

极市导读
对Transformer中的残差连接进行了创新性改造,仅增加极少的参数和计算量,就让28亿参数的模型在多项语言任务上媲美69亿参数的模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
坦白地说,你是不是觉得 Transformer 已经被研究透了?
经过了无数轮的验证与优化,Transformer 的结果看似已经达到了非常稳定的最佳状态,想做出颠覆 Transformer 的结构创新,几乎不太可能了。。
我之前也这么觉得,直到最近看到了一篇 ICML 2025 的论文,没想到又让 Transformer 老树开花了!
这篇论文思路很有意思,没有去卷那些主流的注意力机制,而是独辟蹊径,把“手术刀”对准了 Transformer 内部一个我们习以为常、甚至有些忽略的组件—残差连接(Residual Connection)。
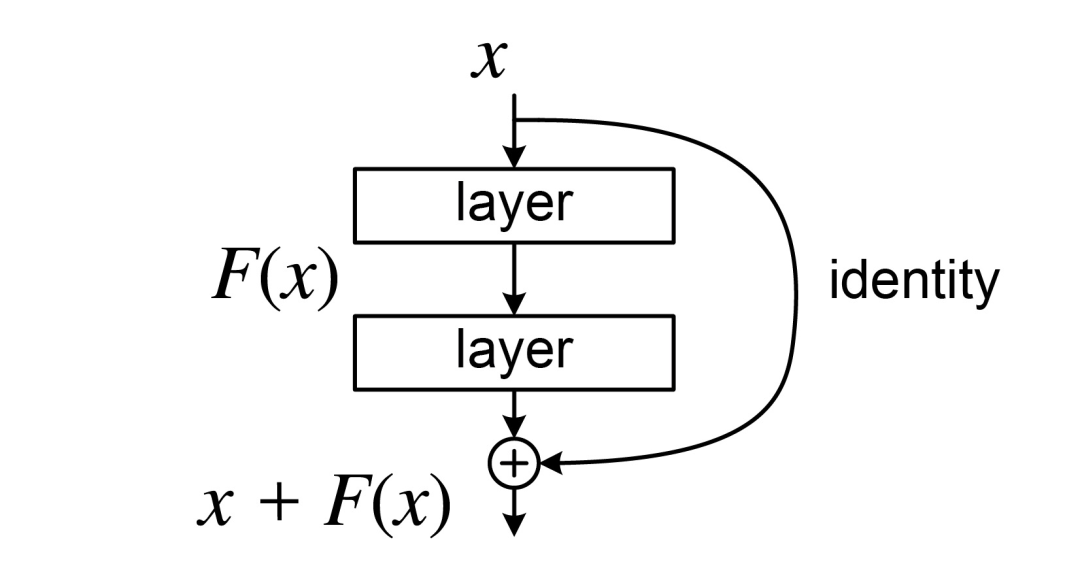
自 2015 年由何恺明团队提出以来,残差连接凭借其有效缓解梯度消失的超能力,几乎是深度网络的标配。没有它,今天的 Transformer 很难稳稳当当地堆到几十层,更别提像 GPT-4 一样动辄上百层了。
不过,任何技术都有它的适用边界。这个曾经的功臣,在今天动辄上百层的深度大模型里,也开始显露出它的瓶颈,成了新的信息“堵塞源头”:
一方面,信息在逐层传递中损耗严重。 随着网络加深,各层特征越来越像(即“表示坍塌”),导致深层网络学不到新东西,白白浪费了参数和算力。
另一方面,单一的“残差流”带宽有限。 Transformer 所有跨层信息都挤在这条道上,当模型需要进行复杂的上下文学习时,这条“单行道”就显得捉襟见肘了。
