太卷了!阿里千问送新年大礼:Qwen2.5-VL视觉模型免费体验,解锁无限视觉智能

阿里千问家族迎来了新的旗舰级成员Qwen2.5-VL,重点提升视觉理解、智能体能力和长视频理解能力。亮点包括精准图像识别、智能交互与任务完成、长时间视频内容理解和结构化数据输出等。
阿里千问家族迎来了新的旗舰级成员Qwen2.5-VL,重点提升视觉理解、智能体能力和长视频理解能力。亮点包括精准图像识别、智能交互与任务完成、长时间视频内容理解和结构化数据输出等。

字节发布UI-TARS视觉语言模型,能像人一样操控电脑界面,并在多项测试中击败GPT-4等对手。它具备感知、推理及行动能力,支持点击、输入等多种操作。UI-TARS通过SFT和DPO训练,在多个GUI代理基准测试中达到最佳成绩,还开源了桌面版应用。

《大语言模型基础与前沿》介绍了大语言模型的基础和前沿知识,并探讨了其方法、应用场景及对环境的影响。内容全面且系统性强,适合高年级本科生和研究生、博士后研究人员等阅读。

英伟达联合清华大学、麻省理工大学推出Sana绘画模型,相比传统扩散模型在模型大小和推理速度方面有显著提升。其优势在于深度压缩自动编码器和高效的线性DiT模块。
Vision Parse 是一款智能工具,利用先进的视觉语言模型能精准识别并提取文本、表格和公式,保留文档格式和层次结构,具备扫描文档智能处理、高级格式完整保留、多模型协同支持及私有化部署选项四大亮点。

本文介绍了DeepSeek-VL2、Leffa、小红书笔记生成器、Gemini 英语口语助手和PDF Mind Map Maker等创新技术与应用。它们涵盖多模态视觉-语言模型、可控人物图像生成框架、笔记生成工具及AI英语口语辅助等多个领域,提供高效便捷的功能以提升用户在不同场景下的工作效率和体验质量。
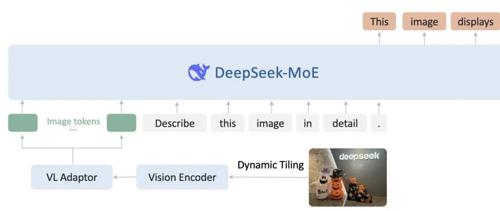
DeepSeek-VL2是先进的大型混合专家视觉-语言模型系列,显著改进了其前身DeepSeek-VL,在包括视觉问题回答、光学字符识别、文档/表格/图表理解以及视觉定位等多种任务上表现出卓越的能力。