


RAG 要不要做语义检索,有很多讨论,还没有定论。在 InfoQ 举办的 AICon 全球人工智能与开发大会上 Hugging FaceMachine Learning Engineer 尹一峰为我们带来了精彩专题演讲“RAG 基本范式的选择与系统设计”,深入探讨基于语义搜索(Semantic Search)的 RAG 系统的重要性,揭示它为何在当前技术背景下被严重低估,分析语义搜索的本质及其在 RAG 系统中的关键作用,并分享如何基于这一本质设计出高效的系统架构。
此外,演讲还将讨论 KG 驱动的 RAG 系统,并指出它并非适用于所有数据类型,帮助听众理解如何根据不同的数据特性选择最合适的 RAG 范式。
内容亮点:
-
如何设计出更有效的 RAG 系统
-
根据自己的数据和系统,该如何选择 RAG 范式
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
我们需要了解为什么需要 RAG(Retrieval-Augmented Generation,检索增强生成)。原因很简单,因为 LLM 本身存在一些问题。RAG 作为一种辅助工具,其存在是因为 LLM 本身有不足之处。
LLM 的第一个问题是训练成本很高。这个世界在快速变化,而 LLM 的训练成本每次都很高。对于通用模型而言,一旦训练完成,它就会立刻过时,因为它无法知晓训练完成后下一秒发生的事情。
目前大模型的训练主要依赖反向传播。反向传播本质上是在求导,而大模型是一个黑箱,它学习时只对其上一个 step 负责。换句话说,大模型无法做到“牵一发而不动全身”,即无法在某个领域取得进步时,仅通过改变其分布而不影响其他部分。
第二个问题是幻觉(Hallucination)。由于 LLM 是一个自回归的概率模型,只要涉及概率模型,就不可避免地会产生幻觉,这是无法彻底根除的。不过,可以通过一些方法来缓解这种症状。
目前,主流的模型主要是以 Transformer 架构为驱动的自回归模型。虽然情况正在发生变化,现在 Transformer 架构的主导地位已经面临挑战,咱们后面会提到。
自回归模型本质上仍然是一个数学模型。它根据 prompt 和之前的 token 来预测下一个 token,即条件概率模型。
从理论上讲,可以通过调整 prompt,让大语言模型输出任何 token 组合,只要这些 token 在 tokenizer 之内且不太长。我们可以通过提示的形式,以条件的形式来控制输出。
因此,RAG 的两个主要问题——幻觉问题和分布偏移问题,都可以通过调整 prompt 来解决。RAG 的本质就是提示工程(prompt engineering),通过调整条件,使其条件不同,从而调整其概率分布 ,在不改变 θ 的情况下。

RAG 实际上是一种通过检索方式来选择用于提示工程的材料的方法。具体来说,就是需要向 Prompt 中添加内容。
实际上,任何形式的搜索都可以实现这一目的,比如使用 SQL 搜索引擎,或者像谷歌这样的通用搜索引擎,甚至直接从数据库中检索等。只要能够找到合适的文件,都可以作为 RAG 的输入材料。
在这一过程中,不一定需要使用 ML。如果使用 ML,成本可能会更高。RAG 的核心在于通过改变条件来影响输出分布。具体而言,输入的新知识可以对抗分布偏移(Distribution Shift),而提供的相关文件则用于减少幻觉。
Semantic search(语义搜索)的核心在于通过特定的技术手段,实现对文件和 query 之间的语义匹配。它的起源可以追溯到理论计算机科学中的一个重要工具——metric embedding。在数学上,metric embedding 是将文件映射到一个高维的测度空间(metric space)中。
