
今天是2025年02月24日,星期一,北京,天气晴。
我们昨天谈了eepseek R1针对think这个过程的误区,不从基本技术逻辑出发。其也带来一个思考,即一个模型出来其是带着它的特点来的,而为了上而上,而让它丢掉其原有特性去强制适应一些不合它设定的任务,这会失去使用它的意义。这个是大家需要意识到的。
今天,我们来看看一些有趣的话题,一个是最近社区中有个关于mobile agent的一个思考。
另一个,看看开源的一些进展,包括MoE小模型Moonlight-16B-A3B、Qwen2.5-VL以及deepseek开源周day1开源FlashMLA。也包括RAG用于综述写作的工作重点看文配图部分。
专题化,体系化,会有更多深度思考。大家一起加油。
一、关于mobile agent的一些思考
目前智谱,阿里等厂商,都在以点餐作为场景去看手机端agent 上的一些场景,但一直觉得这种场景是伪命题。例如http://www.damoai.com.cn/archives/8073中所提到的,其在采购火锅食材的例子中,AutoGLM自主执行了54步无打断操作,AutoGLM能够支持长任务的自定义短语。不用再给AutoGLM说:“帮我买一杯瑞幸咖啡,生椰拿铁,五道口店,大杯、热、微糖” 这类超长指令,只需要说“点咖啡”。

这个的核心在于,大模型的推理规划能力,以及对屏幕的多模态处理能力,这个是根本,例如微软的OmniParser系列(微软开发的一款AI工具,将图形用户界面(GUI)截图转换为结构化数据,可以增强大模型(LLMs)与屏幕上视觉元素的互动),就是做这个事情的,这块可以参考一些博客,https://zhuanlan.zhihu.com/p/24590537352。
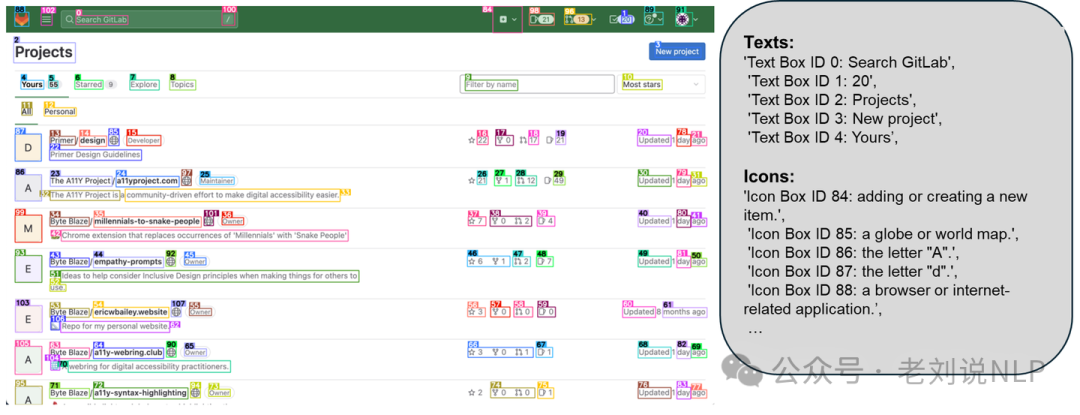
关于OmniParser,可以看:https://huggingface.co/microsoft/OmniParser-v2.0,https://huggingface.co/spaces/microsoft/OmniParser-v2,httpps://www.microsoft.com/en-us/research/articles/omniparser-v2-turning-any-llm-into-a-computer-use-agent/。
