


多模态检索是信息理解与获取的关键技术,但跨模态干扰制约着统一多模态表示这一美好愿景的实现。
为此,快手与东北大学联合研发了多模态统一嵌入框架——UNITE。

论文标题:
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
论文链接:
https://arxiv.org/pdf/2505.19650
代码链接:
https://github.com/friedrichor/UNITE
项目链接:
https://friedrichor.github.io/projects/UNITE
模型/数据链接:
https://huggingface.co/collections/friedrichor/unite-682da30c4540abccd3da3a6b
UNITE 的核心目标是构建一个能同时处理文本、图像、视频及其融合模态输入的统一嵌入器。在大模型时代背景下,它从数据策划与训练机制两个关键视角重新定义了统一多模态表示学习的范式。
UNITE 在细粒度检索、指令检索等多个评测中斩获最佳成绩,树立了全新的多模态检索标杆。

模态感知对比学习MAMCL,解决多模态表示混淆难题
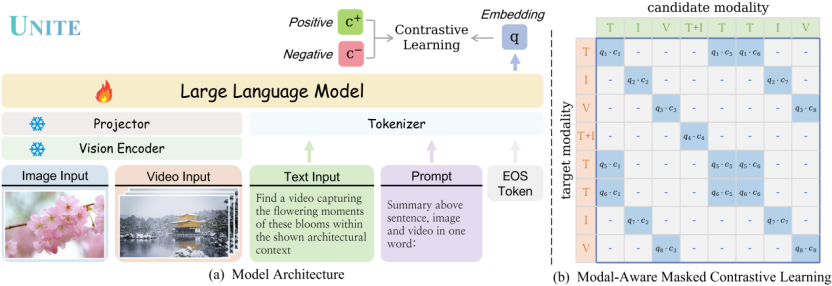
在多模态检索任务中,不同模态(文本、图像、视频)天然存在分布差异。如果在训练时将所有模态混合进行对比学习,会导致表示空间产生语义扭曲或干扰噪声,影响模型对各模态语义的准确建模。
为了解决这一挑战,UNITE 团队提出 Modal-Aware Masked Contrastive Learning(MAMCL),一种能显著缓解跨模态“相互干扰”的对比学习机制。
在传统 InfoNCE 损失下,模型会尝试最大化正样本对之间的相似度,并最小化其与负样本之间的相似度:
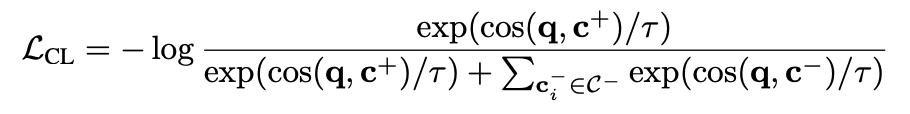
但这种方式不能区分模态组合,例如,一个 query 的正样本为文本模态,但其负样本可能是图像、视频或者其他模态组合。这可能导致模型用图像样本来学文本相似度,产生模态冲突。
核心思想:模态掩码约束只在与当前 query 目标模态一致的负样本中进行对比,避免模态间的错误竞争。
给定一个批次中 N 个 query,每个query 对应一个正样本 和 K 个负样本,构造相似度矩阵:
其中 是第 k 个候选样本, 是温度系数。
接下来引入模态掩码矩阵 ,用于标记候选样本与正样本模态是否一致:
其中 表示提取候选样本的模态标签(例如 text, image, video, text+video)。
然后,构造模态感知掩码相似度矩阵 :
这一步确保在计算损失时,仅考虑模态一致的样本。
最终,MAMCL 损失定义为:
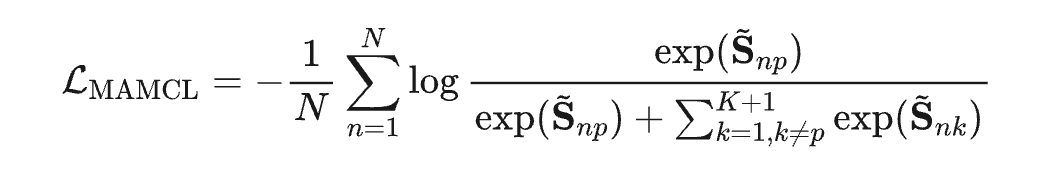
其中 p 是当前 query 对应的正样本索引。