这个测度空间需要满足泛函分析中的 Metric Distance Function(度量距离函数)的四个条件:自身距离为 0、两个不同点的距离大于 0、距离对称性以及三角不等式。
现代 Semantic search 并不一定局限于测度空间。在实际应用中,它可能会使用一些非测度距离,例如非常常用且出名的 Cosine Distance(余弦距离)。这是因为 Cosine Distance 虽然不符合测度空间的严格定义,但在语义搜索中仍然能够有效地衡量向量之间的相似性。
在 Semantic search 中,文件被嵌入到一个高维空间中,这个嵌入过程是通过一个 embedding model 完成的。这个模型的作用是将文件映射为向量,并使得这些向量之间的距离能够有意义地反映文件之间的语义关系,例如亲密度或相似度等。
Semantic search 的本质是将文件本身作为索引(document as index)。传统数据检索依赖于预设的索引,但这种方法的前提是用户必须明确知道自己需要什么。然而,在许多情况下,用户可能并不清楚具体需要什么文件。
Semantic search 解决了这一问题,它允许直接将文件作为索引,并通过 embedding 的形式与查询进行对比,从而最大限度地保证与查询的适配性。
这种方式在不知道具体需要哪个文件的情况下,依然能够找到最相关的文件,具有很大的灵活性。这种灵活性在处理低资源文件和长文件时尤为突出,采用的模式称为 Multi-Vector Retrieval(多向量检索)。
例如,在构建关于 Rust 代码的向量数据库时,会面临一个典型问题:在 embedding 模型的训练过程中,模型接触到的自然语言数据量远远超过 Rust 代码。
因此,embedding 模型更适合处理自然语言,而不是 Rust 代码。然而,query 多数情况下是用自然语言提出的。这就需要一种方法,将 Rust 代码相关的问题转化为自然语言问题,以便模型能够更好地适应。
具体做法是利用自然语言,例如代码注释、README 文档等来对 Rust 代码进行索引。通过这种方式,向量化的文件索引也是基于自然语言的,查询时对比的也是这种自然语言索引。这样一来,检索效率和准确率都会显著提高,当然前提是自然语言索引本身是可靠的,否则将无法达到预期效果。
对于超长文件的情况,如果需要完整检索而不能将其分割成小块(chunk),解决方案也很简单。可以使用文本的总结来对长文本进行索引,然后对文本总结进行向量化索引。
正如计算机科学的伟大先驱 David Wheeler 所说,“在计算机科学中,几乎所有的复杂问题都可以通过增加一层迂回(indirection)来解决”,这实际上就是增加了一层迂回。这种方法的普适性非常高。
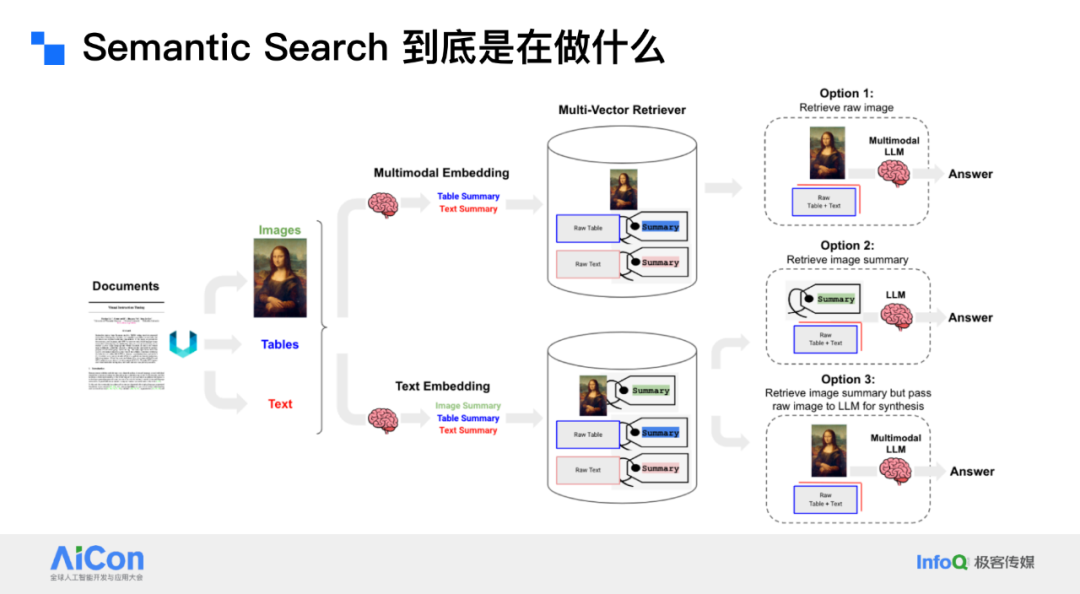
同样的方法也可以应用于多模态检索。例如,当一个包含图像、表格和文本的文档进入系统时,可以将它们分开,并为每个部分生成一个标签。然后可以通过自然语言进行检索。
甚至可以将这种方法与多 Multi-Vector Retrieval 结合起来,使用 Multi-embedding 方式。例如,对于图像,如果需要原始图像,可以直接对其进行嵌入;如果需要总结,则使用其总结进行嵌入。方法多种多样,能够灵活应对不同类型的检索需求。
Semantic Search 看似行将就木,原因在于其本身缺乏明确的数据结构。它本质上是一堆向量的集合,这些向量简单地堆在一起,而没有更深层次的组织形式。