而这篇 ICML 论文,就是冲着解决这个问题来的。
有意思的是,瞄准这个问题的,还是我们去年的老朋友——彩云科技与北京邮电大学的研究团队。他们设计了一套全新的多路动态密集连接(Multiway Dynamic Dense Connection, MUDD),目标就是给残差连接这个“老基建”来一次高效的改造。
熟悉我的老粉可能还记得,去年我就和大家分享过这个团队在 ICML 2024 上的杰作 DCFormer(哦,所以他们并不是没去卷注意力机制,是在DCFormer里已经卷过了。。)时隔一年,他们依然专注在底层架构创新这个方向上,这次的成果同样扎实。
那么效果如何呢?论文的数据很直接——
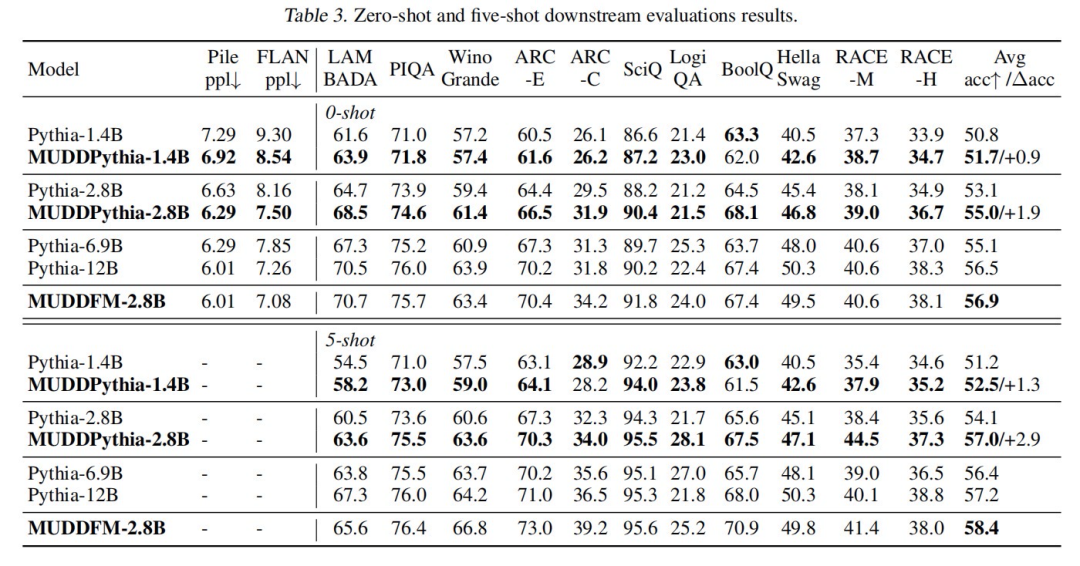
MUDD 方案以极小的代价(参数增加 0.23%,计算量增加 0.4%),就让一个 28 亿参数的 MUDDPythia 模型,在多项语言任务上媲美约 2.4 倍计算量的 Pythia-6.9B。尤其是在需要长距离上下文关联的 5-shot 场景下,它甚至能与约 4.2 倍计算量的 Pythia-12B 模型正面对决。
和上次一样,团队也把论文、代码、模型都开源了,方便大家直接上手。
Github 开源地址:
https://github.com/Caiyun-AI/MUDDFormer
论文链接:
https://arxiv.org/abs/2502.12170HuggingFace模型:
https://huggingface.co/Caiyun-AI/MUDDPythia-1.4B
https://huggingface.co/Caiyun-AI/MUDDPythia-2.8B