两阶段训练策略,平衡泛化能力与判别能力
UNITE 采用“检索适应 + 指令微调”的两阶段训练方案:
检索适应阶段:使用 text-text、text-image、text-video 等多模态数据训练模型的基本检索能力。同时引入高粒度视频-文本数据,显著提升模型的细粒度表示能力。
指令微调阶段:基于 MMEB、CoVR 等复杂多模态指令任务训练,增强模型的指令遵循能力和扩展性。

从“模态策展”出发,挖掘数据配置的决定性力量
视频-文本数据具备“统一模态”的核心能力
视频-文本对数据在所有配置中表现最为突出:不仅在视频检索任务中遥遥领先,甚至在图文检索任务中也超越了基于图像-文本对训练的版本。
指令类任务更依赖文本主导的数据支撑
尽管视频–文本对数据在一般检索任务中表现出色,但在复杂指令检索任务(如MMEB、CoVR)中,其优势反而不明显。
这类任务需要模型理解长文本或复杂逻辑的指令,研究认为:Text–Text 数据提升了语言理解与逻辑构建能力,而 Text–Image 数据提供精准的视觉语义映射,利于模态对齐。
细粒度Text-Video样本的添加策略影响巨大
直接在第一阶段“检索适应”中融合细粒度视频–文本对,能带来整体性能最优解,相比传统“先对齐后微调”的做法更加有效且高效。

