


想微调出一个偏好对齐大模型,但是卡不够?
要不考虑加个奖励模型辅助解码,或是上下文学习?好像会变得很慢……
别急!这里有一种低资源实现偏好对齐的新方案——弱到强解码(Weak-to-Strong Decoding,WSD),优雅搞定又快又好的偏好对齐!

论文标题:
Well Begun is Half Done: Low-resource Preference Alignment by Weak-to-Strong Decoding
论文链接:
https://arxiv.org/abs/2506.07434
代码链接:
https://github.com/F2-Song/Weak-to-Strong-Decoding
收录会议:
ACL 2025 Findings
也非常欢迎关注我们在 Alignment 的一系列工作,涵盖数据、后训练、推理等多个视角:
一种多位置 list-wise 对比学习的 LLM 偏好微调算法:
Preference ranking optimization for human alignment (AAAI 2024)
https://ojs.aaai.org/index.php/AAAI/article/view/29865
从数据多样性角度探索其对偏好微调模型的联系和影响:
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment (LREC-COLING 2024)
https://aclanthology.org/2024.lrec-main.1251
一种新颖、好用、高效的上下文偏好学习算法:
Instantly Learning Preference Alignment via In-context DPO (NAACL 2025)
https://aclanthology.org/2025.naacl-long.8/
一种能准确定位事实相关 token 位置、维持全局事实性和多样性平衡的推理算法:
Odysseus Navigates the Sirens’ Song: Dynamic Focus Decoding for Factual and Diverse Open-Ended Text Generation (ACL 2025)
https://arxiv.org/abs/2503.08057

研究动机:低资源和效果好总难两全
