

DeepSeek满血微调秘籍开源了

DeepSeek-R1开源满血版工具链,Colossal-AI团队将6710亿参数的大模型驯化为开发者私有化模型,降低硬件需求和成本,标志着AI竞争正式进入’场景深水区’。
最大参数 300 亿!阶跃星辰与吉利联合开源两款多模态大模型

吉利汽车集团与阶跃星辰联合宣布,将Step系列多模态大模型向全球开发者开源。包括参数量最大的视频生成模型和首款语音交互大模型。阶跃Step-Video-T2V可直接生成高质量视频,而阶跃Step-Audio是业内首个产品级的开源语音交互模型。
OpenAI 前员工们大闹硅谷!离职 CTO 卷走大半骨干创业、联创公开 37 页训练 PPT,还有现员工准备出走

Mira Murati 离职 OpenAI 后创立新公司 Thinking Machines Lab,目标是打造能让更多人理解和使用的 AI 系统。该公司由前 OpenAI、DeepMind 和谷歌员工组成,Murati 表示将公开发布技术研究和代码。

中国高温超导新突破登Nature,薛其坤院士领衔,南方科大成果
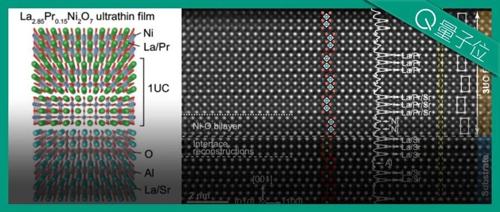
南方科技大学薛其坤院士团队最新研究成果首次让镍基化合物突破麦克米兰极限,实现优异层状生长的超导体。平均年龄仅28岁的年轻团队开发出一种精确控制原子层次的逐原子层生长方法。

Kimi新论文再次“撞车”DeepSeek,都谈到了长文注意力机制

Kimi研究团队提出的MoBA注意力机制显著提升了处理1M和10M长文本的速度,相比传统方法快了6.5倍和16倍。MoBA通过将上下文划分为块,并采用参数无关的top-k门控机制选择最相关的块来高效处理长序列数据。

DeepSeek新注意力机制引热议!梁文锋亲自提交预印本,目标明确降低计算成本

DeepSeek提出NSA稀疏注意力机制,显著降低大模型训练成本。实验表明,在64k上下文时,NSA前向传播速度最高提升9倍,反向传播速度提升6倍,解码速度提升11.6倍。论文已在arXiv上发布,梁文锋等DeepSeek原班人马参与。