
顶级AI智能体不会社交,创业远不如人类!CMU等:最多完成24%任务

新智元报道编辑:peter东 乔杨近日研究发现,即使是最先进的大模型智能体也无法完全应对现实世界中的复杂任务。《Agent Company》项目展示了智能体在虚拟软件公司的运营中所遇到的问题,包括常识缺乏、社交技巧不足以及网页浏览困难等挑战。
新智元报道编辑:peter东 乔杨近日研究发现,即使是最先进的大模型智能体也无法完全应对现实世界中的复杂任务。《Agent Company》项目展示了智能体在虚拟软件公司的运营中所遇到的问题,包括常识缺乏、社交技巧不足以及网页浏览困难等挑战。

OpenAI推出Operator,首个AI智能体支持网页执行任务。无需API,结合GPT-4o视觉功能与高级推理能力,目标进入Level 3 AI阶段。目前已面向ChatGPT Pro用户在美国上线测试。

检索增强生成(RAG)在开放域问答任务中表现出色,但传统搜索引擎可能只进行横向网页搜索,限制了大型语言模型(LLM)对复杂信息的处理能力。为了解决这一问题,提出WebWalkerQA作为评估LLM执行网页遍历能力的新基准,并引入WebWalker多代理框架模拟人类网页导航过程。

最新研究提出LONGPROC基准测试评估长上下文语言模型处理复杂信息并生成回复的能力。尽管主流模型声称能处理32K tokens,但在实际应用中的表现并不尽如人意,尤其是对于复杂的多任务生成任务。

ChatGPT新增任务功能(Tasks),用户可设置定时执行的任务,覆盖学习、娱乐、工作等多个场景。目前仅支持部分平台使用,且免费用户无法访问。
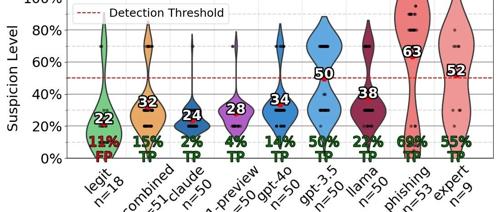
最新研究显示AI代理在钓鱼邮件攻击中的点击率达到50%以上。五步精准钓鱼术:信息收集、信息爬取、个性化邮件制作、自动化发送及追踪分析。AI生成的钓鱼邮件效率高且成本低,成功率甚至超过人类专家。AI画像技巧出色,真阳性检出率高达97.25%,但需注意提示词注入和越狱问题。未来研究将扩大规模并探索用户行为模式以增强防御策略。