在传统的搜索方法中,通常会借助树状结构或其他形式的索引关系来优化搜索效率,但 Semantic Search 中并不存在这样的结构。原生的 RAG 系统本身也没有任何系统化的结构。
在 ANN(Approximate Nearest Neighbors,近似最近邻)中所使用的结构,虽然在某种程度上可以用于检索小型数据库,但它并不是为了构建系统结构而设计的。
然而,正如老子所说“无为而无不为”,他什么都不是,那就什么都可以是。正是因为 Semantic Search 没有内在的数据结构,反而为其提供了极大的灵活性。这种灵活性使得我们可以为其赋予任何合适的数据结构。
RAG 系统设计的关键之一,就是为 Semantic Search 提供一个数据结构,使其更贴近数据的天然结构。例如,如果数据的天然结构是一棵树,那么就可以将系统设计成树状结构;如果数据的天然结构是一根草,那么就可以设计成相应的草状结构。
系统设计是整个工作的重中之重。在深入探讨之前,需要先强调一个重要的观点:工程是取舍的艺术(Engineering is the Art of Trade-off)。这是我仅有的 3 年工程师生涯中领悟的最重要的道理,我觉得,这也是每一位工程师都必须深刻理解的核心理念。
工程师需要明确自己能够做出什么样的取舍权衡(trade-off),能够接受什么,不能接受什么,以及可以在哪些方面做出牺牲,以换取其他方面的利益。这些是必须仔细考虑的问题。接下来所有的内容都会是这个原则的拓展延伸
在整个系统设计环节中,权衡是核心原则。以 Contrastive Loss(对比损失函数)为例。对比损失函数的公式,我们很明显看得出他是一个 switch loss. 什么意思呢?当标签 y=0 时,1−y=1,因此公式中的一项被触发,而另一项则不被触发(switch)。
此时,损失值为 ,即距离的平方。当 y=1 时,1−y=0,只有另一项被触发。公式中的 是一个缩放因子(scaling factor),通常不会对结果产生显著影响。
因此,损失值为 。如果 大于 m,即距离大于阈值 m,那么 是一个负数,小于 0,因此损失值为 0。相反,如果 DW 小于 m,则损失值为正。
换句话说,对比损失函数的关键在于距离 。只要有距离存在,就会产生损失。这种损失会将相似的点(尽可能地拉到同一个点上,即把相似的样本紧密地聚集在一起。
然而,往外推的机制仅在距离小于阈值 m 时起作用。如果距离超过了阈值 m,则对比损失函数不再对其产生影响。所以,一个 batch 的 loss 是 0 的时候,可能你不需要太慌张。由此可知,Contrastive loss 形成的是多个相距 m 距离的紧密聚类,适用于结构紧密,方差较小的数据。

接下来的例子是 Triplet Loss(三元组损失)。其中,d 表示距离,a 表示 anchor(锚点),p 表示 positive(正样本), n 表示 negative。Triplet Loss 的计算方式是:Anchor 到 Positive 的距离减去 Anchor 到 Negative 的距离,再加上一个阈值 m。
如果 Anchor 到 Positive 的距离减去 Anchor 到 Negative 的距离的绝对值小于阈值 m,那么损失值就不是 0;反之,如果这个绝对值大于或等于 m,那么损失值就是 0。
也就是说,Triplet Loss 并不关心 Negative 和 Positive 之间的距离有多远,它只关注这两个点与 Anchor 之间距离的差值是否小于阈值 m。如果差值小于 m,它会将样本向外推,使其满足条件;如果差值已经大于或等于 m,那么它就不再进行优化,损失值为 0。

