
强化学习
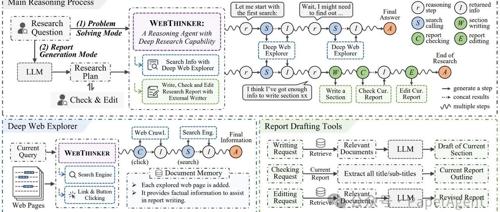
绝对零监督Absolute Zero:类AlphaZero自博弈赋能大模型推理,全新零数据训练范式问世

rning with Verifiable Rewards(RLVR)范式下涌现出一批
「Zero
OpenAI研究员Jason Wei发起的AI灵魂十问,你怎么选?

OpenAI研究员Jason Wei发起了一场关于AI技术偏好的讨论,通过十个问题引发网友热烈回应。网友们的答案揭示了不同AI从业者的观点和偏好。





只要9美元!LoRA+强化学习,DeepSeek 1.5B推理性能暴涨20%

南加州大学团队利用LoRA+强化学习在AIME 24数学基准测试上实现超过20%的性能提升,成本仅为9美元。研究发现LoRA模型中减少计算反而能带来更好的性能。
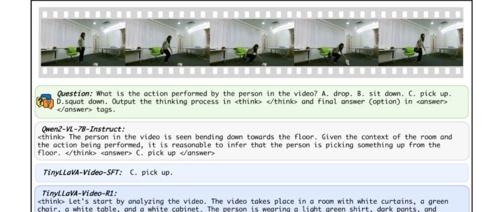
3.6B参数逆袭7B巨头!北航开源TinyLLaVA-Video-R1:小模型竟靠强化学习吊打大模型?
北京航空航天大学推出的小尺寸视频推理模型TinyLLaVA-Video-R1通过强化学习显著提升了小规模模型的性能,并开源了权重、代码和训练数据。该模型参数量不超过4B,在多个基准测试中表现优异,具备强大的多模态理解能力和可解释性生成能力。