https://huggingface.co/Caiyun-AI/MUDDFormer-2.8B
在我看来,相比于烧钱拼硬件,从模型架构的根源上“榨取”性能,是当下最具性价比的方法。话不多说,让我们深入内部,看看 MUDD 究竟是如何“魔改”残差连接,实现性能翻倍的。
MUDD 的核心设计
首先你可以这样理解,传统的残差连接,就像一条单向直路,信息层层打包、不分流,堵车是必然的。而且模型越深,信息传递越差,后面的层都在摸鱼偷懒,也就是常说的“深层瓶颈”。
MUDD 的解决办法相当于把“单向直路”改成了一座“立交桥”,精妙之处在于三个设计:密集化(Dense)、动态化(Dynamic)、多路性(Multiway)。
先放一张 MUDD 的架构图——
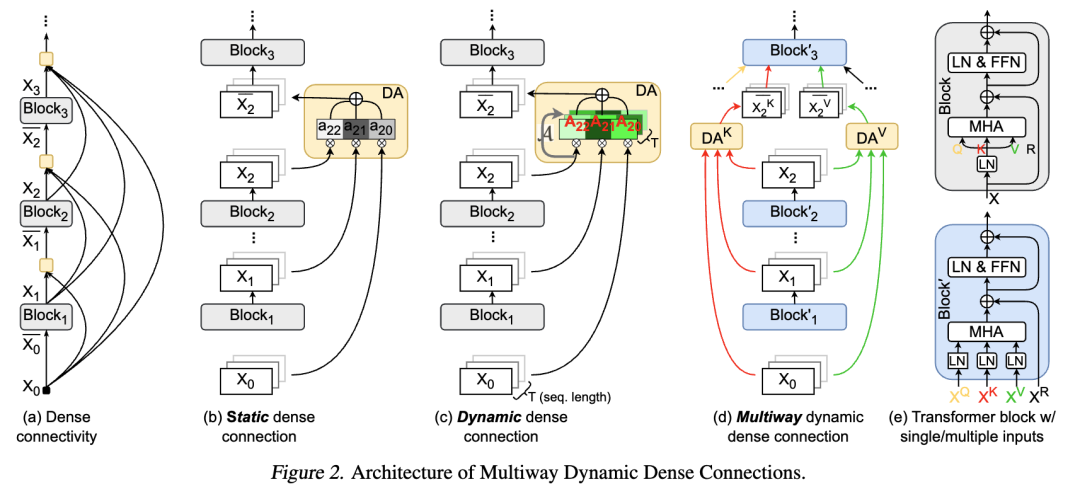
密集化(Dense)
标准残差连接第 i 层只能看到第 i-1层的输出。而 MUDD 允许任何一层“回头看”,直接连接到它前面所有层的输出。
也就是让第 i 层能够直接“空降”到任意一个它之前的层(从 0 到 i−1)去获取纯净的信息,这就彻底打破了逐层传递的限制。
动态化 (Dynamic)
光有桥还不够,还得有智能调度才能跑起快。动态连接,这是 MUDD 区别于以往静态连接的关键。MUDDFormer 的连接权重不是固定的,而是动态生成的。不是所有历史信息都无脑涌入当前层。相反,它引入了一个“智能导航系统”。
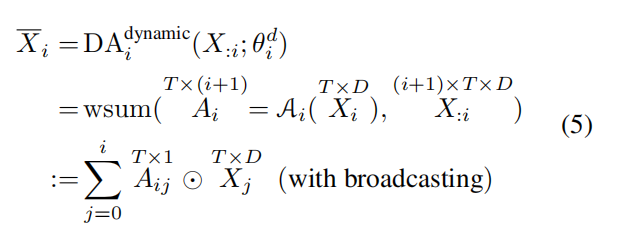
模型在处理每个 token 时,会根据当前的语境(hidden state),动态地计算出每一条来自历史层的信息通道应该被赋予多大的权重。

