

©PaperWeekly 原创 · 作者 | 张逸骅
单位 | 密歇根州立大学博士生
研究方向 | 可信人工智能

开篇

只有Reward时的朴素做法:为什么会有问题
-
不公平:如果弟弟从 30 分进步到 60 分,付出了非常大的努力,却依然比不过我平时随便考个 80+。他得不到有效激励。 -
不稳定:我为了冲刺高分,可能会采取极端学习策略(比如疯狂刷题、考前通宵),偶尔考到 95 分,偶尔只有 60 分,成绩大起大落,导致奖励信号也忽上忽下。
数学对应
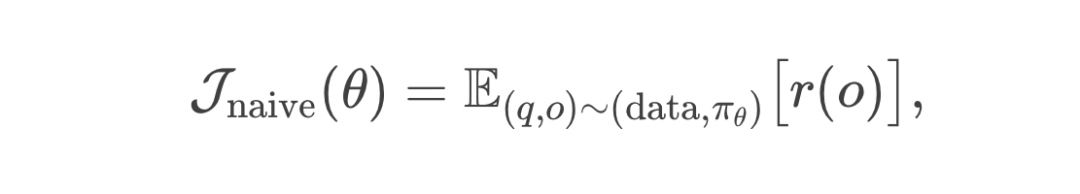

引入 Critic:用“预期分数线”来改善奖励机制
-
给我定一个“预期分数线” 80 分;给弟弟定一个“预期分数线” 40 分。考试时,只要超出自己那条线,就能得到更多零花钱;如果没有超出,那么零花钱就可能很少或者没有。
数学对应



加入 Clip 与 min 操作:防止更新过度
-
如果某一次考试我突然爆发,进了高分段,比如 95 或 100 分,爸爸会给我极高奖励,导致我在下一次考试前可能“走火入魔”,去尝试各种极端学习方法,成绩忽高忽低,奖励也随之剧烈波动。
数学对应


-
我考到 100 分,可以多拿奖励,但爸爸会有个“封顶”的约束;下一次还要观察一下再做决定,这样保持学习的平稳性,防止出现一条极端的“歪路子”。

Reference Model:防止作弊、极端策略
-
“无论如何,你不能偏离最初正常学习的方法太多。否则即使你考了高分,我也判你不合格,零花钱也不给。”
数学对应


GRPO:用“多次模拟成绩平均值”代替价值函数
-
不用“学习”一个单独的价值网络当 Critic; -
而是对同一道题目、同一个状态,先用旧策略采样多条输出,然后把这些输出的平均 Reward 当作 baseline; -
超过平均值就相当于“正向 Advantage”,低于平均值就是“负向 Advantage”。
数学对应
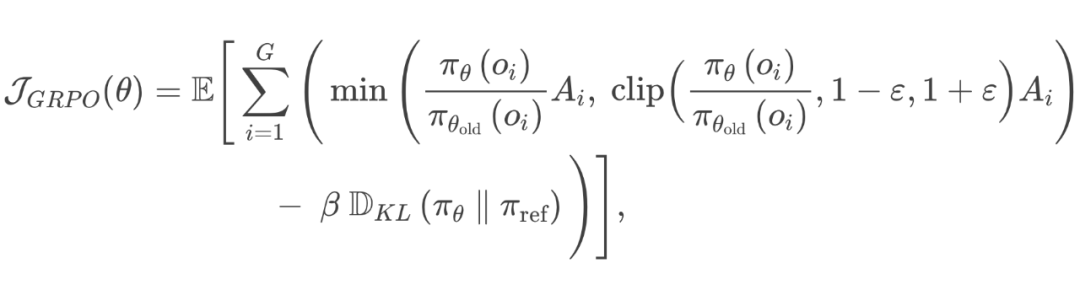
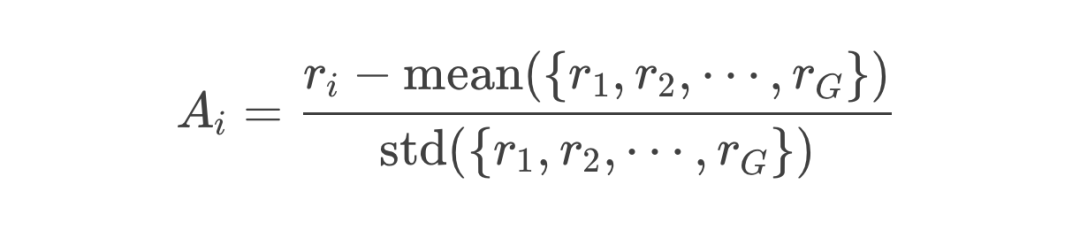