在训练使用 Triplet Loss 和 contrastive loss 的模型时,都可能会出现整个批次的损失值为 0 的情况。这时不要急于下结论,这并不一定意味着模型过拟合。可能只是巧合,该批次的数据恰好满足了损失函数的条件。因为 Triplet Loss 只关注 positive 和 negative 与 anchor 之间的相对距离,所以它很容易满足条件,导致模型更新较少,收敛速度相对较慢。
此外,只有当相对距离小于阈值 m 时,才会产生损失值。与对比 Contrastive Loss 不同,Triplet Loss 不会将所有相似的样本强行聚到一个点上,因此同类内方差(Intra-Clas Variance)较大。
它形成的聚类通常是距离大致等于 m 的较大范围的集合,而不是紧密聚集在一起。这意味着一个类别中可以包含更多元的样本。
Triplet Loss 特别适用于类内方差较大的数据。例如,人脸数据就是一个很好的例子。很多人对人脸数据存在误解,认为同一个人的不同人脸图像之间的差异很小,但实际上,同一个人在不同光照、角度、表情等条件下的脸可能有非常大的差距。
这就是为什么 triplet loss 是人脸识别的默认 loss。而那些没有看过数据整天想当然的工程师可能就会选用应对小方差的 Contrastive loss。选择损失函数的前提是必须充分了解数据,只有真正理解数据的特性,才能明确应该采用什么样的损失函数来指导模型训练。 对于其他各种损失函数,也可以用类似的方法进行分析。
在选择 Distant Function 时,需要考虑其本质是度量嵌入。从这个角度出发,几乎所有的距离函数可以分为两类:一是满足度量空间(Metric Space)定义的距离函数,例如欧几里得距离(Euclidean distance),也叫 L2 距离;二是不满足度量空间定义的余弦距离(cosine distance)。
余弦距离不是度量距离的原因在于它不满足度量空间的两个基本条件:非负性(positivity)和三角不等式(triangle inequality)。大致证明如下:假设从原点出发有两个不同的点,它们在同一条直线上,但方向相反。
这两个点的余弦相似度是相同的,这意味着它们的“距离”为 0,这显然不符合非负性。此外,考虑三个点 x = [1, 0]; y = [0, 1]; z = [1, 1],,余弦距离不满足三角不等式,即两边之和小于第三边。
尽管余弦距离不符合度量空间的定义,但它具有计算简单的优势,因为它只考虑方向,而与 Magnitude 无关。这使得余弦距离特别适合那些只关注方向的场景,例如在推荐系统中,如 Netflix 和 Spotify。
如果用户喜欢摇滚音乐,那么所有与摇滚相关的方向都是相关的;如果用户喜欢恐怖电影,那么所有与恐怖电影相关的方向也是相关的。在这种场景中,不需要考虑具体的数值,只需要确定方向即可。余弦距离的值域在 0 到 1 之间,也不会出现数值溢出的情况。

欧几里得距离(Euclidean distance)与余弦距离不同,其计算相对复杂,需要考虑两个点在空间中的实际距离。这有点类似于 Word2Vec 模型中通过训练得到的向量空间关系,例如“king – man = queen – woman”这种语义关系。
欧几里得距离非常适合复杂场景,比如电商推荐。在这种场景中,方向只是考虑的一个方面,还需要关注细节。
然而,欧几里得距离可能会出现数值溢出,因为它是一个无界的距离,其值可以非常大或非常小。此外,在高维空间中,欧几里得距离可能会导致数据稀疏。
尽管欧几里得距离存在这些缺点,但仍然需要讨论它,因为它是一个 metric distance。这意味着可以通过深度学习来模仿一个 metric space。例如,假设使用对比损失函数,并且有越南语到中文的数据,但没有越南语到图片的数据。