实验结果
细粒度检索
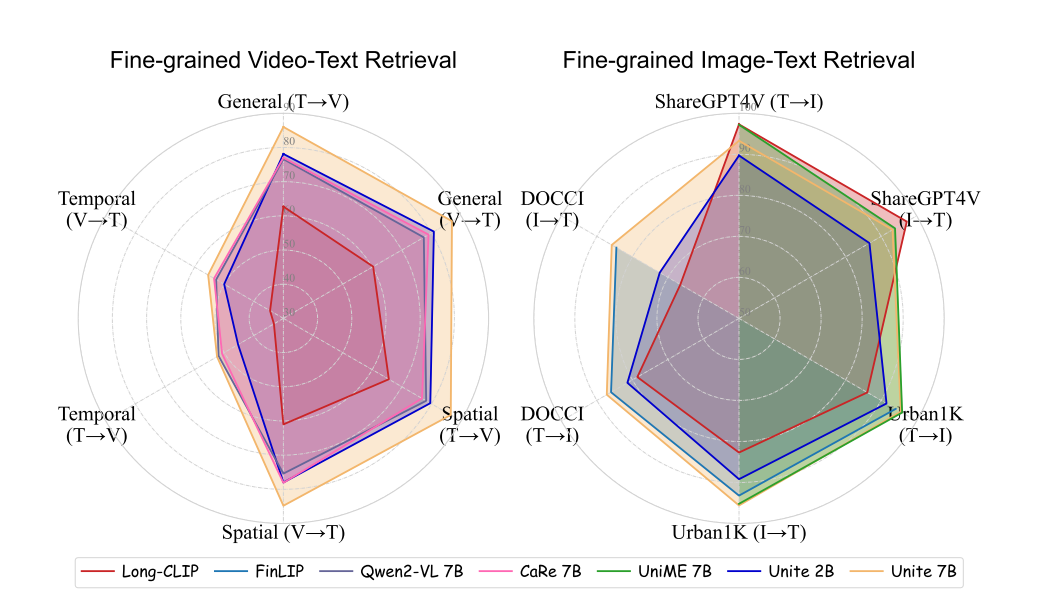
图像–文本检索
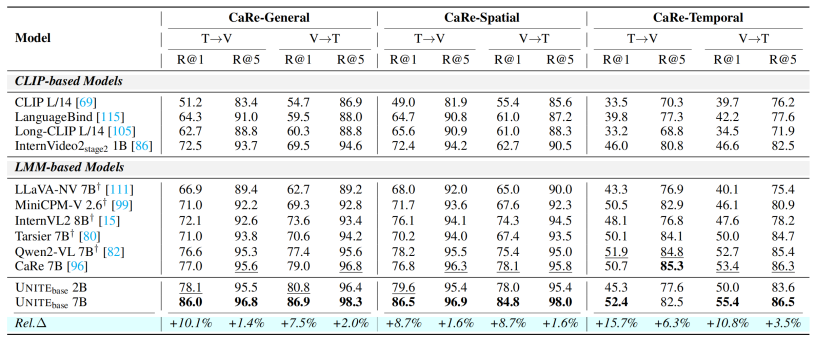
在 ShareGPT4V、Urban1K 和 DOCCI 上,UNITE 显著超越 E5-V 和 VLM2Vec 等模型。
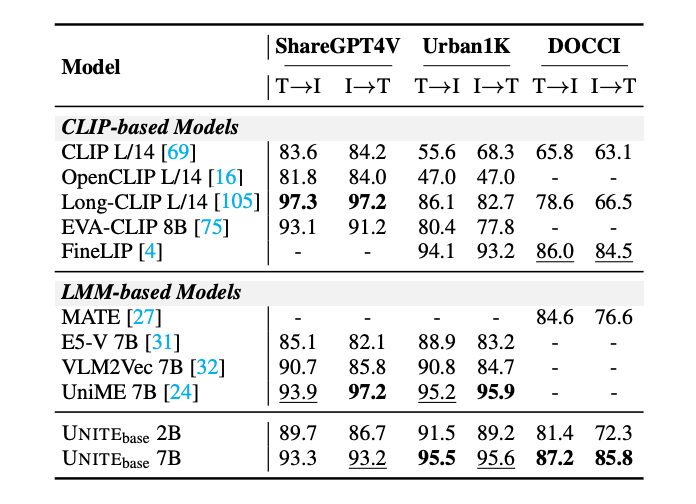
视频–文本检索
在 CaReBench 三个子任务(General / Spatial / Temporal)中,UNITE 的 2B 模型在 General 和 Spatial 超越目前最优性能,7B 模型以显著领先水平刷新当前最好表现。UNITE 7B 在 CaReBench 上分别达到 86.0,86.9,86.5,84.8,52.4,55.4。
指令检索
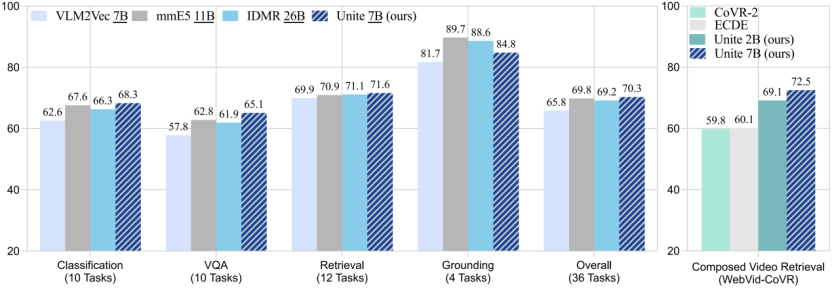