小学每周都考试:多步时序下的新挑战
然而,在真实的学校生活中,考试往往不止一次。想象这样一个情境:
每周一早上,老师都会给我们一张小测验卷子,分值从 0-100 不等;
周一下午爸爸会根据我的测验结果和预期分数线,给我相应的零花钱或惩罚;
周二到周日是我学习、调整策略的时间。比如我要不要去参加补习班?要不要和同学一起自习?还是干脆放飞自我,躺平娱乐?
到了下周一早上,又是一场新测验,继续给分并影响零花钱。如此往复,每周一次考试,一次接着一次地进行。
7.1 单步 vs. 多步:新的困惑
-
以前,爸爸只需要在“一次考试”后,评估我的表现是否超出预期,就可以立刻给零花钱,或者在下次测试前稍微修正一下我的分数线(Critic)。 -
现在,每周都有考试,但我下一周的表现,往往也受“这周考完之后做了哪些学习动作”影响。比如这周我选择“熬夜狂刷题”,可能下周突然身体疲惫、精力有限,反而成绩下滑;反之,如果这周我适度学习,下周可能能稳定发挥。 -
更复杂的是,我是不是要做一个长期的规划?可能我前两周稍微放松,第三周再发力冲刺,结果对期末大考更有帮助…… 在强化学习术语里,这已经是一种多步时序决策问题。我们需要照顾到一段时间内的累积表现,而非单一考试。
-
在小学考试隐喻中,可以想象“策略”就是我的总体学习方法或“选课思路”,它会根据我当前的状态(比如疲惫程度、最近分数波动、是否遇到难点等),来决定本周要不要补习、要不要放空休息、或者做别的准备。
-
动作 就是这周具体采取的学习计划。而策略 则是那个“生成动作”的整体函数或分布。策略越好,就越能在各周做出恰当决策,从而累积更高的长期分数(Reward)。