在这种情况下,如果模型训练得当,越南语到中文之间的距离最大为 m,中文到图片的距离也最大为 m。根据三角不等式,越南语到图片的距离最多为 2m。因此,通过将搜索范围扩大到 m,就可以找到想要的结果。
这是度量距离的一个非常强大的用途,即三角不等式的应用。将模型训练到这种程度是具有极大难度的,虽然可以实现,但需要付出巨大的代价。这取决于是否愿意做出这种权衡。

在选择 Embedding 模型时,主要需要考虑的是 LLM 与 Encoder 之间的权衡。LLM 的归纳偏差(Inductive Bias)并不特别适合用于嵌入任务,但可以通过一些手段,如重复(repetition)来解决。
例如,将相同的内容输入两次,最后一个输出肯定包含了之前所有上下文的信息。然而,使用 LLM 进行推理和训练的成本更高,需要更多的训练数据。正如 ViT 文章中提到的一句经典观点:“大规模训练胜过归纳偏差(Large scale training trumps inductive bias)”。
即使归纳偏差可能是错误的,只要训练规模足够大,模型仍然可以解决问题。相比之下,编码器的归纳偏差更适合嵌入任务,因此可以用更小的模型达到相同的效果。
如下图所示,NV embed-2 是一个拥有 70 多亿参数的模型,其评分是 72.31。排名第 1。而 Stella 是一个只有 4.35 亿参数的模型,其平均评分是 70.11。尽管两者评分相差不大,但参数数量却相差数倍。
这说明,如果真的需要那额外 2 分的性能,可以使用大模型,否则,一个小模型完全可以胜任嵌入任务。

一般来说,对于训练良好的模型,其优先级顺序为:性能 / 成本权衡(Performance/Cost trade-off)> 数据领域(Data domain)> 损失函数(Loss function)> 距离度量(Distance Metric)。
为什么呢?因为在有足够的数据进行训练的情况下,损失函数和距离度量是可以灵活调整的。
例如,Contrastive Loss 训练的模型可以相对容易地改为 Triplet Loss,使用 Euclidean Distance 训练的模型也可以相对容易地改为 Cosine Distance。但是,性能与成本之间的权衡是难以改变的,除非进行极端的优化。因此,性能 / 成本权衡是更为重要的考虑因素。
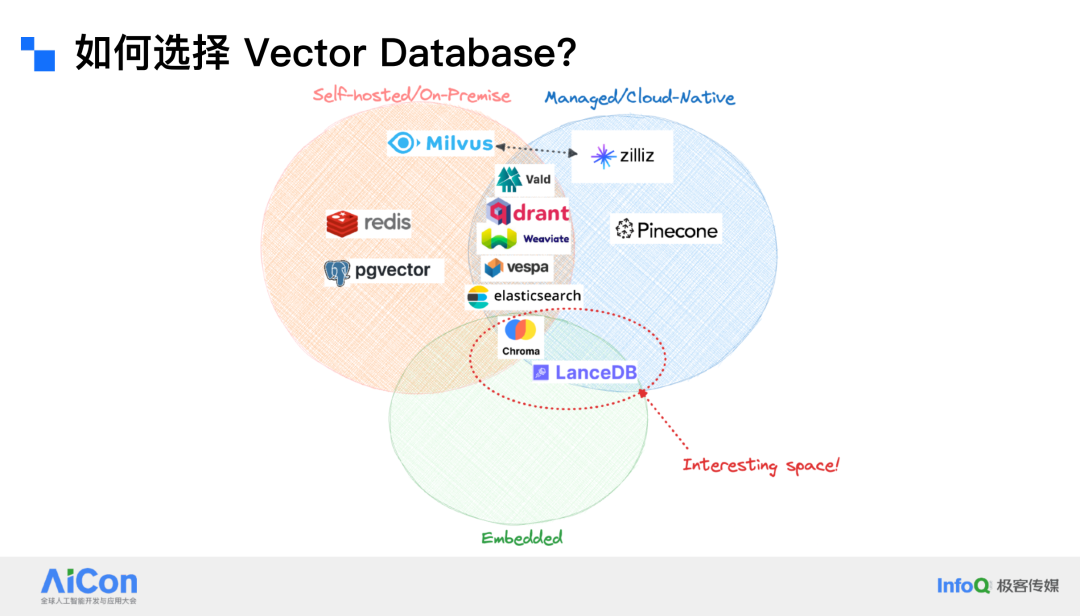
在选择向量数据库(Vector Database)时,首先需要考虑的是选择开源还是闭源的解决方案。开源的向量数据库通常具有灵活性,因为可以直接访问源代码并根据需求进行修改。闭源的向量数据库则可能在安全性方面更具优势。此外,还需要考虑数据库的实现语言,例如 Go、Rust、Java 或 C 等。
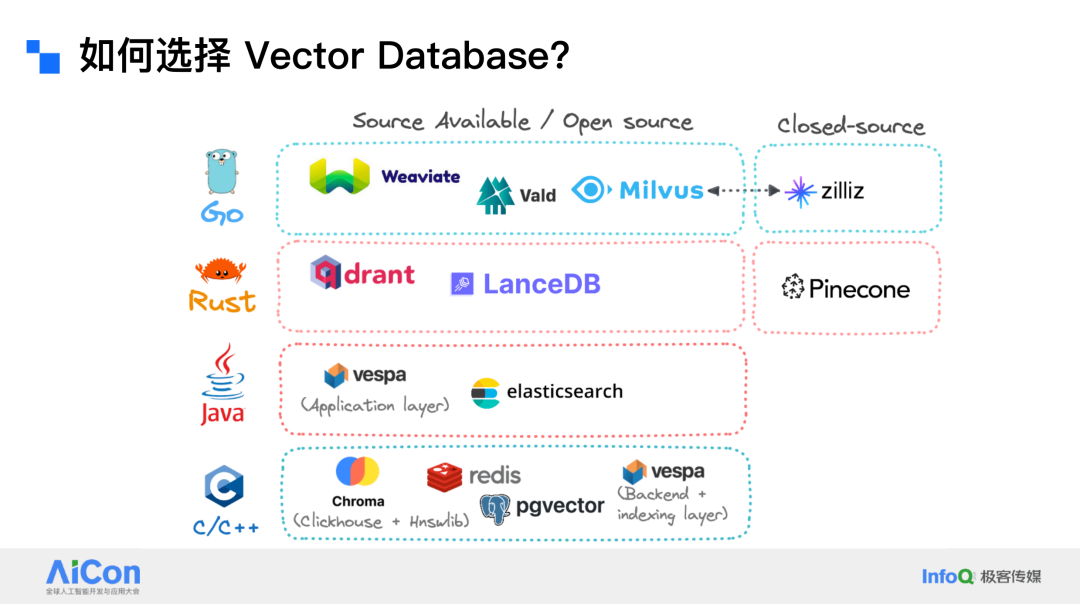
如果对隐私要求极高,无法使用云端服务,那么只能选择本地部署 On-premise 的解决方案。如果可以使用云端服务,那么选择的范围会更广。嵌入式模型(embedded model)是 LensDB 等系统采用的一种模式,这种模式在资源利用方面相对高效。
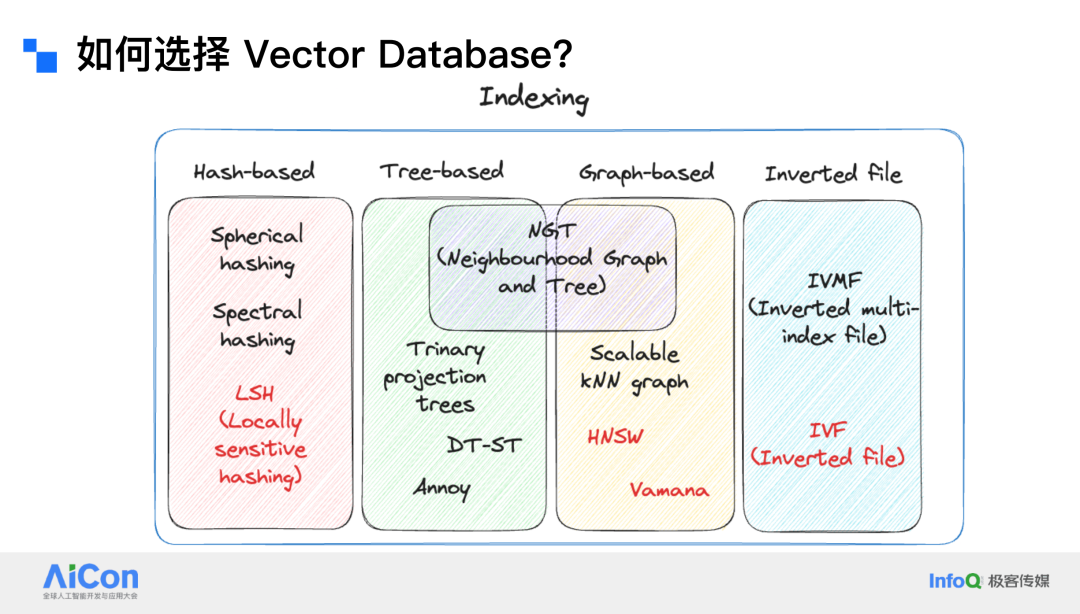
在索引(indexing)方面,目前主要考虑以下四种方式:哈希(hash)、树(tree)、图(graph)和倒排索引(inverted file index)。哈希索引的优点是检索速度快,能够处理大规模数据,但其准确度一般。
