


本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。其主要研究方向为:大语言模型的安全性及其在复杂场景中的推理。
说服,是影响他人信念、态度甚至行为的过程,广泛存在于人类社会之中。作为一种常见而复杂的交流形式,这一颇具挑战的任务也自然地成为了日趋强大的大语言模型的试金石。
人们发现,顶尖大模型能生成条理清晰的说服语段,甚至在 Reddit 等用户平台以假乱真,但大模型在心智感知方面的缺失却成为了进一步发展说服力的瓶颈。
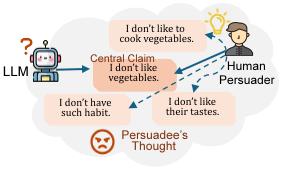
成功的说服不仅需要清晰有力的论据,更需要精准地洞察对方的立场和思维过程。这种洞察被心理学称为「心智理论」(ToM),即认识到他人拥有独立的想法、信念和动机,并基于此进行推理。这是人类与生俱来的认知能力,而大模型在对话中却往往缺乏心智感知,这导致了两个显著的缺陷:
-
模型往往仅围绕核心论点展开讨论,而无法根据论点之间的联系提出新的角度; -
模型往往仅关注并重复己方观点,而无法因应对方态度变化做出策略调整。
为解决这一问题,伊利诺伊大学香槟分校的研究者提出了 ToMAP(Theory of Mind Augmented Persuader),一种引入「心智理论」机制的全新说服模型,让 AI 更能「设身处地」从对方的角度思考,从而实现更具个性化、灵活性和逻辑性的说服过程。

-
论文标题:ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
-
论文地址:
https://arxiv.org/pdf/2505.22961 -
开源代码仓库:
https://github.com/ulab-uiuc/ToMAP
ToMAP:知己知彼,百战不殆
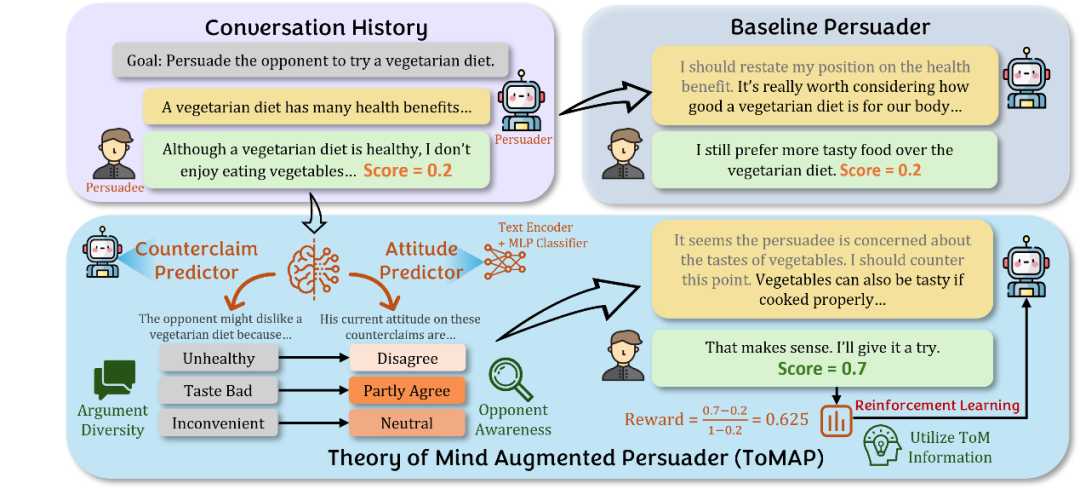
ToMAP 创新性地在说服者框架中引入两大心智模块:反驳预测器和态度预测器。