为了多步时序:TD 残差与 GAE 再登场
8.1 什么是TD(Temporal Difference)残差?
-
我当前的学习水平、疲劳程度、对下一次考试范围的掌握度; -
我上一场考试的得分; -
甚至我当前的心情(如果要更真实的话……)。
TD 残差(Temporal Difference Error)就是对“本周价值估计”和“下周实际得到奖励+下周价值估计”之间的差异做一个衡量。形式如下:
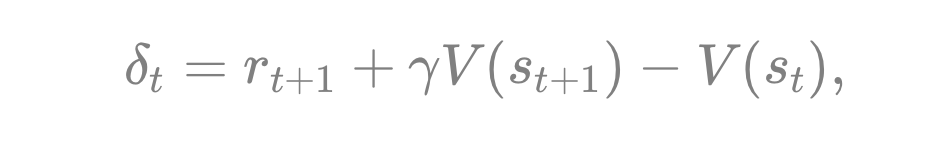
-
小学考试的比喻里,可以理解为:“我原本觉得本周(状态 )能至少考到 80 分,结果实际只有 75 分,下周又觉得能稳 78 分,所以和最初的期望值一比,发现差了几分。” 它直观反映:“我原先以为本周能拿多少分,加上下周的未来潜力;和实际看到的成绩与未来估计相比,相差多少?”
-
如果 为正,说明“比预期更好”;如果为负,说明“还得多加努力”。
8.2 什么是 GAE?为什么需要它?
问题:如果我们只用单步的 TD 残差,就相当于“每次只看一周后的考试成绩 + 对下一周的估计”,这样做数据更新非常快,方差也可能较小;但有时候会忽略更远期的后果。比如,我本周过度学习,下周的分数也许没崩,但大后周就会累得不行。反之,如果我们用“把所有后续考试的总成绩都算进来”那种蒙特卡洛方法,则要等到很多周过去之后才能总结,这期间的噪声/运气都可能让估计出现超高方差。
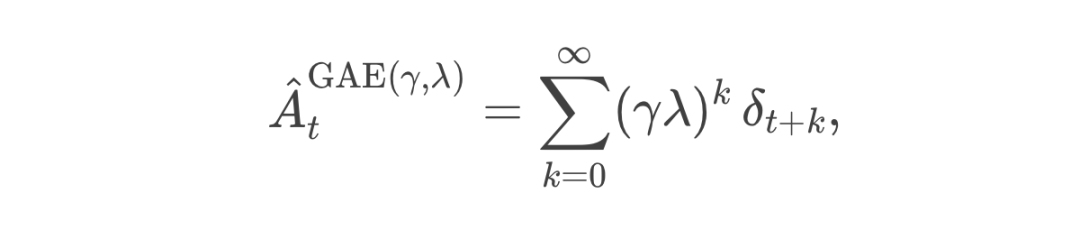

-
当 时,就退化成单步 TD;
-
当 趋向 1 时,就越来越接近全蒙特卡洛估计(当然在实际实现上会有截断)。
比喻拆解
-
:表示“本周 + 下周价值”的偏差; -
:表示“下周 + 下下周价值”的偏差; -
…… -
最终,GAE 把这些多周的差值按衰减系数累加起来,就得到一个对“本周这次决策的 Advantage” 更稳定、更综合的评估。
8.3 GAE 在比喻中的具体意义
-
我(学生)每周都能收到一个基于“上一周考试成绩-预期线”得到的激励,但这个激励也要考虑更远期的趋势——是不是会造成后面几周的成绩起伏? -
爸爸想综合地评估:这周的学习动作,对下周及之后几周的影响都可以稍微看一下,但“越远的影响”越需要衰减地去衡量,不至于把噪声无限放大。 -
这也就解释了为什么只用单步信息会对后几周可能出现的“大跳水”或者“大爆发”视而不见;而全局蒙特卡洛会在多周累积回报上花费太长时间才得到一个结论,还容易出现高方差。

