
超越对话:MCP 如何构建下一代 AI Agent

本文深入分析了模型上下文协议 (MCP) 的发展动态,指出其作为关键连接标准的重要性,并探讨了它如何推动AI Agent从单一模型向集成系统演进,赋能AI深入现实工作流,并促进相关开发者生态的成熟。
本文深入分析了模型上下文协议 (MCP) 的发展动态,指出其作为关键连接标准的重要性,并探讨了它如何推动AI Agent从单一模型向集成系统演进,赋能AI深入现实工作流,并促进相关开发者生态的成熟。

本文介绍了昆仑万维的Mureka O1 AI音乐平台,其引入了CoT思维链技术提升音乐品质。作者分享了自己的AI音乐创作经验,并详细讲解了如何使用该平台生成歌曲的过程和技巧。
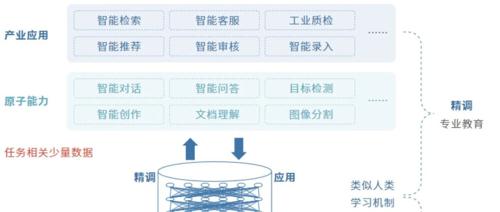
文章介绍了大模型分类的复杂性及用户和技术两个角度的大模型应用,并强调了实际需求的重要性,建议根据任务需求选择合适的模型,同时指出当前大模型评估标准缺失的问题,鼓励多尝试和研究。
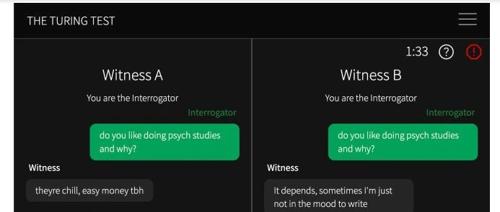
加州大学圣迭戈分校的研究学者首次提供了人工系统通过标准三方图灵测试的实证证据。GPT-4.5和LLaMa-3.1在相同提示下被判断为人类的比例分别为73%和56%,显著高于真实人类参与者被选中的比例,表明这些系统已经非常接近人类智能水平。

蚂蚁与清华大学联合推出的AReaL开源强化学习框架发布里程碑版本,提供详细的教程和高性能的SGLang框架集成,大幅提升训练速度,并在数学推理能力上达到同尺寸模型的SOTA水平。

ChatGPT 4o上线吉卜力风格功能后不久因版权问题下线,引出开源AI绘画工具门槛的重要性。作者分享了一个使用ComfyUI制作的一键转吉卜力风格的工作流,并提供了所需模型和安装路径。

OpenAI发布的PaperBench测评基准测试了AI复现顶级学术论文的能力,Claude 3.5 Sonnet在20篇ICML论文测试中的平均得分为21%,超过了一半的顶会论文。该基准不仅严苛要求,还开源代码鼓励研究者参与。此外,斯坦福大学的研究表明LLM能提出有创意的新想法,但其可行性有待提升。OpenAI研究员Jason Wei认为AI科学创新将有两种风格:专注特定问题或训练通用型AI系统。未来AI在科研领域的潜力巨大,包括辅助和引领重大突破。