反驳预测器模拟人类在说服中主动预判对方可能持有的反对观点。本文发现,大模型说服者本身就具备反驳预测的能力,只需要通过提示词设计「激活」这一能力即可。定性与定量分析显示,基于模型生成的反驳观点与真实被说服者的观点在语义上高度相似。这让说服者在对话中占据「先发优势」,从而主动化解对方的疑虑。在主张「素食食谱」的例子中,反驳预测器能主动识别出「烹饪麻烦」「味道不好」等对方反对素食的理由,构建出围绕核心论点的复合关系。
仅仅识别反论点并不能刻画复杂对话中的态度变化,因此,态度预测器进一步评估对手对上述反论点的态度——是坚定认可,还是中立或已被说服?该模块以对话历史和论点为输入,利用 BGE-M3 文本编码器与多层感知机(MLP)分类器,在对话过程中动态估算对方对各个论点的态度倾向,使说服者能有的放矢地展开论证。
实验表明,预测器在 5 点预测上的表现显著优于直接使用大模型推理。例如,在上图的对话中,对方已经认可素食对健康的好处,却提到其并不「享受」素食。这说明其很可能对素食的味道持保留态度,为下一轮的说服侧重点提供了关键线索。
两大预测器的引入使得说服者在作出决策时掌握更为丰富的信息:其不仅能预知对方可能的反驳意见,还能动态评估对方心理状态。这有利于其设计更多样化、有针对性的对话,切实有效地影响对方观点。
然而,LLM 本身未必能有效利用这些信息,为了充分发挥上述模块的优势,ToMAP 采用了强化学习(RL)方法,通过大量对话对模型进行训练。在每轮对话中,模型会根据「说服力得分」进行奖励,该得分衡量的是对方在一轮交互前后态度的变化。为避免重复、冗长、格式不当等问题,训练还引入了格式奖励、重复惩罚、超长惩罚等辅助信号,帮助模型生成通顺、有说服力的对话。
实验分析:运筹帷幄,策略制胜
本文在多种数据集与对手模型上对说服者模型进行了系统测试,评估对手模型在 3 轮对话前后的态度转变。
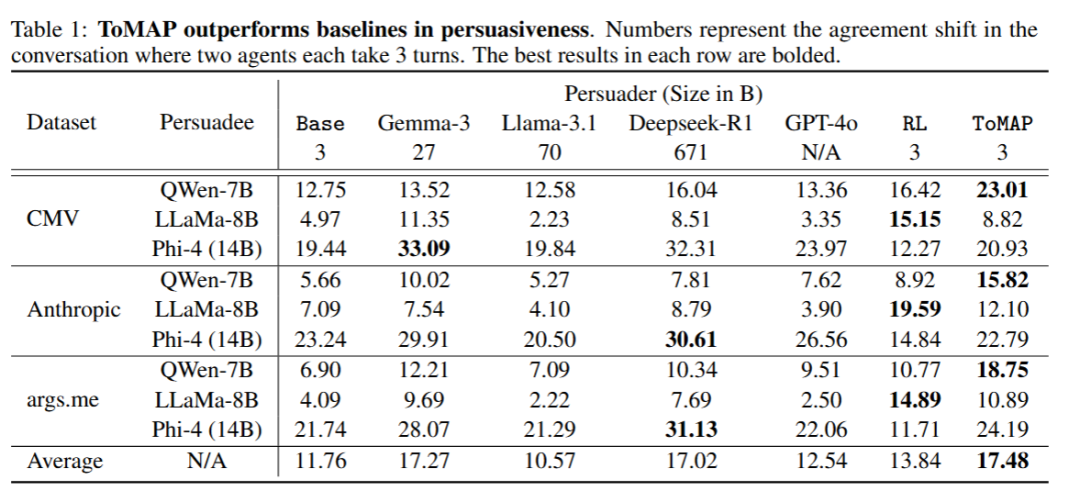
结果显示,基于 Qwen-2.5-3B 的 ToMAP 模型显著优于基线模型和无心智模块的 RL 版本。值得注意的是,尽管 ToMAP 仅使用 3B 参数的小模型,其性能却超越了多种参数规模更大的模型,包括 GPT-4o 与 DeepSeek-R1。这说明即使是规模较小的模型,在合适的训练配方和模块设计的加持下,也能展现出惊人的说服力。
