


长视频理解是多模态大模型的核心能力之一,也是迈向通用人工智能(AGI)的关键一步。然而,现有的多模态大模型难以大规模训练超长视频,并且在处理长视频时,仍然面临性能差和效率低的双重挑战。
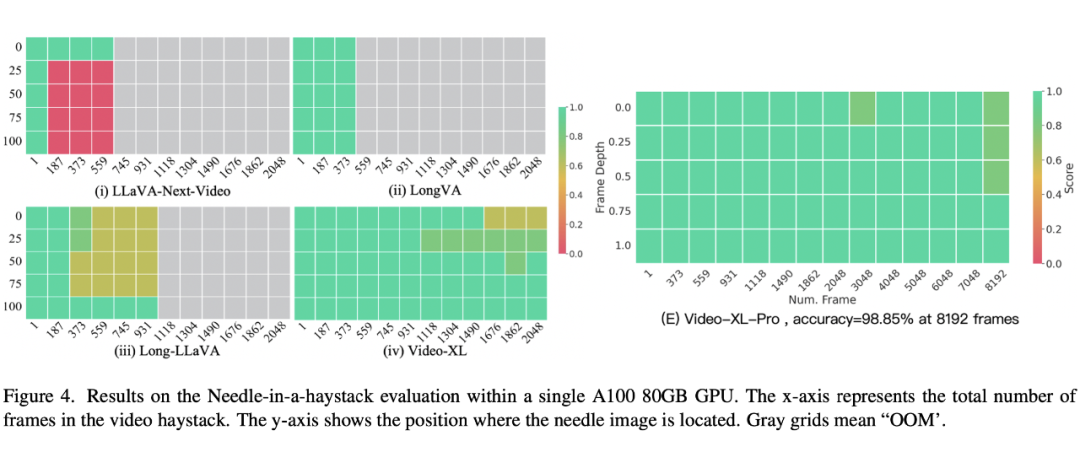
对此,上海交通大学、北京智源研究院、特伦托大学的联合研究团队推出了小时级的超长视频理解大模型 Video-XL-Pro,创新提出“重构式令牌压缩”技术,实现近一万帧视频的单卡处理,大海捞针准确率超 98%!
并且使用较少的训练数据,在多个基准评测上超越了之前 Meta 发布的 7B 模型 Apollo-7B,以及同尺寸的知名开源模型 Qwen2.5-VL-3B,InternVL2.5-4B 等,项目代码,模型,训练数据均已开源!

论文标题:
Video-XL-Pro: Reconstructive Token Compression for Extremely Long Video Understanding
论文链接:
https://arxiv.org/abs/2503.18478
代码链接:
https://github.com/VectorSpaceLab/Video-XL/tree/main/Video-XL-Pro
模型链接:
https://huggingface.co/MINT-SJTU/Video-XL-Pro-3B
训练数据链接:
https://huggingface.co/datasets/MINT-SJTU/Video-XL-Pro-Training