树索引是 Spotify 等公司一直在使用的方案,它在低维数据上效果很好,但在高维数据上表现欠佳。图索引(如 Hierarchical Navigable Small World,HNSW)对高维数据非常友好,且相对省内存。在不确定使用哪种索引时,图索引是一个不错的选择,因为它适用于大多数场景。
倒排索引(IVF)可以通过网格状数据结构迅速缩小搜索范围,但其构建过程可能较长,可能需要使用乘积量化(product quantization)等手段来加速。
系统设计的重点之一是为 Semantic Search 提供一个结构。例如,对于类似教科书的数据,其天然结构是分层的。以微积分教科书为例,可以将其分为导数章节、链式法则小节等。对于代码库,可以将代码文件和代码片段进行分层。
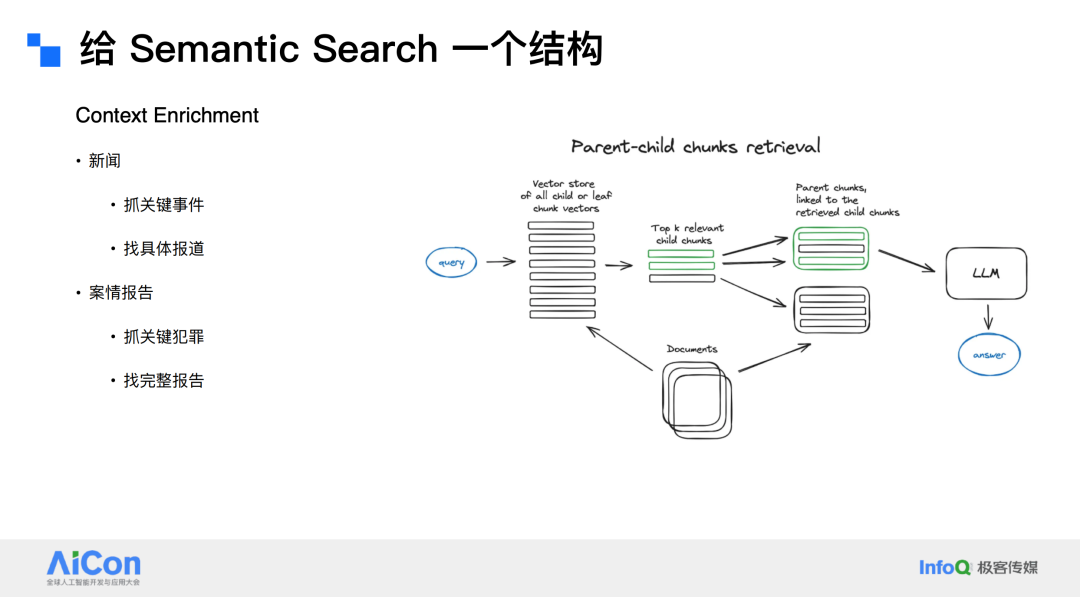
此外,还可以进行 Context Enrichment,例如将文本分割成句子级别的块,在精准定位到某一句后,为其添加上下文信息。这种方法适用于新闻等场景,例如在抓取关键事件后补充前因后果。
对于案情报告,可以抓取关键犯罪信息,然后向上追溯审理过程,向下查找判决结果。还有一种方法是 Parent-child chunk retrieve,即当需要检索整个文件而非几个片段时,可以将所有片段关联到其所属的文件。例如,在案情报告中抓取到犯罪信息后,可以直接检索到完整的报告。
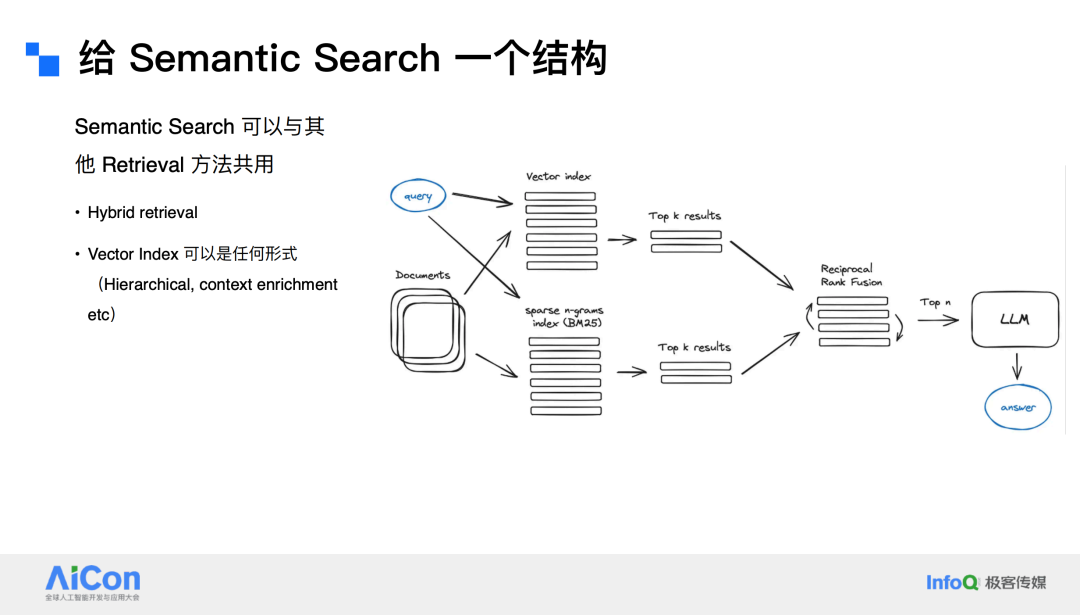
语义搜索可以与其他任何检索方法结合使用。例如,可以同时使用向量索引(Vector index)和 BM25 等传统检索方法,将两种方法的 Top-K 结果合并。向量索引可以是分层的,也可以是 Context Enrichment,具体取决于数据的结构和需求。
人类提出的 query 往往可能存在“文不达意”的情况,为了解决这一问题,可以利用 LLM 来生成一个更适合嵌入的新查询。此外,LLM 甚至可以被专门训练以适应特定的任务。
例如,可以采用“step back prompting”(后退提示)的方法。假设有人提出了一个关于物理的问题:已知压力为 p,理想气体的温度增加了一倍(温度乘以 2),体积增加了 8 倍(体积乘以 8),那么压力 p 会如何变化?在这种情况下,可以通过“step back”来思考:这个问题背后涉及哪些物理原理?需要使用哪个公式?明确了公式之后,再进一步分析问题。
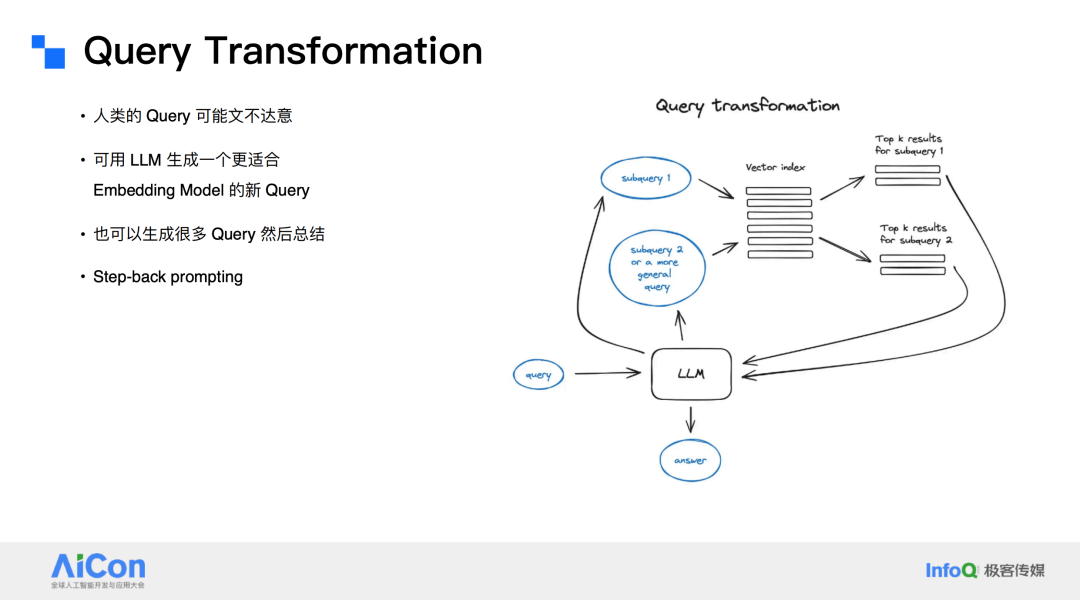
如果原始查询过于宽泛,可以将其拆分成多个更具体的子查询,分别处理后再将结果融合在一起,从而减少混淆,最终得出更准确的结果。这种方法特别适合处理复杂的系统问题。
还有一种方法是在模型给出回答后,给予一个反馈(reward)。模型会根据这个反馈进行调整和重写,这有点类似于“reflection”(反思)的过程,通过这种方式逐步优化回答的质量。
系统设计可以采用 Multi-agent 架构,这种方式特别适用于复杂的系统。因为没有任何一种数据结构能够完美适用于所有类型的数据,这与当年提出的“没有免费午餐定理”(No Free Lunch Theorem)依然相符,在所有可能的问题上,没有任何一种算法能够普遍优于其他算法。
在 Multi-agent 系统中,每个智能体都可以是一个完整的检索系统。例如,一个智能体可能是基于 SQL 的检索系统,另一个可能是基于最近搜索的系统,还有的可能是基于分层结构的检索系统。
当然,这种架构还需要实现查询路由,即需要明确将查询发送到哪个 Agent 系统中进行处理。