无论选 RLHF,DPO 还是 SimPO,利用后训练/微调从一个基座模型得到偏好对齐模型是毫无疑问的最有效最主流的方案。但对小团队或个人开发者来说,微调一个较大尺寸的模型(比如 72B)太费卡了,更不必说如果数据覆盖的领域不全,还会有对齐税的问题。
即便已经有一些低资源偏好对齐的方案,比如用奖励模型辅助解码或是上下文学习实现解码时对齐(Decoding-time Alignment),效果往往也不够令人满意,且部署时有诸多限制,还可能大幅拖慢模型推理效率。
那么,怎么才能又好又快地从基座模型实现偏好对齐呢?

到底咋回事:预实验找出背后困难所在
早在 2023 年 [1] 研究者们就已经发现,预训练得到的基座模型本身就隐含很好的偏好对齐能力,微调则是将之激活。然而,直接令基座模型生成符合偏好的内容还是很难。
这必然令人好奇:从隐含偏好对齐能力到将之体现出来,阻碍这一过程的难点到底是什么,又能否高效解决?我们有了一些猜想。
想象 LLM 正在和用户对话: 在用户发言结束后,LLM 可以有多种回复的方式(迎合、反驳、吐槽等),不同方式也会令用户产生不同程度的偏好,我们所期待的偏好对齐模型则应总能给出最大化偏好的回复。
但对于基座模型,这还容易吗?我们于是做了第一个预实验:
我们收集了一批用户的 query,并分别预设一个符合主流偏好的回复(对齐回复);然后,使用基座模型对每条 query 再采样出 9 条回复(普通回复)。
最后,比较对齐回复和普通回复的质量(通过奖励排名体现),并计算在给定用户 query 后,在已有的 10 条回复中,基座模型直接生成对齐回复的难度(通过困惑度排名体现):
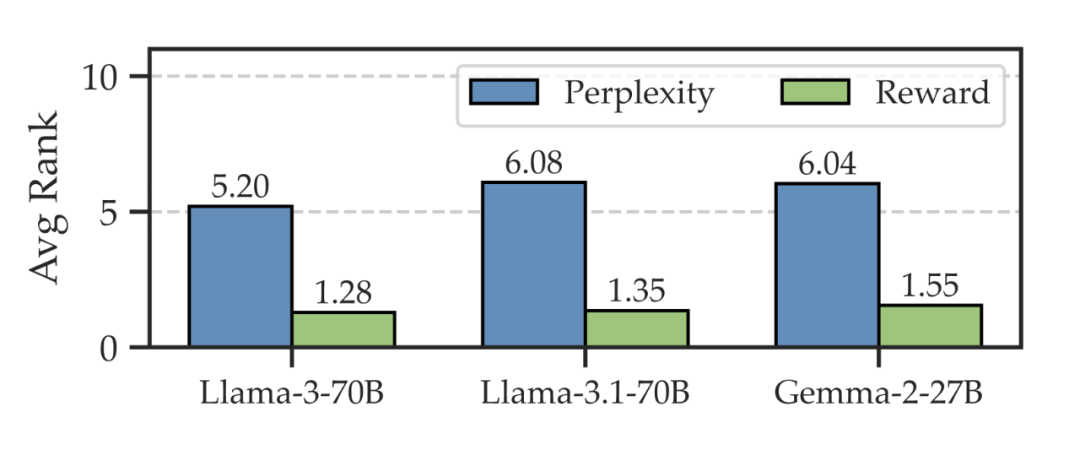
▲ 图1 预实验(a)
可以发现,尽管在偏好方面往往能占据上风(奖励排名靠前),但想让基座模型在众多合理的生成路径中,直接挑中对齐回复返回用户,却相当不容易(困惑度排名居中),这就是上述的难点所在。
既然如此,有没有办法能减弱这一困难?
我们发现,虽然让基座模型从 0 到 1 的给出对齐回复很难,但若能先给一部分开头,模型接续生成后续内容就容易许多,这可以通过计算给定对齐回复的部分开头后,随后 50token 的困惑度变化趋势来验证:给的开头越多,生成后续内容的难度越低,且最陡峭的变化就在一开始的几个 token!
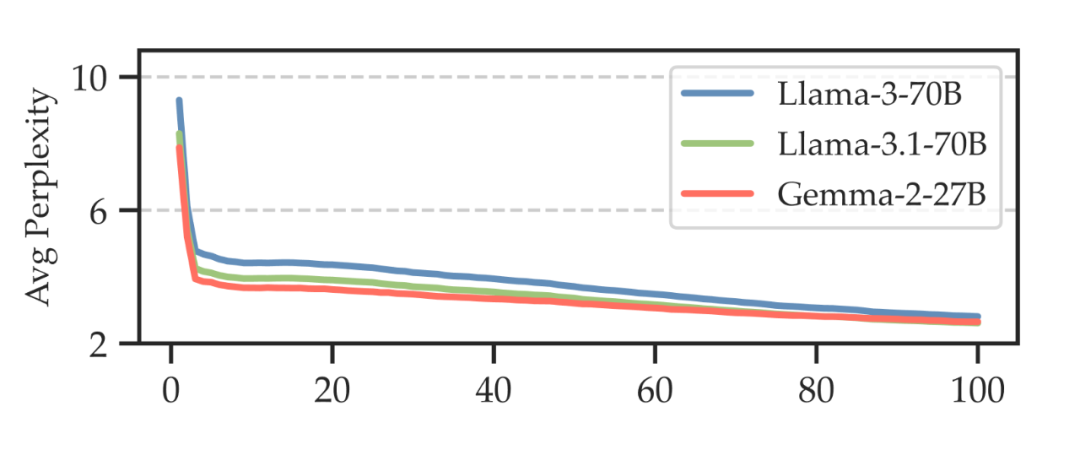
▲ 图2 预实验(b)
看来,好的开始真的是成功的一半:)

弱到强解码:大小模型联合实现偏好对齐
我们提出的弱到强解码 WSD(Weak-to-Strong Decoding)正是基于上述发现运行的!
