
7G显存,训练自己的DeepSeek-R1,GRPO资源暴降80%

Unsloth AI 提供了 GRPO 训练算法,使用户能够在仅 7GB VRAM 上重现 DeepSeek R1-Zero 的‘顿悟时刻’,相比传统方法减少约80%的 VRAM 使用量。
Unsloth AI 提供了 GRPO 训练算法,使用户能够在仅 7GB VRAM 上重现 DeepSeek R1-Zero 的‘顿悟时刻’,相比传统方法减少约80%的 VRAM 使用量。
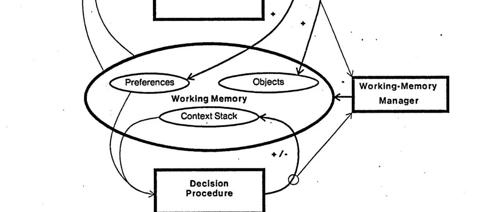
文章探讨了人工智能中的记忆议题,包括SOAR架构、长短期记忆类型、生成式智能体的记忆应用以及AI对人类记忆的影响等,并指出当前在技术实现上仍存在局限性。

再次发表了一篇 2000 多字的“小作文”,其核心观点总结起来就是:
AI 模型的智能大致相当于其训

北京航空航天大学团队发布小尺寸简易视频理解框架TinyLLaVA-Video,其参数量不超过4B,在多个视频理解基准上优于7B以上模型。该项目开源模型权重、训练代码和数据集,并支持模块化设计和自定义训练策略,降低研究门槛。

哈工大深圳、鹏城实验室和昆士兰大学合作提出了一种极性感知线性自注意力机制(Polarity-aware Linear Attention),解决了现有方法在保证注意力分数正值性时会忽视掉 Q,K 矩阵中的负值元素的问题,并在多个视觉任务上取得了精度与效率的平衡。

文章介绍了DeepSeek-R1在多种场景下的应用案例,包括办公软件接入、文档处理、商品名称生成、文案写作和AI算命等。飞书通过整合DeepSeek-R1实现了便捷高效的多任务处理,并分享了使用教程。