新设定下的价值函数与动作价值函数


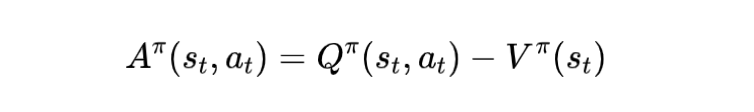

我们到底在用什么 Loss 训练什么?
在 PPO、A3C、GRPO 等常见的策略梯度方法里,背后通常有两部分模型需要训练:
Actor(策略网络):输出每个状态下我选择各个动作的概率,或直接输出一个最优动作。
Critic(价值网络):输出状态价值 (或动作价值),作为基准分数线,让我们更稳定地评估动作好坏。
-
Critic Loss:最常见的是最小均方误差(MSE),让 Critic 的估计 尽量接近我们根据实际反馈(Reward)得到的目标回报。 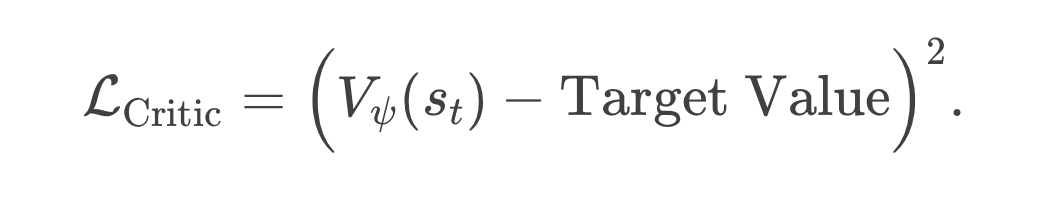
在多周考试里,Target Value 可能是“一步 TD 目标” 或者是更长的回报估计(如 GAE 里累加起来的一部分)。 -
Actor Loss:我们会把优势函数 或其某种近似,乘上 来做梯度上升(或等价的负号做下降)。 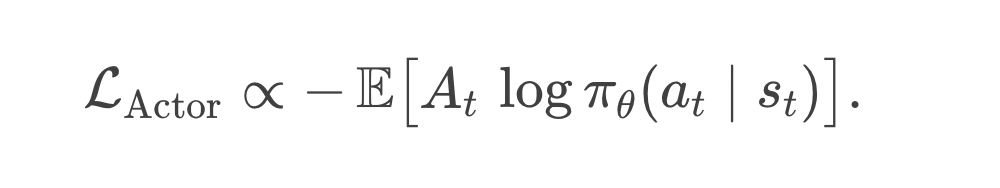
当一个动作在当前状态下的 Advantage 越大(超过分数线越多),就会推动策略朝该动作概率增大的方向更新;反之则相反。
宏观上来看:
-
Actor 就是“我大脑里的决策机制”,不断学着如何选动作。
-
Critic 就像“我的内在预期模型”或“家长给的预期分数线”,不断修正对当前学习状态的评估。
-
最终的 Loss 把这两个部分的误差结合在一起,让二者相辅相成地共同进步。

