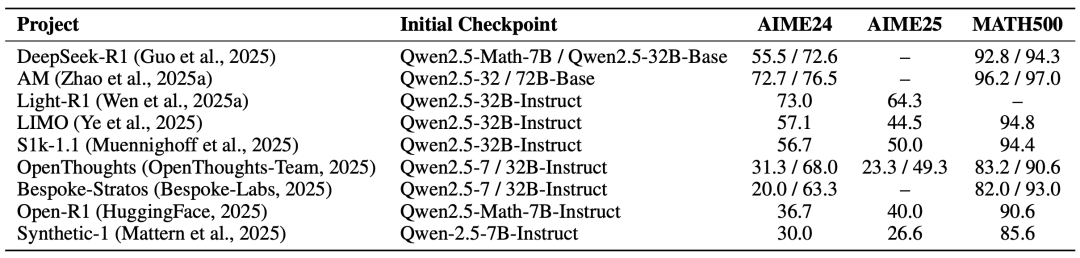
冷知识:数据质量比数量更重要!某些团队发现,加入「非推理类数据」(比如写作、角色扮演)能提升模型通用性。
二:强化学习(RLVR)
如果说SFT是「背答案」,RLVR就是「模拟考试」:模型生成多个答案,根据得分(奖励)调整策略。关键设计包括:
-
奖励规则:答案正确性、格式规范性(比如代码是否可执行) -
算法优化:PPO、GRPO等算法改进(公式见下文) -
动态采样:自动筛选「错题」重点训练
公式亮点:GRPO算法的核心是「组内奖励标准化」,避免模型被极端分数带偏:
(即把同一问题的多个答案奖励,减去平均值再除以标准差,让模型关注相对优劣)

关键发现:小模型也能逆袭?
-
数据质量:过滤「太简单」和「超纲题」,保留中等难度最有效 -
模型大小:7B小模型+RL训练可接近32B模型性能 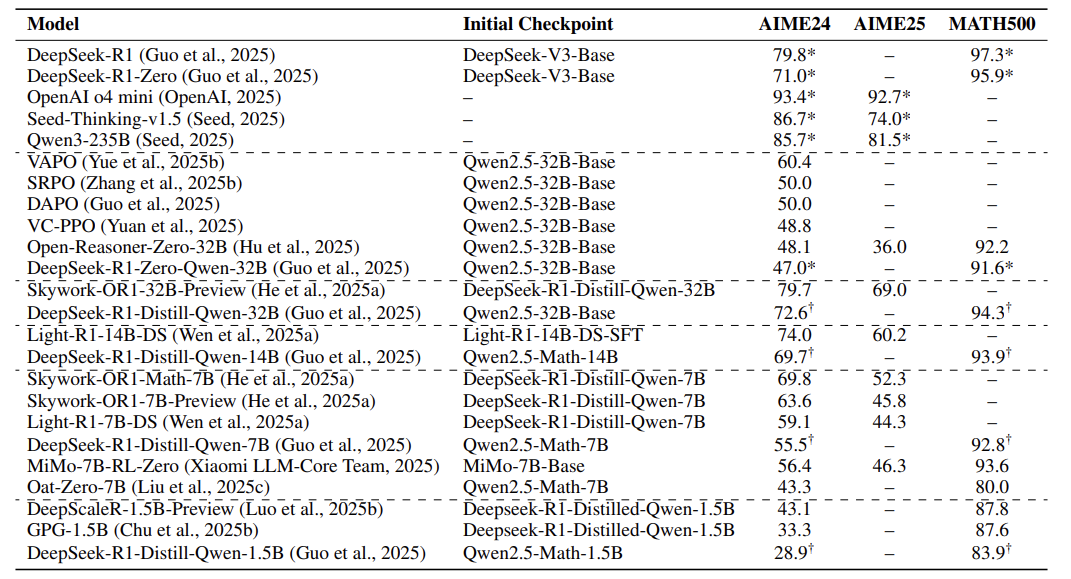
-
训练技巧:逐步增加生成长度(比如从8k到32k token),让模型适应复杂推理
反直觉结论:加入KL散度约束(防止模型偏离初始状态)反而可能限制性能!
未来方向
-
安全风险:过度推理可能导致「废话文学」或绕过安全限制(比如生成恶意代码) -
多模态推理:让模型结合图像、语音等多模态信息(比如解几何题时「看图纸」) -
低成本训练:用偏好优化(DPO)替代复杂强化学习,降低算力需求
最后论文甚至提到用RL训练模型「写诗」和「设计排序算法」,AI的创造力边界正在拓宽!
(文:机器学习算法与自然语言处理)