OmniParser可以支持来自多个平台的截图,包括Windows和移动设备。它能够生成UI元素的结构化表示,详细描述可点击区域及其功能。
但是呢,我们从用户的这个角度上来看,又会有不一样的发现:
我们去购物,去卖东西,去买东西,这种过程,体验,乐趣正是生活的一个部分,这也是现在直播带货能活的一个原因之一。但用agent去帮我们去做的时候,这种乐趣被被剥夺了。并且,当跟我们对接的那一方是个机器的时候,也着实会有些无语,例如给你打电话,有太多一听就是机器人。
所以,agent那些,用在点餐那些,其实,用错了场景。如何让人类更有乐趣的浪费时间,过好一天24h,才是方向。而不是剥夺人类本身就少得可怜的乐趣时间,让人类有更多的枯燥时间去做其他少乐趣的事儿。
也就是说,让AI帮人类处理垃圾时间,这个往往会更好些。让人没有感知到AI的AI产品才是好AI产品。
二、看最近一些前沿的开源进展
1、MoonshotAI发布MoE小模型Moonlight-16B-A3B
激活参数为3B,项目地址:https://github.com/MoonshotAI/Moonlight, 模型地址:huggingface.co/moonshotai/Moonlight-16B-A3B。

Muon训练的3B/16B参数混合专家(MoE)模型,训练时使用了5.7T个token,确定了两种扩展Muon的关键技术:添加权重衰减和调整每个参数的更新比例,缩放定律实验表明,与AdamW相比,Muon在计算最佳训练方面实现了约2倍的计算效率。
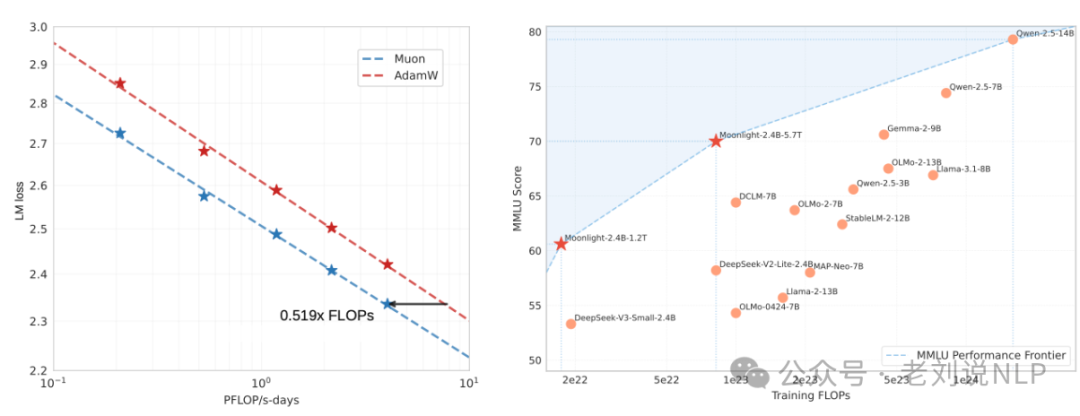
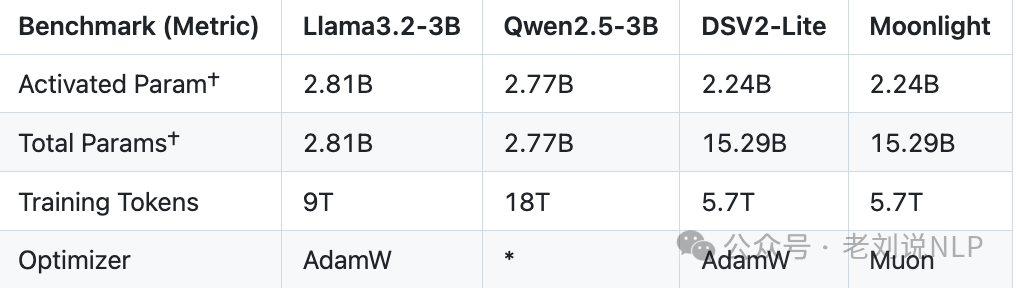
还有个看点,就是其与其他大模型的对比,如下:LLAMA3-3B使用9Ttoken训练的3B参数模型;Qwen2.5-3B是一个使用18Ttoken训练的3B参数密集模型;Deepseek-v2-Lite是一个使用5.7T个token进行训练的2.4B/16B参数MOE模型;
