
日期: 2025 年 3 月 27 日

英伟达要买下贾扬清公司LeptonAI!老黄花数亿美元加码算力租赁

Lepton AI宣布即将被英伟达收购,专注于为企业提供高效的AI应用平台。公司由阿里巴巴前VP贾扬清等人创立,致力于通过简单命令实现AI模型的部署。
爱诗科技商业化负责人孙伟哲:快是技术,慢是艺术——PixVerse视频生成的速度与浪漫

中国生成式AI大会在北京举办,以”大拐点 新征程”为主题,邀请多位重量级嘉宾分享生成式AI领域的重大进展和变革,涵盖应用论坛、大模型峰会及闭门研讨会等内容。

OpenAI最新官宣:Agent SDK支持MCP协议

OpenAI 开始支持 MCP,这标志着开发 Agent 成本降低和用户体验提升。MCP 是 Anthropic 推出的开放协议,旨在简化大语言模型与外部数据源及工具的集成。
阿里开源Qwen2.5-Omni-7B:首个端到端全模态大模型、看听说写打通

通义千问发布Qwen2.5-Omni-7B全模态大模型,支持文本、图像、音频和视频等多种输入形式,提出Thinker-Talker架构及TMRoPE位置编码技术。在多模态任务中表现出色,支持实时交互与语音指令跟随。
长视频理解新突破!Mamba混合架构让显存消耗腰斩,处理10万视频token不费力
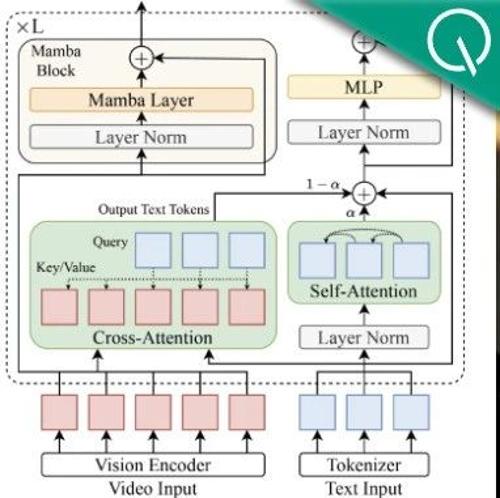
滑铁卢大学陈文虎团队提出Mamba-Transformer混合模型Vamba,通过改进模型架构设计提升视频理解效率。相比传统方法,Vamba在同等硬件条件下可处理的视频帧数提升4倍,内存消耗降低50%以上,并实现单步训练速度翻倍。

外媒:英伟达将收购贾扬清创业公司Lepton AI,交易价值数亿美元

英伟达即将达成收购 Lepton AI 的交易,Lepton AI 是一家为 AI 时代构建新型基础设施的公司。贾扬清等人创立,专注于简化大模型部署和管理。