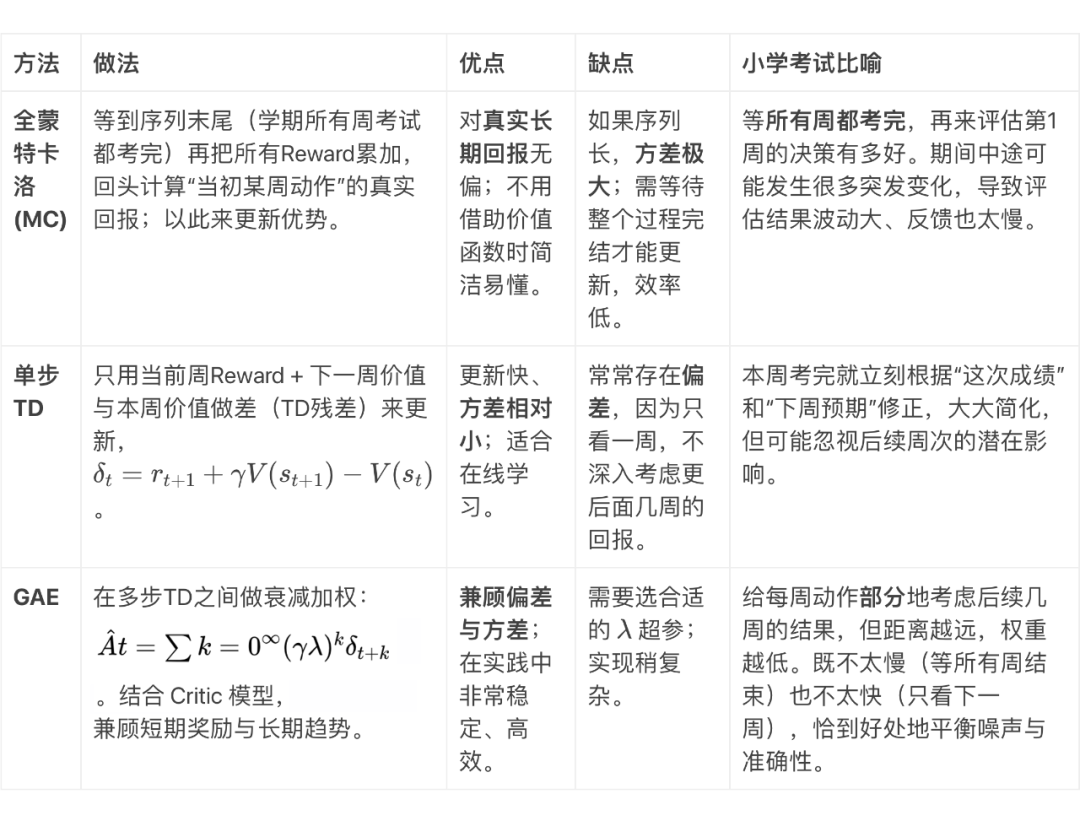
-
全蒙特卡洛: -
做法:等到好几周的考试都考完、算完所有分数加起来,再回来更新“当初第 周决策的好坏”。 -
好处:长期真实的回报都算进去了,不怎么“偏”。 -
坏处:如果有些考试运气成分高,或者弟弟突然生病,这些偶发因素都会让最终分数波动很大,从而在训练时出现超高的估计方差。
-
单步 TD: -
做法:只看“这一周得到的分数 + 对下周的估计”来衡量“本周动作”的好坏。
-
好处:不会因为长远噪声而把评估搞得极不稳定,方差相对较小。
-
坏处:可能忽略后面几周真正的重要影响,估计会产生偏差。
-
GAE: -
做法:综合若干周(由 参数决定),既能考虑到一些后面几周的效果,又不会把非常远期的噪声全部吸收进来。 -
好处:在“减少偏差”与“压低方差”间折衷,训练更高效、稳定。 -
坏处:需要额外的实现/公式来把多步 TD 残差累加、需要选择合适的 超参数。
-
偏差意味着:我们判断某周的决策好坏时,可能过于只看眼前(那就会导致长期效果判断出错)。 -
方差意味着:如果我们判断某周决策好坏时,要把今后所有几周都完全算进去,那在这个漫长过程中,“弟弟突然生病”、“试卷难度随机波动”、“我临时遭遇某些突发事件”等都会影响分数,导致我对本周决策的评估极其不稳定。就像猜不准天气一样,太多干扰因素使估计忽上忽下。

对比三种 Advantage 估计方法

结语:回顾与展望
通过这个小学考试的比喻,我们逐步从只看绝对分数的朴素思路,演化到 PPO 的完整机制(Critic、Advantage、Clip、Reference Model),再到 GRPO 的创新思路(用一组输出的平均得分当基线,省去价值函数的繁琐)。以下几点值得再次强调:
-
Critic 的意义:它为每个状态或阶段提供“合理预期”,大幅降低了训练方差; -
Clip & min 机制:约束策略更新幅度,避免一次考试“爆发”带来的巨幅震荡; -
Reference Model:限制“作弊”或极端行为,让策略不要过度偏离最初合规范围; -
GRPO 的优点:在大型语言模型中,省掉了价值网络,减少内存和计算负担,还与“对比式 Reward Model”天然契合。
-
需要用 TD 残差(Temporal Difference)来衡量“实际回报”和“之前对价值的估计”之差; -
为了更好地估计 Advantage,既不想只用单步 TD,也不想全靠蒙特卡洛,“GAE(Generalized Advantage Estimation)”应运而生; -
它通过对多步 TD 残差进行衰减累加,提供了一个兼顾偏差与方差的折衷方案; -
状态价值函数 与动作价值函数 的定义也要放到时序多步的语境下去;在每周进行一次学习决策、每周获得一个奖励,形成了更丰富也更复杂的训练过程。
(文:PaperWeekly)