
小红书hi lab首次开源文本大模型,训练资源不到Qwen2.5 72B 的四分之一

小红书 hi lab 发布开源文本大模型 dots.llm1,参数量为 1420亿(142B),上下文长度32K。采用轻量级数据处理流程和MoE架构训练,相比Qwen2.5-72B在预训练阶段仅需13万GPU小时。支持多轮对话、知识理解与问答等任务,在多个测试中表现突出。
小红书 hi lab 发布开源文本大模型 dots.llm1,参数量为 1420亿(142B),上下文长度32K。采用轻量级数据处理流程和MoE架构训练,相比Qwen2.5-72B在预训练阶段仅需13万GPU小时。支持多轮对话、知识理解与问答等任务,在多个测试中表现突出。

DeepSeek即将发布的新一代模型R2参数翻倍且成本下降88%,具备更强的语言推理和代码生成能力、更高的推理效率及多模态支持。不过,根据摩根士丹利的报告,真正的R2模型还需等待进一步更新。

领英联合创始人里德·霍夫曼提出以AI为‘放大人类行动力’工具的观点,强调技术与人类共生。书中探讨超级能动性、技术人文主义原则及技术部署策略,呼吁构建开放共享的技术生态系统。

马上消费常务副总经理蒋宁在2025消费金融生态大会上发布升级后的金融大模型“天镜”3.0,强调其从个体智慧到群体智慧的系统性突破。该模型覆盖了智能营销交互、数据决策支持等八大应用场景,并具备协同进化能力。
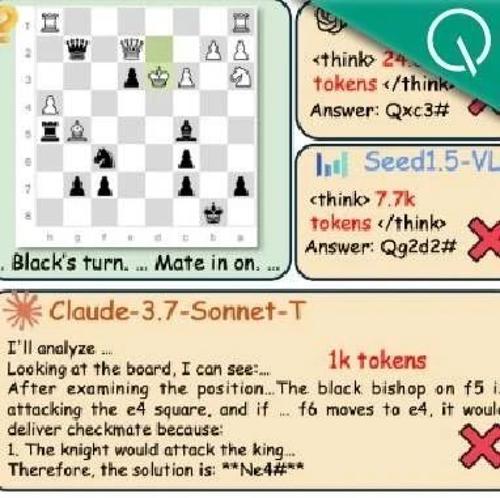
复旦大学及香港中文大学MMLab联合上海人工智能实验室等多家单位提出了MME-Reasoning,全面评估多模态大模型的推理能力。该基准分为三类推理:演绎、归纳和溯因,并涵盖三种问题类型。评测结果显示当前最优模型得分仅60%左右,显示了对逻辑推理能力的要求极高。

一项新研究表明,大模型在在线辩论中比人类更具说服力。该研究指出,在了解对手个人信息的情况下,使用GPT-4的参与者有更高的概率改变观点。研究还显示,大模型写作风格具有显著特征,易被察觉。专家呼吁加强监管,防止大模型用于操纵舆论。

研究团队提出VL-Rethinker模型,通过优势样本回放和强制反思技术解决多模态推理中的优势消失和反思惰性问题。该模型在多个数学和科学任务上超过GPT-o1,并显著提升Qwen2.5-VL-72B在MathVista和MathVerse上的性能。