2、多模态进展,Qwen2.5-VL开源
多模态方面,Qwen2.5-VL Technical Report(https://arxiv.org/pdf/2502.13923)发布 ,采用原生动态分辨率处理、绝对时间编码 MRoPE 和高效ViT架构。
Qwen2.5-VL采用视觉编码器和语言模型解码器的集成,用于处理多模态输入,包括图像和视频。视觉编码器旨在以输入的原始分辨率处理输入,并支持动态帧率(FPS)采样。不同大小的图像和不同帧率的视频帧被动态映射为不同长度的标记序列。
MRoPE(Multi-Rotation Position Embedding)在时间维度上将时间ID与绝对时间对齐,使模型能够更好地理解时间动态,例如事件的节奏和精确时刻定位。处理后的视觉数据随后被输入到Qwen2.5语言模型解码器中。我们对视觉变换器(ViT)架构进行了重新设计,引入了先进的组件,如带有SwiGLU激活函数的前馈网络(FFN)、用于归一化的RMSNorm和基于窗口的注意力机制,以提升性能和效率。
地址在:https://chat.qwenlm.ai,https://huggingface.co/Qwen,https://modelscope.cn/organization/qwen,https://github.com/QwenLM/Qwen2.5-VL
3、deepseek开源周day1开源FlashMLA
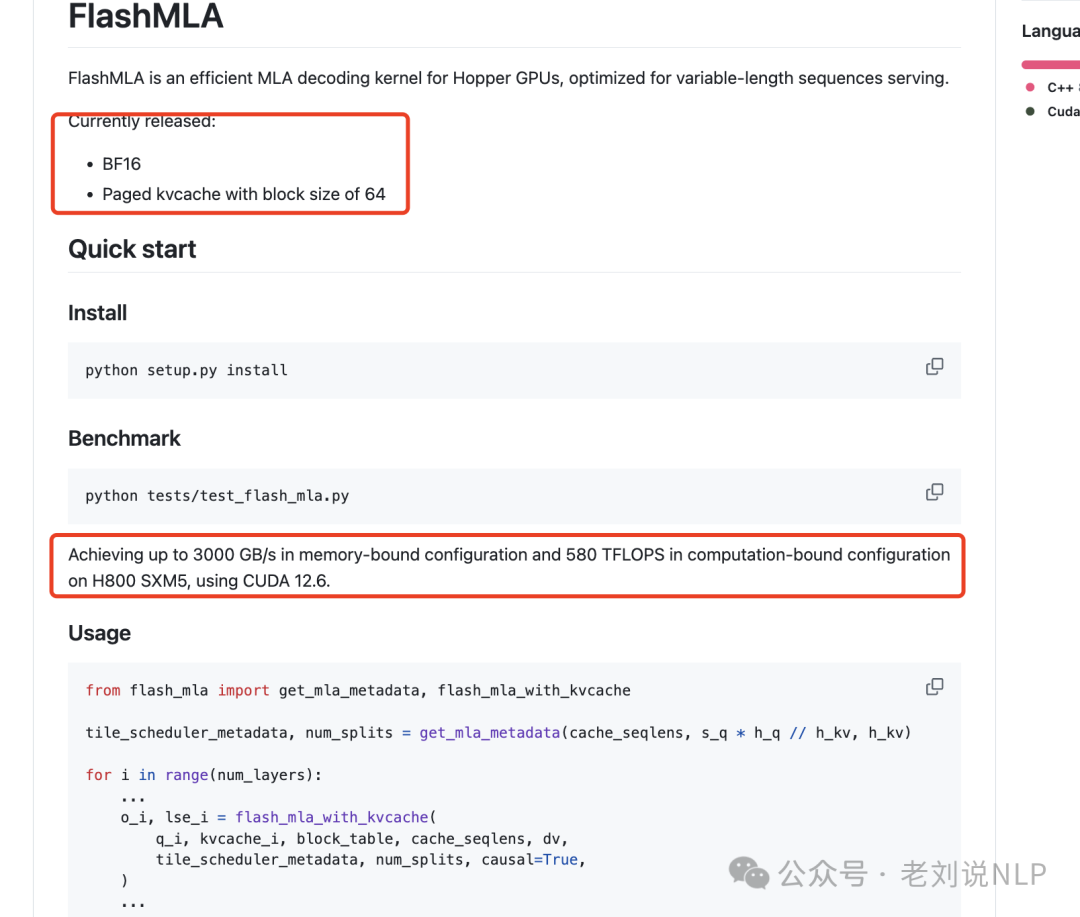
FlashMLA是适用于HopperGPU的高效MLA解码内核,针对可变长度序列服务进行了优化。目前发布BF16、块大小为64的分页kvcache,使用CUDA12.6,在H800SXM5上,在内存绑定配置下实现高达3000GB/s,在计算绑定配置下实现580TFLOPS。
地址在:https://github.com/deepseek-ai/FlashMLA
4、RAG 用于写作场景进展