这种“按需连接”的能力,让信息流动变得极其灵活和高效。
多路性 (Multiway)
这是我觉得这篇论文里最创新的想法!MUDD 的作者们认为:
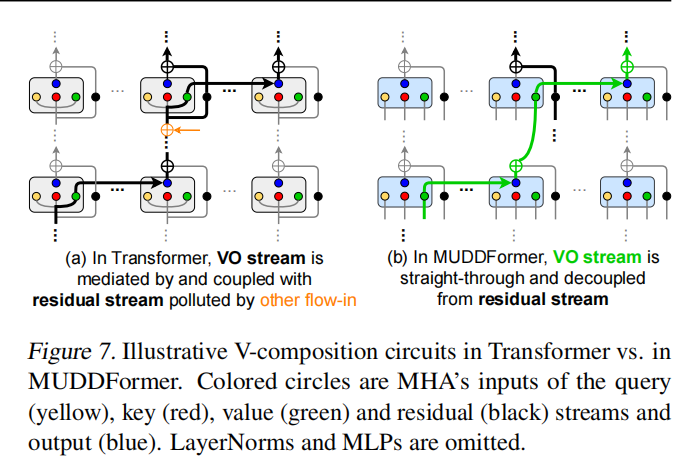
在 Transformer 的一个 Block 里,Q(查询)、K(键)、V(值)和 R(残差输入)虽然都来自上一层,但它们的使命完全不同。把它们混在一个车道里运输,简直是资源浪费。
于是,MUDD 为它们设立了独立的专属 VIP 通道。为了让 Transformer 块内的不同输入流(Q, K, V, R)独立聚合,实现更精细的跨层通信,MUDD 将下一层 Transformer 块的输入解耦为独立的 Q、K、V、R 四个流,并为每个流设计了独立模块。
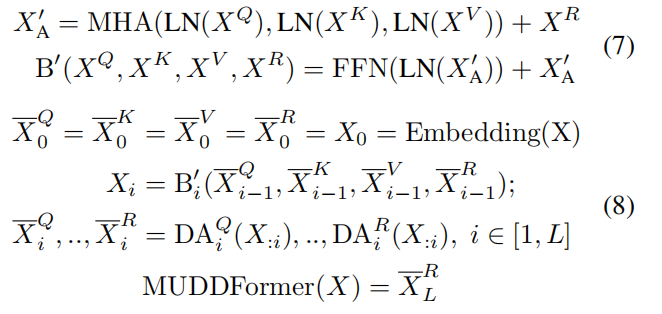
这意味着,在生成下一层的 Query 输入时,会使用专门的 DA_Q 模块独立聚合前层信息,而生成 Value 输入时,则使用 DA_V 模块进行不同的聚合。
不同于传统的层内多头注意力,MUDD 的设计核心是一种深度方向的多头注意力机制。它通过允许信息在不同层之间进行更丰富的 Q/K/V 交互,极大地增加了层间的通信带宽。
这种设计使得网络中的每个流(例如,负责传输信息内容的 V 流,以及负责匹配和对齐的 Q/K 流)能够根据其特定功能,独立且动态地从网络的历史/先前层中聚合所需的历史信息。
效果如何?
方法论讲的再好,也得看实际效果。MUDD 论文里给了详细的实验分析,可以说把“性价比”打在了公屏上。
这恐怕是大家最关心的。