我们之前讨论了多种数据结构和系统设计方法,但似乎遗漏了一个非常重要的数据结构——实体及其关系(Entities and their relationships)。这种数据结构在自然界中非常常见,例如通过关系型数据库来组织数据。
虽然我们确实可以用 Semantic Search 和向量数据库来模拟这种数据结构,但实际上没有必要这么做。因为我们已经有了更专业的工具,那就是 KG(知识图,Knowledge Graph)。
KG 是语义搜索中一个非常重要但又容易被忽视的部分。它虽然可以通过语义搜索来实现,但这并不是语义搜索的必要功能。知识图谱的核心价值在于它能够清晰地描述实体之间的关系,并将整个数据库的内容串联起来。
例如,它可以回答“这个数据库到底是什么主题的”这类全局性问题。知识图谱的这种能力是其真正的闪光点。
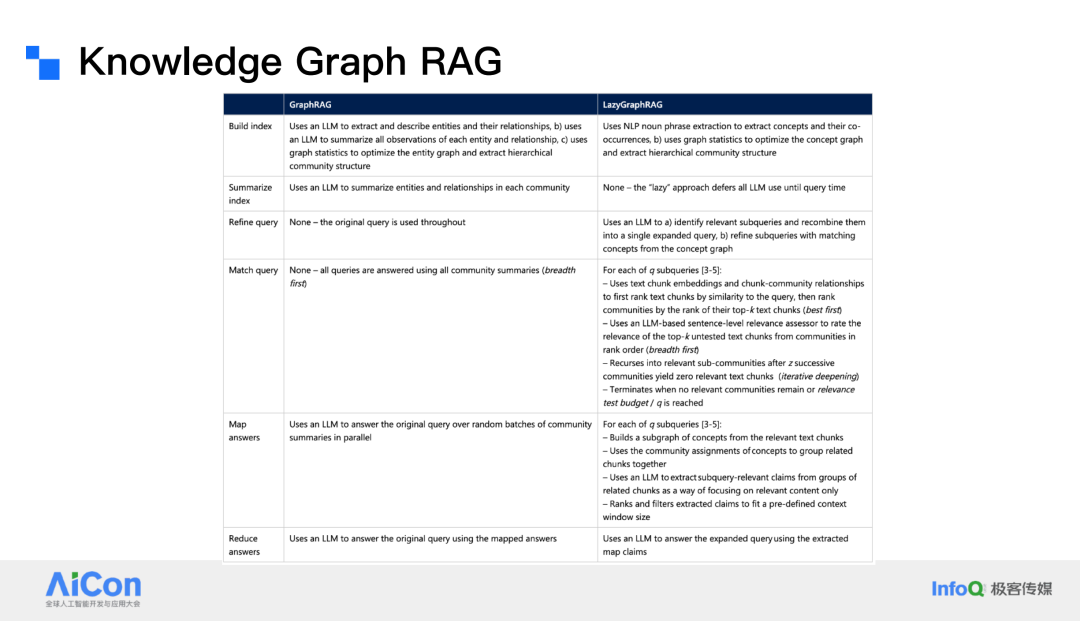
KG 的构建过程可以分为几个步骤。首先,从一个 Ontology 开始,然后通过充实细节将其扩展为一个完整的知识图谱。
在构建知识图谱时,思维方式应该是面向对象的。例如,作者(Author)和出版商(Publisher)之间的关系可以被清晰地定义。作者可以有多个子实体,例如海明威,莫言等。
KG-RAG(Knowledge Graph Retrieval-Augmented Generation,知识图谱 RAG )是为全局查询和聚焦总结而设计的,而不是用于处理单个的点对点问题。这是知识图谱的强项,因为它能够清晰地描述实体之间的关系,并将整个数据库的内容串联起来。
在 KG 的构建过程中,从源文档中提取片段后,会进行领域定制的总结,然后将片段转化为元素,再从元素进行进一步总结,最终将元素提升为组。除了第一步之外,后续步骤都需要大量使用 LLM,因此成本非常高。KG-RAG 的成本大约是简单向量 RAG 的 1000 倍左右。
因此,尽管 KG-RAG 在理论上非常强大,但在实际应用中,由于成本过高,导致其“叫好不叫座”,很多人觉得它很有潜力,但实际使用时却因为成本问题而难以推广。
为了解决这个问题,微软的研究人员开始思考如何降低 KG-RAG 的成本。他们意识到,知识图谱和语义搜索并不是互斥的,而是可以共存的。于是,他们提出了“Lazy Graph RAG”这种新的方法。
语义搜索可以被看作是一把“狙击枪”,能够直接找到最相关的几个结果;而知识图谱则更像是一个“breath-first search”,从一个切入点开始,能够找到与之相关的所有信息。Lazy Graph RAG 的核心思想是利用语义搜索来弥补知识图谱的不足。
通过这种设计,Lazy Graph RAG 能够显著降低索引构建的成本,将其降低到与简单向量 RAG 相当的水平,大约是上一代产品的 0.1%。由于成本的大幅降低,Lazy Graph RAG 可以更容易地扩展到大规模应用中。低成本使得系统可以更灵活地扩展,从而更好地满足实际需求。
KG-RAG 和 Semantic Search 在系统设计和资源利用的区别。
-
KG-RAG:当数据可以通过实体和关系模型清晰地表示时,KG-RAG 是最优选择。它能够充分利用知识图谱的结构化优势,处理复杂的全局查询和总结任务。
-
Semantic Search:如果数据没有现成的结构化模型,或者需要快速搭建适合特定数据的检索系统,Semantic Search 是一个灵活且高效的选择。通过语义搜索,可以快速定位相关内容,而无需依赖复杂的图结构。
Lazy Graph RAG 结合了两者的优点,通过语义搜索精准定位,再利用知识图谱的结构化优势进行扩展,既降低了成本,又保持了高性能。
