
想纠正LMM犯错?没用!NUS华人团队:最强o1反馈修正率不到50%

新加坡国立大学华人团队提出InterFeedback框架,评估大规模多模态模型在人类反馈下的表现,结果显示最先进的LMM通过人类反馈纠正结果的比例不到50%。
新加坡国立大学华人团队提出InterFeedback框架,评估大规模多模态模型在人类反馈下的表现,结果显示最先进的LMM通过人类反馈纠正结果的比例不到50%。

AI语音在2024年下半年迎来爆发式增长。模型开发进步简化了基础设施,使语音Agent延迟更低、性能更优。GPT-4o API价格大幅下调至$2.50/Million tokens。语音Agent市场渗透率上升,集成到更多产品中。早期应用主要集中在金融服务、BPO、保险、政府和医疗等领域。
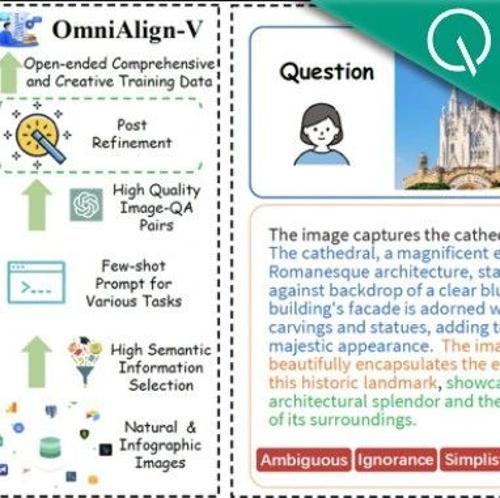
上海交大团队通过实验发现多模态数据对语言质量的影响有限,提出OmniAlign-V数据构建Pipeline,包含高质量的多模态数据,并在多个基准测试中验证了其有效性。

斯坦福大学OctoTools框架通过标准化工具卡、规划器和执行器,无需训练即可显著提高LLMs处理复杂任务的能力,比其他方法平均准确率高出9.3%。
OpenAI 发布了新工具和 API,旨在简化构建 AI Agents 的过程,让开发者能更容易创建执行任务的智能体。这些新工具包括 Responses API、Web 搜索工具、文件搜索工具以及计算机使用工具等。

OmniParser V2通过更大规模的数据集训练,提升了对小图标检测的准确率和推理速度。其与LLM结合后在多个基准测试中表现优异,平均准确率达到39.6%。

ViDoRAG 是一款专注于视觉文档的开源 RAG 系统,由阿里巴巴通义实验室联合中科大、上海交大推出。它通过多模态混合检索和多智能体迭代推理解决传统 RAG 方法在处理复杂视觉文档时的信息关联性不足和推理能力有限等问题。


