
阿里开源QwenLong-L1:首个以强化学习训练的长上下文推理大模型
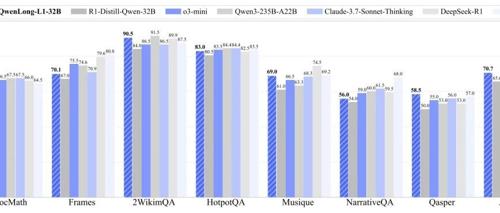
阿里开源的QwenLong-L1框架通过强化学习训练提升了长文本情境推理能力,优于OpenAI-o3-mini等旗舰LRMs,在七个长上下文DocQA基准上表现优异。
阿里开源的QwenLong-L1框架通过强化学习训练提升了长文本情境推理能力,优于OpenAI-o3-mini等旗舰LRMs,在七个长上下文DocQA基准上表现优异。

特斯拉展示了擎天柱机器人通过强化学习在模拟环境中训练并实现‘零样本迁移’的最新成果。这次演示展示了机器人能够在真实世界中成功执行复杂动作,省去了大量调试时间和成本。

Andrej Karpathy提出LLM学习中缺失的环节是’系统提示词学习’。他认为人类的学习更多是通过明确的语言记住解决问题的方法,而非零散的记忆。Karpathy还分析了Claude系统的惊人提示词内容及其潜在应用价值。

阿里通义Lab提出的ZEROSEARCH是首个无需与真实搜索引擎交互的强化学习框架,旨在激励语言模型提升搜索能力。

微软副总裁 Nando de Freitas 提出 AI 是一场系统性工程的观点,反对单一技术的过度宣传。他认为AI的进步需要成千上万人的共同努力,并强调了多元参与和技术探索的重要性。
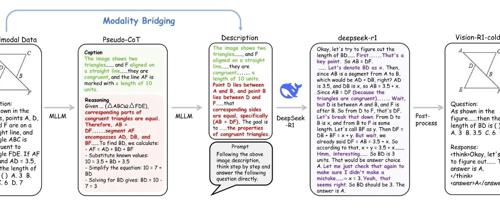
Vision-R1项目通过两阶段策略解决了多模态推理数据稀缺的问题,提出冷启动初始化和RL训练方案,并创新性地引入PTST策略和HFRRF奖励函数,显著提升了模型在多个数学推理基准测试中的表现。

来自加州伯克利大学的研究团队以极低的成本(低于30美元)成功复现了DeepSeek R1-Zero的关键技术,并在‘倒计时’游戏中展示了小型语言模型的强大自验证和搜索能力。