大模型正在快速向端设备(如手机)迁移,这一趋势将很快实现。但无论模型如何优化,RAG 仍然是必要的。因此,需要更好的方法在手机等设备上存储信息,并且需要更快的 RAG 实现,因为手机的 GPU 资源有限。
目前的大语言模型主要基于 Transformer 架构的自回归(auto-regression)模型。然而,这一领域正在发生变化,出现了许多新的模型架构,如 RWKV、Mamba、TTT、Hyena 等。
这些模型正在争夺 Transformer 的主导地位。这些新模型的一个重要特点是,它们的嵌入和生成可以由同一个模型完成。例如,RWKV 类似于经过优化的 RNN,它将之前的所有信息存储在一个隐藏状态(hidden state)中,而不是以 token 的形式表示。
从某种意义上说,Transformer 本质上也是一种 RNN,其隐藏状态是之前的所有 token,并且它通过机制解决了大规模并行化的问题。将文件输入 RWKV 模型后,可以得到一个文本生成结果,包含了之前所有信息的精华。
这意味着几乎不需要原文,因为嵌入不仅包含了语义搜索的意义,还包含了文本本身在模型中的意义。然而,这种模型的缺点是,如果更换生成模型,需要连同嵌入模型一起更换,因为它们是一个整体。这仍然是一个权衡,取决于你能接受什么。
未来可能会出现非自回归的生成模型,例如扩散模型(Diffusion Models)或归一化流(Normalizing Flows),但目前这些模型还在发展阶段,尚未完全成熟。自回归模型的逐个 token 生成方式与人类生成语言的方式不同。
人类在生成语言时,通常会先确定一个主旨,然后围绕这个主旨组织语言。而自回归模型是基于大量数据训练出来的,其归纳偏差是逐个 token 生成,但是这在某些任务中可能不是最优的。
不过也是应了 ViT 作者的那句话,Large scale training trumps inductive biases。但是我依然觉得,在大数据的情况下,如果能找到更合适的归纳偏差,可以显著提升模型的效率和性能。
目前的大模型已经达到了人力和数据的极限,未来可能会有更好的发展。记住,压缩是关键,训练模型本质上是对信息的压缩。
在当前情况下,机器学习系统设计的最佳实践是尽量避免使用机器学习,因为它成本高昂。如果能用 SQL 解决问题,就用 SQL;如果能用 Elasticsearch 解决问题,就用 Elasticsearch;如果能用正则表达式解决问题,就不要用 LLM。
运行巨量正则表达式的成本可能只有几分钱,而运行一个小 LLM 的成本则要高得多。尽量使用传统方法解决传统方法能够解决的问题,将机器学习用于那些传统方法无法解决的问题。不要因为机器学习很酷就滥用它,否则最终可能会因为成本过高而后悔。
AICon 2025 强势来袭,5 月上海站、6 月北京站,双城联动,全览 AI 技术前沿和行业落地。大会聚焦技术与应用深度融合,汇聚 AI Agent、多模态、场景应用、大模型架构创新、智能数据基建、AI 产品设计和出海策略等话题。即刻扫码购票,一同探索 AI 应用边界!!

今日荐文
3200+ Cursor 用户被恶意“劫持”!贪图“便宜API”却惨遭收割, AI 开发者们要小心了
宇树王兴兴:公司所有岗位都非常缺人;消息人士称马云回归“绝不可能”;零一万物联合创始人离职创业 | AI周报
拜拜,昂贵的谷歌搜索 API!阿里开源 RL 框架让大模型自给自足、成本直降88%,网友:游戏规则变了
Mistral 拿出杀手锏叫阵 DeepSeek!性价比卷出天际、开源模型却断供,社区粉丝失望透顶
碾压 Cursor?谷歌突发 Gemini 2.5 Pro 预览版,编码能力全网第一

你也「在看」吗?👇
(文:AI前线)