在大规模预训练(300B tokens)中,MUDDFormer 仅用 28 亿参数,就在多项指标上达到了 69 亿参数模型(2.4 倍参数量)的水平。在更考验上下文理解能力的五样本学习任务上,它甚至能硬刚 120 亿模型(4.2 倍参数量)的水平。
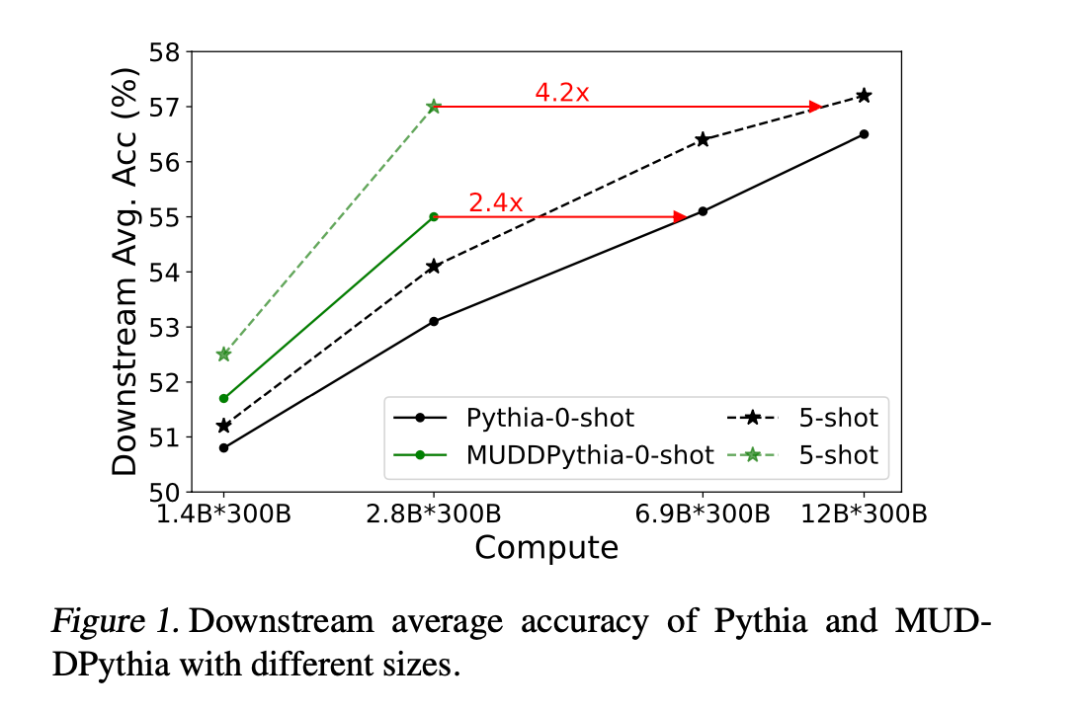
实验显示,MUDDFormer 从预训练开始,损失就显著低于所有基线模型,换句话说,相同的 loss 所需算力更少。
比如图 3,我简单解释一下:横轴 Compute 代表训练总算力预算,写成 “模型参数量 × 预训练 token 数”(例如 405 M × 7 B)。向右代表花更多算力。纵轴 Loss 越低越好。
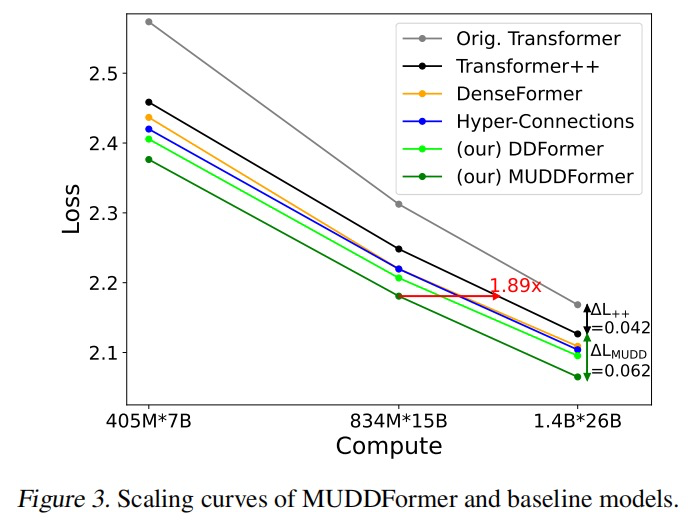
绿色实线(MUDDFormer)在所有算力点都低于其它模型,说明相同算力下 Loss 最小。红色箭头表示:要达到 MUDDFormer 的 Loss,普通 Transformer++ 需要 ≈1.89 × 的算力才行。
其次,改善了 Transformer++ 模型在增加层数后收益递减的问题。
传统 Transformer 越深,收益越低的“边际递减”问题,在 MUDD 这里得到了有效缓解。MUDDFormer 即使在更深的配置下,依然能保持强劲的性能增长。
把深度加倍后(虚线 vs 实线),MUDDFormer 的 Loss 下降幅度(虚线之间的垂直距离)明显大于 Transformer++。说明深层仍能有效学习。
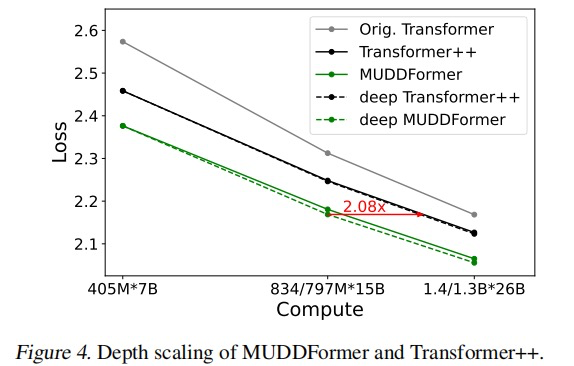
红箭头表示达到 MUDD 深模型的损失水平,Transformer++ 需再多花 ≈2.08 × 算力。