模型结构
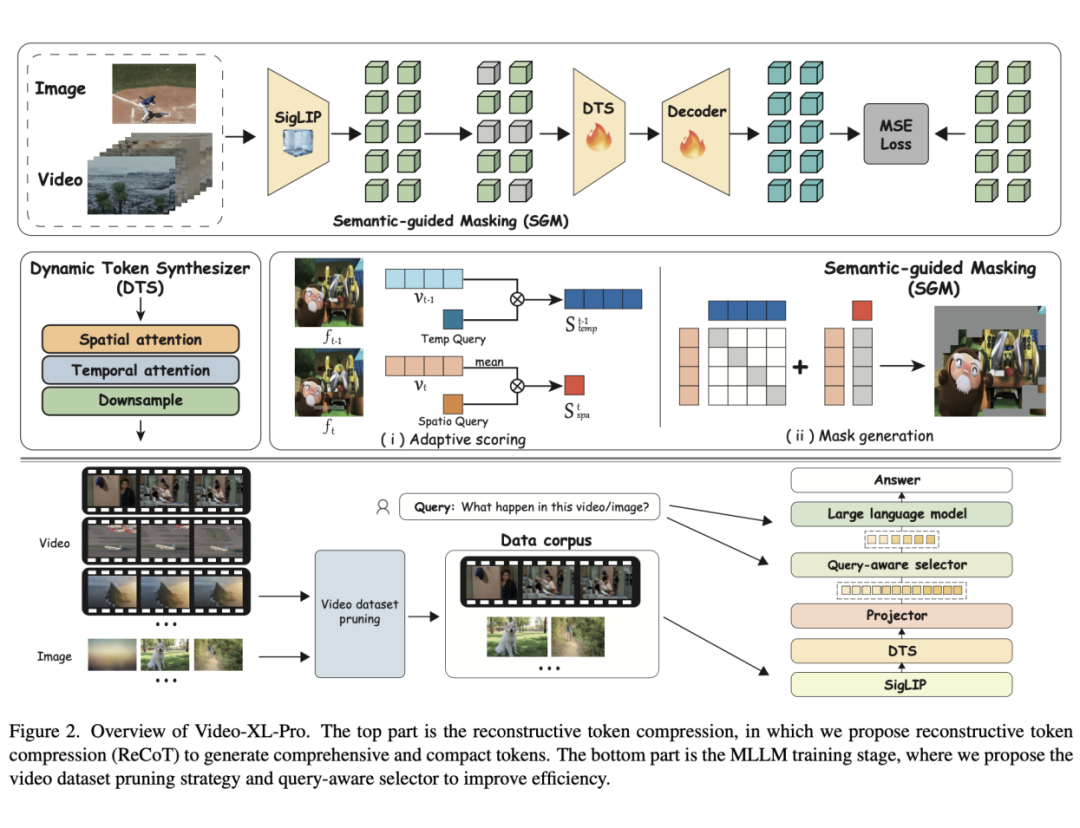
Video-XL-Pro 的核心在于其提出的重构性令牌压缩技术(ReCoT),该技术通过自监督学习生成全面且紧凑的视频令牌,显著提升了视频理解的效率和质量。
ReCoT 包含两个关键组件:动态令牌合成器(DTS)和语义引导掩码(SGM)。DTS 通过轻量级的时空注意力块对令牌进行压缩,有效捕捉视频中的动态运动;而 SGM 则通过自适应掩码策略,减少冗余视觉令牌,从而优化重构学习过程。这些创新设计使得模型在仅需 3B 参数的情况下,性能超越了许多 7B 参数的模型。
此外,为了增强模型对超长视频理解能力,模型还引入了查询选择器,使得在输入上下文超过限制时模型能够选择性关注和查询有关的片段。
为了进一步提升训练效率,研究团队还提出了视频数据集剪枝策略。这些方法通过筛选高质量视频数据,显著降低了计算成本,同时保障模型的性能。

评测基准
Video-XL-Pro 选用多个主流视频理解评测基准,对模型进行了全面的评测,对于长视频理解任务,评测了LongVideoBench、MLVU、Video-MME,TempCompass 和 VNbench。
其中 MLVU,VideoMME,LongVideoBench 集中在评测模型的长视频理解能力。
VNbench 则是兼顾长视频与短视频,TempCompass 则是评测模型在视频中的时间理解能力。
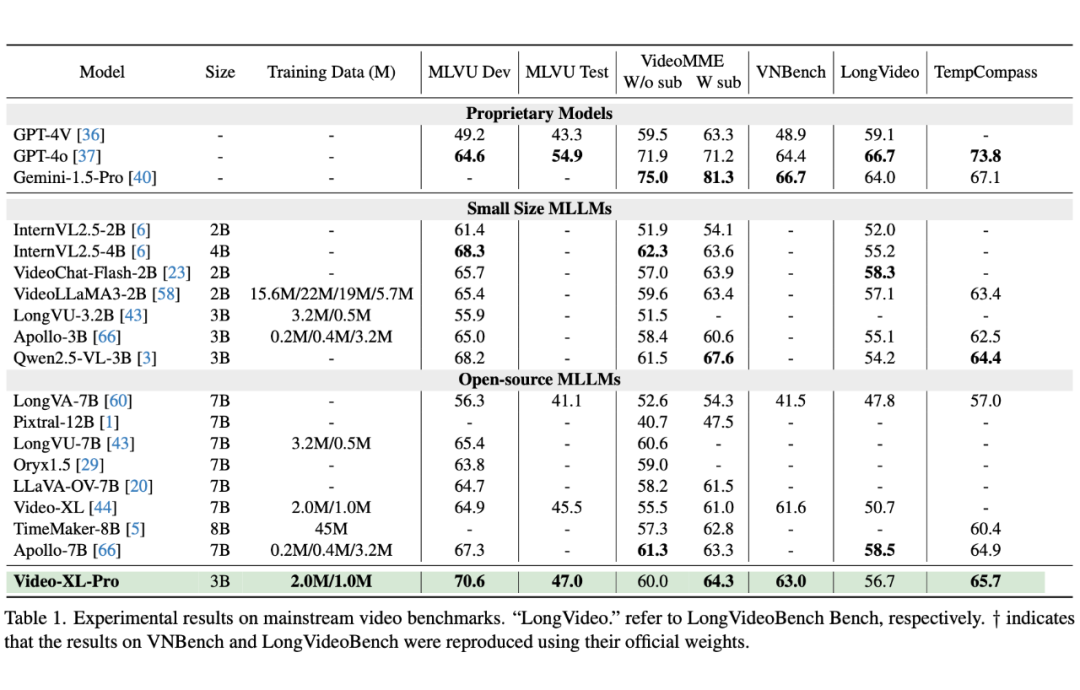
如表 1 所示,Video-XL-Pro 在多个主流的长视频评测基准上展现了卓越性能。
在 MLVU 的 Dev,Test,以及 TempCompass 上,VIdeo-XL-Pro 均斩获了第一名,不光超越同参数量的知名开源模型 qwen2.5-VL-3B 和 internVL2.5-4B 等,也超越了一众 7B 模型,包括 Meta 发布的 7B 模型 Apollo-7B 等。
在 VideoMME,LongVideoBench,Video-XL-Pro 也超越了绝大部分同参数量模型,并达到与 7B 模型相当的水准。
最后在 VNbench上,VIdeo-XL-Pro 也取得有竞争力的结果,说明模型在增强长视频理解能力的同时,也能兼顾短视频能力。
值得注意的是,VIdeo-XL-Pro 只使用了相对较少的 SFT 数据(1M),低于 Apollo 的 3.2M,远低于 Qwen2.5-VL,InternVL2.5 等知名开源模型,进一步说明了方法的有效性。
Video-XL-Pro 还进行了视频「大海捞针」测试来评估其处理超长上下文的能力。得益于 ReCot 模块和查询选择器的设计,使得模型可以输入极长的上下文序列,在相同硬件条件下,模型可以以 8192 帧为输入,达到了近 99% 的准确率。