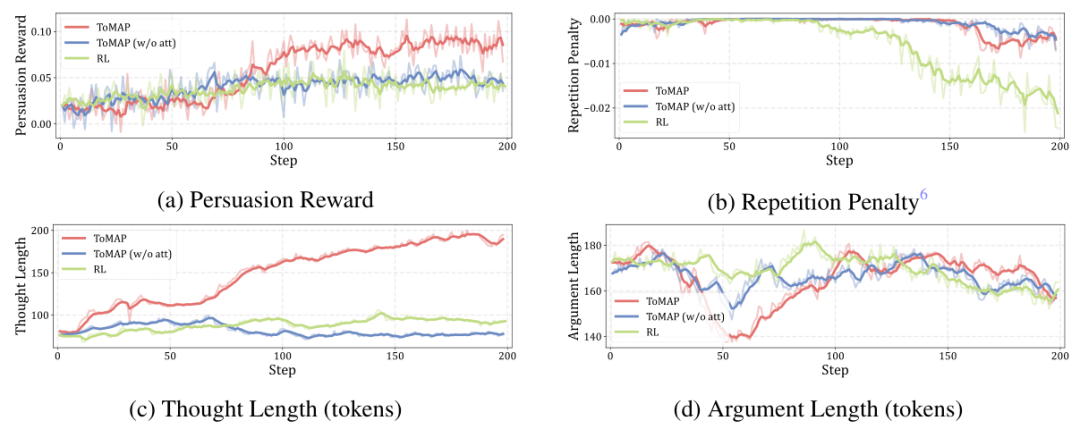
回顾 ToMAP 模型的训练轨迹,我们得以一窥其能力增长背后的原理。从图中可以看出,在说服奖励不断增加的过程中,ToMAP 的重复度惩罚始终保持在较低水平,说明心智模块的信息有效地提高了模型输出的多样性。
另外,在对话长度相对稳定的条件下,ToMAP 的思考长度显著高于基线,表明 RL 赋予了模型深度思考策略的能力,具有不可或缺的作用。另外,ToMAP 更倾向于使用理性和有针对性策略,而非空洞的情绪煽动或权威引用——策略的改进正是其说服力提升的重要原因。
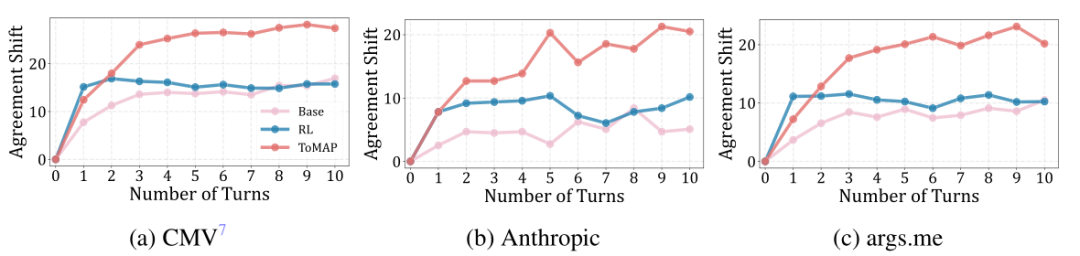
我们还发现,ToMAP 在长对话中依然稳定提升说服力。基准模型和常规 RL 模型在早期几轮对话中效果较好,但随着对话轮次增加,说服力趋于饱和甚至下降;相比之下,ToMAP 在 10 轮对话中依然保持稳定增长,显示出优秀的策略调整能力和论点的多样性。
结语:为 AI 注入「人性认知」的火花
本研究提出了 ToMAP,一种融合心智理论的 AI 说服框架,致力于解决当前大语言模型在说服任务中缺乏对手建模与策略灵活性的问题。论文通过「反论点预测器」模拟人类预判异议的能力,通过「态度预测器」感知对方态度的细微变化,使 AI 在说服过程中更加敏锐与应变。通过精心设计的强化学习机制,促进模型生成内容多样、结构规范、逻辑清晰的高质量论证。
ToMAP 不仅提升了模型的说服能力,在多个数据集和模型组合中显著超越强大基线,更是在大模型「心智建模」方向上迈出的重要一步。通过主动理解对方认知结构与态度倾向,ToMAP 展现出初步的「社会认知」特征,使得语言模型在复杂交互任务中更具人性化与策略性。
总之,ToMAP 不仅是一种有效的说服者训练框架,更是推动 AI 迈向具备「类人思维模式」的创新尝试,为构建可信、灵活的 AI 交流系统提供了坚实基础。
©
(文:机器之心)