SurveyX-全自动化学术综述生成,SurveyX: Academic Survey Automation via Large Language Models,https://huggingface.co/papers/2502.14776,https://github.com/IAAR-Shanghai/SurveyX,一个基于大模型的全自动学术综述论文生成系统,只需提供标题和关键词,便可高效检索文献并生成学术综述论文,其中可以重点关注的点,是图表生成能力。
这块是难点。如何做到一致性。这个点在的步骤包括两个,首先是多模态图片生成,SurveyX利用多模态大模型的能力,从参考文献中检索与文章叙述高度相关的插图,进一步增强文章的表现力与说服力。然后是模板化的图表生成,SurveyX提取文章中的关键信息,结合预定义的图表模板代码,自动生成定制化的图片与表格并插入文中,使文章内容更加直观且富有表现力。
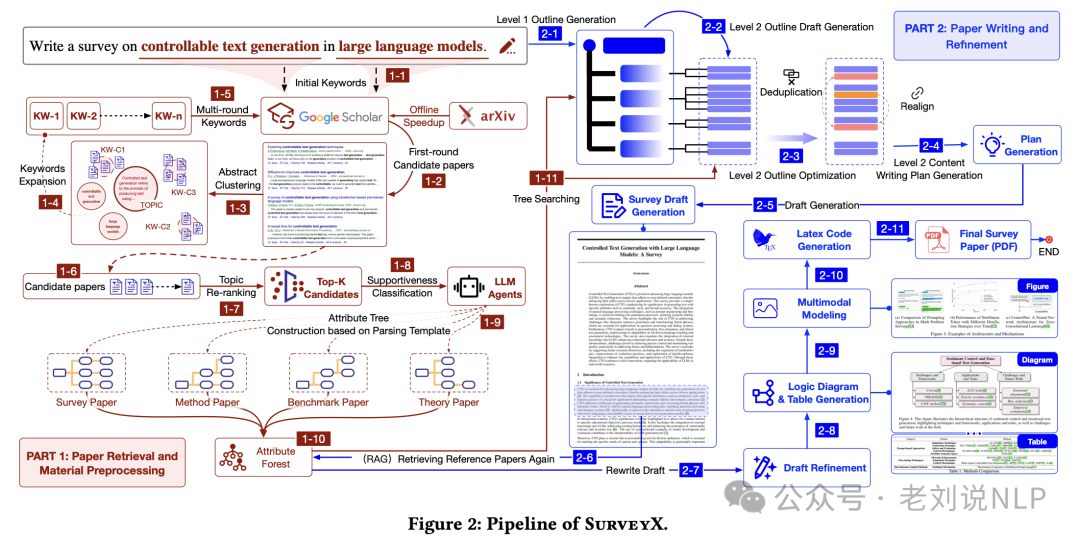
此外,再回顾下其整体生成逻辑,首先是在撰写综述初稿时,SurveyX首先让LLM基于属性树分析当前行文,总结下一步的写作方向与所需信息,并将其存储为Hint。这种机制使LLM在实际写作时能够生成更有组织性和逻辑性的内容。然后是进行大纲,针对普通LLM生成大纲冗余的问题,SurveyX采用先生成一二级大纲,再对二级大纲进行去冗余与重排的策略,最终生成简洁清晰、逻辑性强的大纲,为综述论文的撰写提供坚实的框架基础。最后是RAG重写优化,初稿生成后,SurveyX通过RAG模块对文中所有引用进行验证与重写,确保引用的准确性与可靠性,从而提升文章的可信度与学术严谨性。
参考文献
1、https://github.com/deepseek-ai/FlashMLA
2、https://github.com/QwenLM/Qwen2.5-VL
3、https://github.com/MoonshotAI/Moonlight
4、https://huggingface.co/microsoft/OmniParser-v2.0
(文:老刘说NLP)