设想一下,小尺寸语言模型容量较小,往往不足以单独上线使用;但微调它所需的资源也很少!
如果能用这样一个经过对齐微调的小模型 (也称作草稿模型)给出对齐回复的开头 ,再切换到大尺寸基座模型 上继续解码,就等同于得到一个大尺寸的偏好对齐模型 。这可被形式化为:
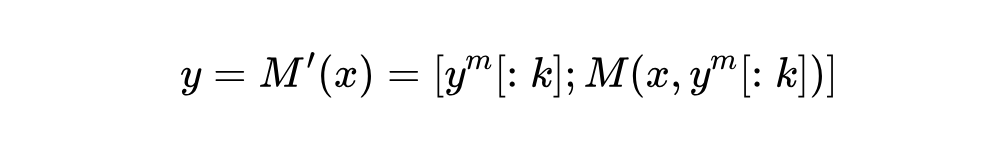
随之出现的问题则是,怎么确定将推理流从草稿模型切换到基座模型的合理位置呢?
因为基座模型本身的自回归解码特征,不断提供草稿模型生成的开头部分也是让基座模型的输出风格像偏好对齐迁移的过程,那么推理流的切换过程也可以由此确定:基座模型不断检查草稿模型输出的内容,并在自身 confidence 到达一定阈值后,使推理流切换到自身继续运行。
这一机制和推测解码(Speculative Decoding)异曲同工,但检查的方向相反,后者仅当超过阈值时才接受草稿模型的内容,而在 WSD 中接受内容则发生在未至阈值前。我们还增加一项窗口平滑使检查更稳健,最终的模型 confidence 由下式得到:
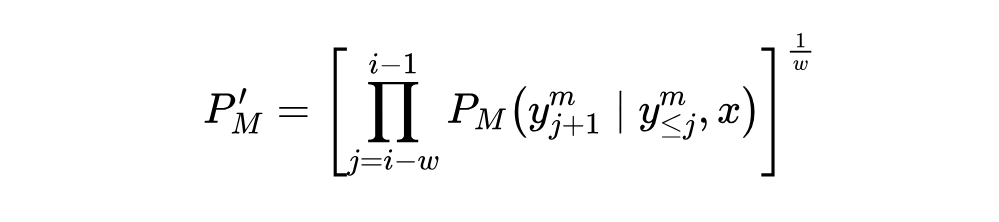
WSD 的运行流程则如下图所示:
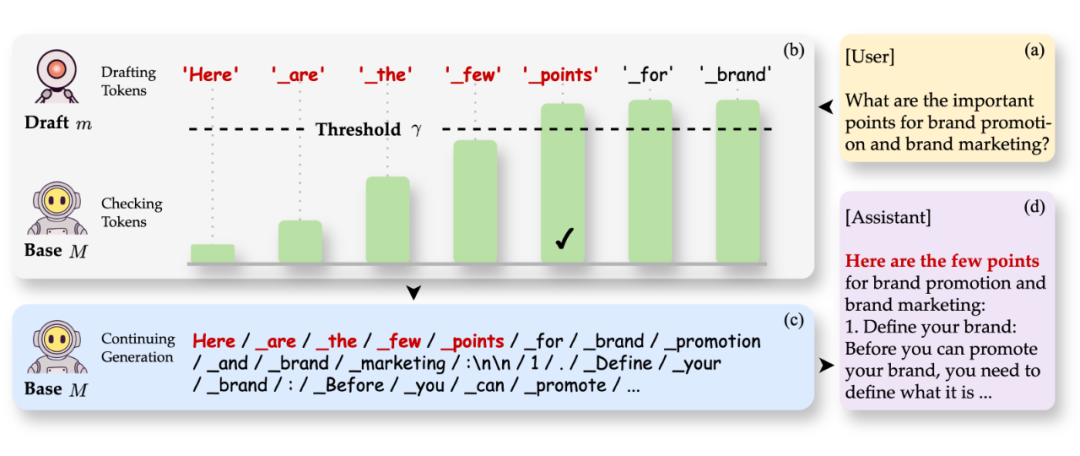
▲ 图3 WSD 过程示意图
我们也另外收集了一批聚焦通用领域的偏好数据,用于训练出一个小尺寸的草稿模型——Pilot-3B,并配合 WSD 使用。

实验表现:效果好、效率高、还没对齐税
我们在 AlpacaEval 2、ArenaHard、HH-RLHF 等 5 个主流偏好对齐基准上进行评测。实验结果显示,所提出的 WSD 方法几乎在所有情况下都取得最佳表现!