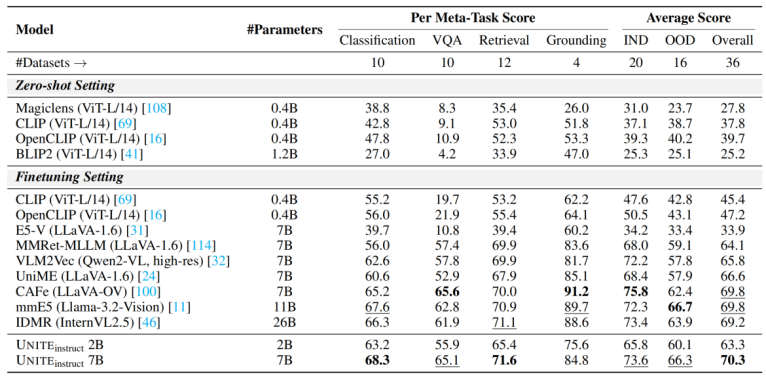
MMEB Benchmark
涵盖分类、VQA、检索、定位四类任务共 36 个数据集,UNITE 7B 达到最优性能 70.3,超越了更大规模的模型 mmE5 11B (69.8) 和 IDMR 26B (69.2)。
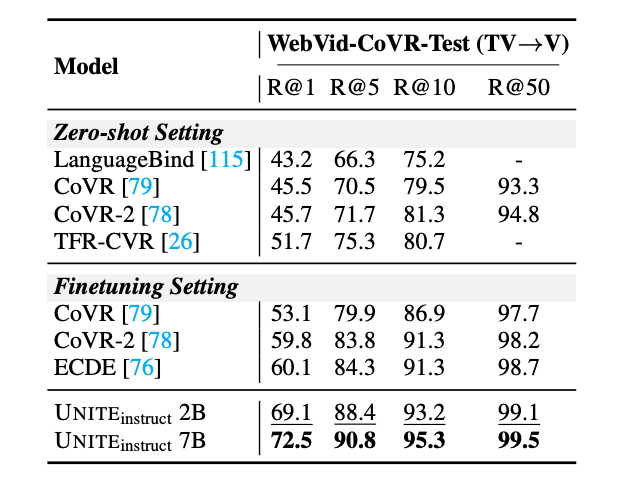
CoVR
在合成视频检索任务上,UNITE 2B 和 UNITE 7B 达到了 69.1 和 72.5,均明显领先于现有 SOTA 模型 (60.1)。
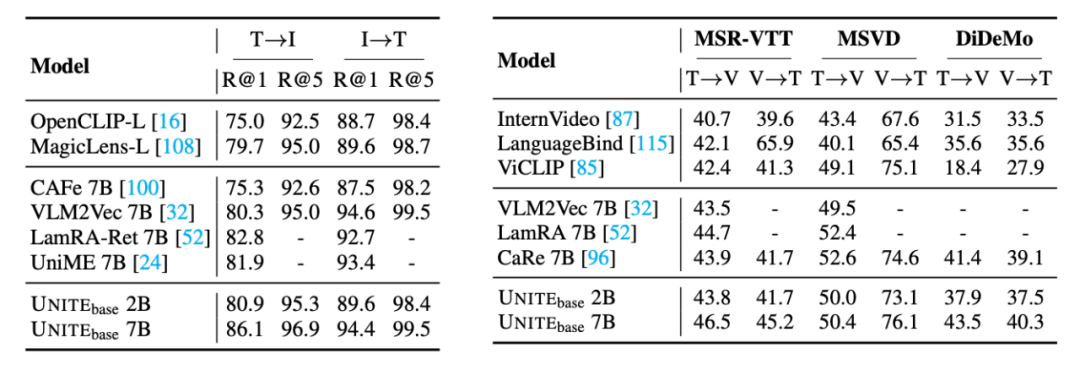
细粒度检索
为验证其通用性,团队还在多个标准跨模态检索任务上进行了评估。在 Flickr30K、MSR-VTT、MSVD、DiDeMo 任务上,展现了良好的通用表征能力。
UNITE检索可视化结果

更多方法和实验细节请参照论文。
(文:PaperWeekly)