
速递|DeepSeek联手清华新模型GRM开源,算力降低性能反升

DeepSeek与清华大学合作开发自我进化的AI模型,利用强化学习提升模型效率。该方法在多项基准测试中超越现有方法和模型,展示了更少计算资源下的优化性能,并计划以开源形式发布新模型。
DeepSeek与清华大学合作开发自我进化的AI模型,利用强化学习提升模型效率。该方法在多项基准测试中超越现有方法和模型,展示了更少计算资源下的优化性能,并计划以开源形式发布新模型。

由于特朗普关税政策导致科技股暴跌,初创企业和风险投资公司转向AI驱动的成本优化与硬件囤积策略。Hustle Fund联合创始人建议谨慎支出并提前购买硬件。市场不确定性加速了人工智能初创企业的衰退。

著名 AI 大牛安德烈·卡帕西的文章指出大语言模型(LLM)颠覆了技术普及的传统模式,普通人成为最早受益者。他分析了“万金油”与“专家团”、简单粗暴与精耕细作、灵活小船与笨重大船的不同,解释了为何 LLM 在企业和政府中的应用相对缓慢。
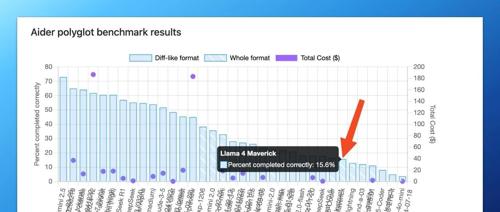
Meta 新发布的Llama 4因基准测试成绩亮眼但遭用户质疑,称其实际表现不佳。Meta 因疑似数据污染技术而受到批评。此外,Meta的Llama 4 Maverick模型在多个任务如前端开发、逻辑推理等方面的表现也不尽人意。

反思、思考,并随着时间推移不断优化的能力。
对我而言,这才是真正的
Agency
。在
B2B
领域

Glean,一家为企业开发搜索聊天机器人的公司,可能筹集数亿美元的新融资。其潜在估值约为70亿美元,主要客户包括三星电子、Rivian和爱立信。该公司收入在过去一年增长约三倍,预计到2026年达到2.35亿美元的ARR。

一篇来自‘一亩三分地’论坛的帖子爆料称Meta的新大模型Llama 4训练效果未达开源SOTA基准,公司采取混入测试集数据以满足目标的做法引发争议。此外,TechCrunch质疑Meta在LM Arena排行榜上提交的版本可能与公开版不同,并认为这种行为可能误导开发者。

作能力的 AI 智能体,基于自研
GLM-Z1-Air
推理模型,性能媲美
DeepSeek-R1