时间理解
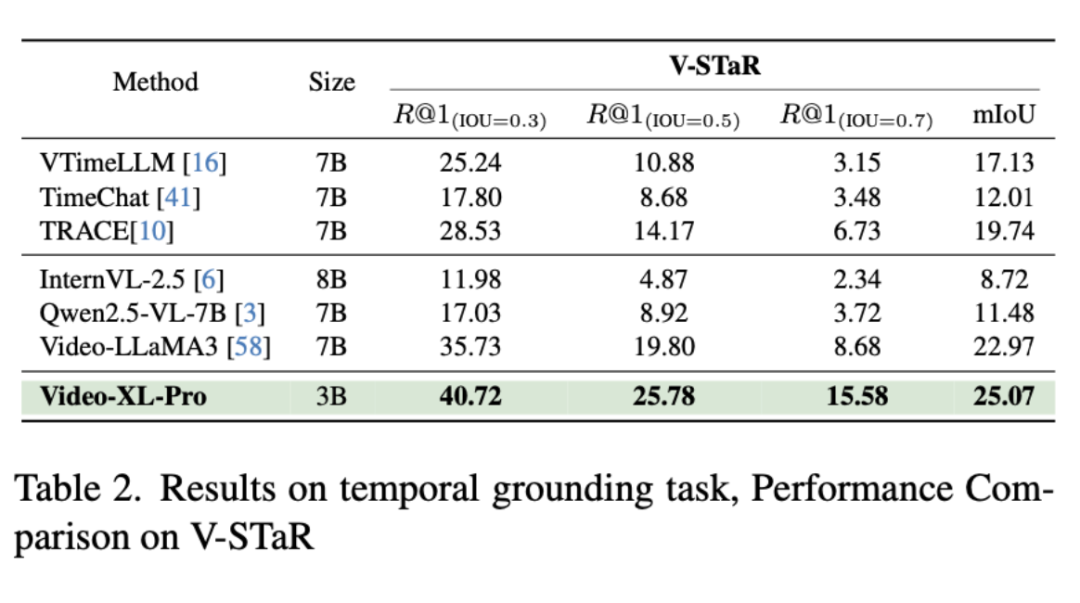
为了更全面的评估模型性能,我们还选用了经典时间评测基准 Charades-STA 和最新的长视频时间评测基准 V-STaR。
V-STaR 注重在极长视频中找出与问题相关的片段,精准回答片段时间范围,现有开源模型在 V-STaR 中很难取得很好的成绩,即便是 Qwen2.5-VL-7B,mIoU 得分也仅为 11.48。
Video-XL-Pro-3B 在最新的 V-STaR 长视频时间基准测试斩获 25.07 的 mIoU 得分,在 IoU>0.7 时仍能达到 15.58 的准确率,远上超越一众知名开源模型,包括 InternVL2.5-8B 和 Qwen2.5-VL-7B,并超越上一代冠军 Video-LLaMA3,展现了卓越的长视频时间理解能力,并且在 Charades-STA 上也有着不俗的表现。


总结
该工作提出了 Video-XL-Pro 模型,利用自监督学习压缩视觉标记,使用相对少量数据下训练的 3B 模型就能获得超越大多数 7B 模型的性能。
Video-XL-Pro 在多个主流长视频理解基准评测上表现优异。模型有望在多个长视频理解的应用场景中展现出广泛的应用价值,成为得力的长视频理解助手。目前,模型、代码、训练数据均已开源,以促进长视频理解社区的合作和发展。
(文:PaperWeekly)