再看下它多个任务上的表现,能够以小搏大,匹敌甚至超越更大模型。
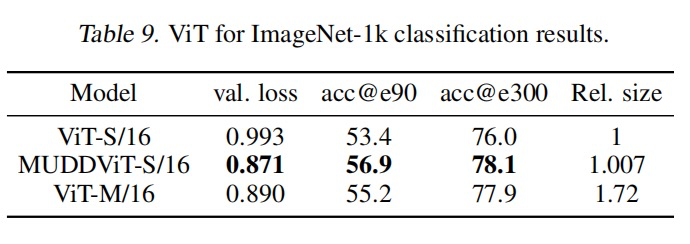
把它用到 Vision Transformer(ViT)上做图像分类,效果同样显著。
不止如此,和现在特别火的混合专家(MoE)架构结合,还能产生 1+1>2 的效果。MUDD 与 MoE 模型虽然都利用动态权重,但作用机制不同(跨层聚合 vs. 层内专家选择),二者属于正交且互补的技术。
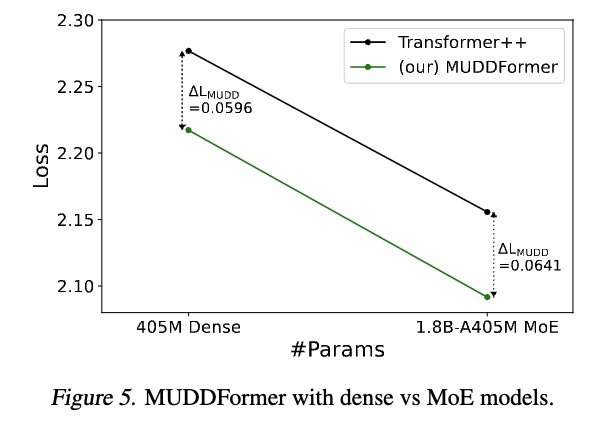
如以下图 5 展示的实验结果,MUDD 连接对 MoE 模型同样有效,并在应用时带来了额外的性能增益,预示着 MUDD 连接能够与 MoE 等先进架构相结合,进一步提升未来基础模型的综合性能。
总之,仅增加约 0.23% 的参数和 0.4% 的计算量,却在多种规模(405M–2.8B)和多种架构(Decoder-only/ViT)上稳定超越原 Transformer,需要的额外资源几乎可以忽略不计。
结语
这次 MUDDFormer 与研究团队之前的 DCFormer 工作一脉相承,DCFormer 侧重点在于序列长度的信息传递效率问题,而 MUDDFormer 则专注于优化模型深度方向的信息交互效率。
看似基础、底层的架构创新,在当前这个时候依旧有效。优秀的模型架构是撬动 AI 能力和效率的关键杠杆。
PS:MUDDFormer 工作的的所有代码、预训练模型和详细的实验设置完全开源, 不仅是一个即插即用的新工具,也是一种值得学习的创新思路。
GitHub:
https://github.com/Caiyun-AI/MUDDFormer
(文:极市干货)