
大模型终于能预测未来了?伊利诺伊黑科技让AI化身“时间预言家”

伊利诺伊大学香槟分校开发的Time-R1模型通过三阶段强化学习训练提升了语言模型的时间推理能力,包括时间戳推断、事件排序和生成合理未来场景等任务。该模型在多个时间推理任务中表现优异,并开源了代码和数据集以促进研究和技术发展。
伊利诺伊大学香槟分校开发的Time-R1模型通过三阶段强化学习训练提升了语言模型的时间推理能力,包括时间戳推断、事件排序和生成合理未来场景等任务。该模型在多个时间推理任务中表现优异,并开源了代码和数据集以促进研究和技术发展。

文章总结了强化学习(RL)在大型语言模型(LLM)中的应用,指出传统监督学习的局限性,并阐述了RL作为一种新的扩展方法如何通过弱监督信号和正/负权重机制,解决数据生成性和训练效率问题。

AICon 大会即将召开,韩艾将分享基于强化学习的异构多智能体联合进化算法。大会涵盖多模态应用、推理性能优化等多个专题论坛,为 AI 技术开发者提供前沿洞察与实践经验。
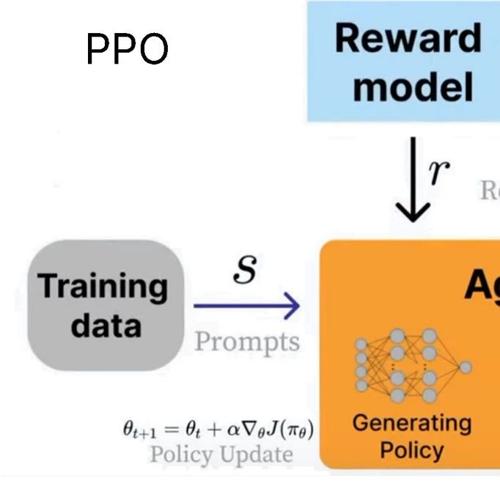
Unsloth发布了关于大模型强化学习的完整指南,涵盖目标、关键作用及在AI代理中的应用等内容,并提供了GRPO、RLHF、DPO和奖励函数的相关信息。
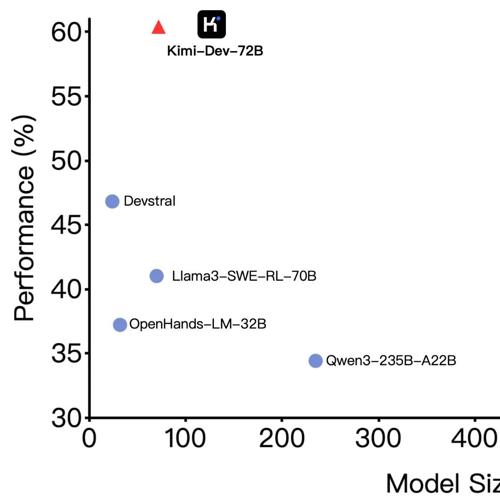
Kimi-Dev 是一款强大的开源编程LLM,性能超越其他开源模型,在SWE-bench Verified上达到60.4%;支持本地部署和Hugging Face使用,并通过大规模强化学习优化解决方案的准确性和鲁棒性。