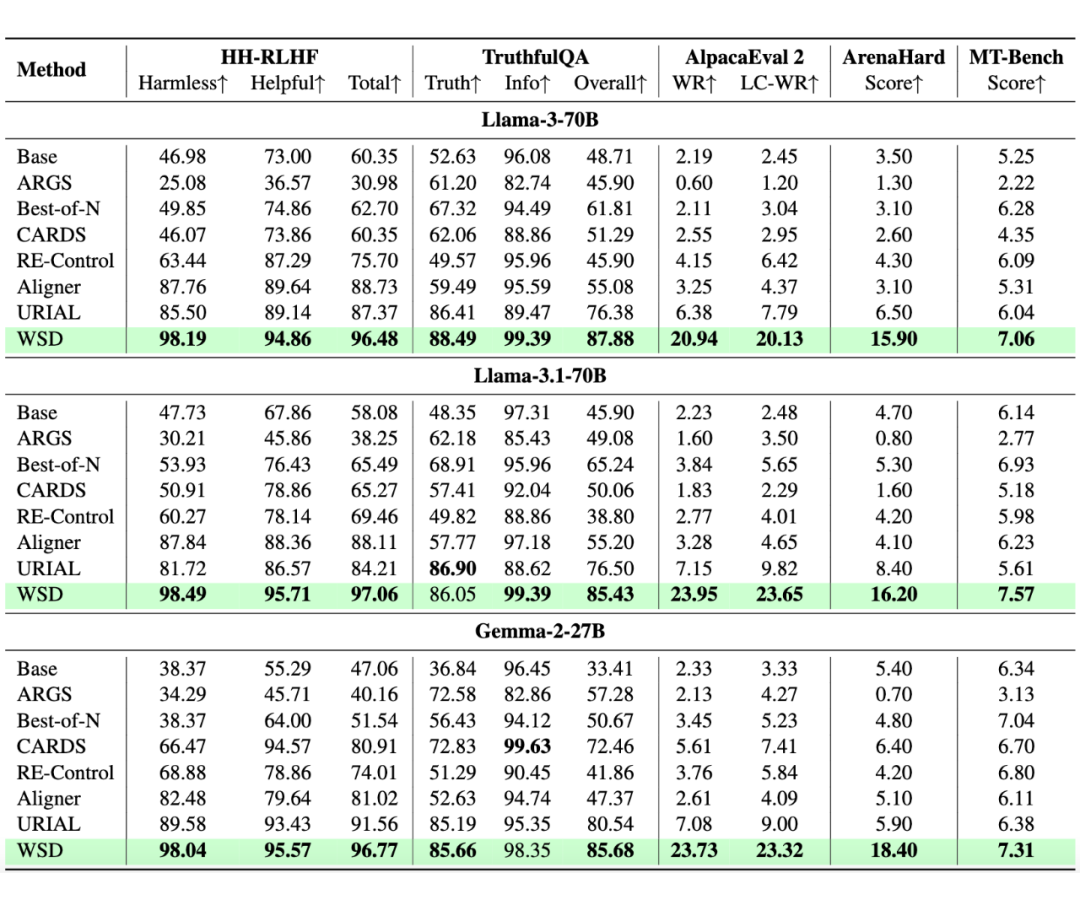
▲ 表1 偏好对齐实验结果
而且,WSD 方法得以保持基座模型在下游任务(数学、代码)的性能,甚至有所提升,这不同于以往微调模型可能带来的对齐税问题(例如,Pilot-3B 相比训练之前的检查点,在这两项任务上的性能即有所下降):
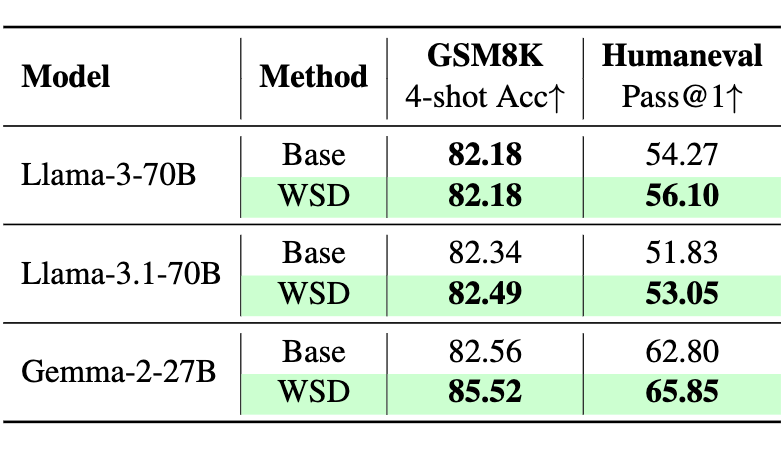
▲ 表2 下游任务实验结果
我们还详细分析了不同设置(如超参数的不同设置、草稿模型选择等)对偏好对齐任务/下游任务性能的影响、推理流切换的特征,以及 WSD 在不同尺寸基座模型上的可扩展性分析。详情敬请查看论文内容。
我们最后以基座模型直接推理的时间开销为基准,并比较了不同方法在效率上的性能,发现 WSD 在这方面也非常有优势:
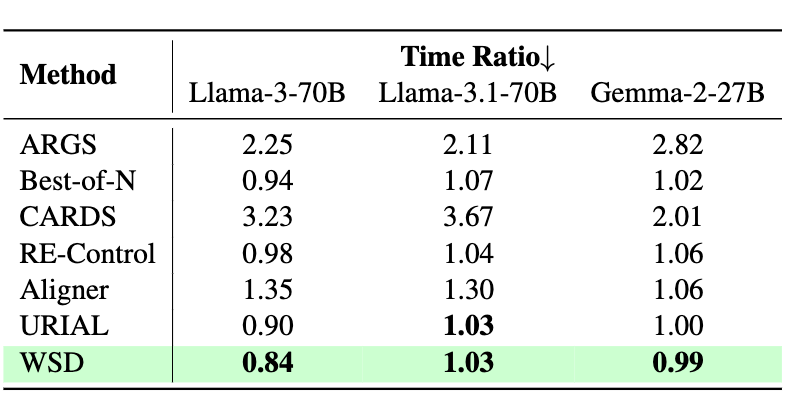
▲ 表3 相对解码时间比率结果

总结与展望
依托于语言模型的自回归特性和方法的精巧设计,WSD 在多个方面都实现了强劲的性能表现。同时,WSD 框架灵活、高效,具备进一步定制和推广的空间。我们也设想了一些可能的情况:
1. 对草稿模型进行定制,以进一步挖掘 WSD 的潜力或满足其他场景的需求;
2. 在推理流切换后,通过推测解码进一步提速;
3. 进一步复杂化切换机制,叠加不同检查条件,比如我们在 [2] 中采用的事实性检查机制。
最后也感谢各位老师、同学、朋友们的关注!十分欢迎对我们的论文/代码仓库 Star、Fork、引用,希望能有更多朋友加入讨论、应用和进一步推广!

(文:PaperWeekly)